2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
雷锋网 AI 科技评论按:每月《Computer Vision News》都会选择一篇关于计算机视觉领域研究成果的论文进行回顾。今年三月份,他们选择了由 Yossi Gandelsman,Assaf Shocher 和 Michal Irani 三位学者(下文中所提到的作者,均指以上三位学者)共同完成的关于 Double-DIP 模型的论文,其中详细介绍了基于耦合的深度图像先验网络对单个图像进行无监督层分割这一技术。

概况
许多看似无关的计算机视觉任务可以被视为图像分割为不同的层的特殊情况。举两个突出的例子:图像分割——分割成背景层和前景层的区域;图像去雾——分割为清晰图层和有雾图层。在该论文中,作者提出了一种基于耦合的「深度图像先验」(DIP)网络对单个图像进行无监督层分割的统一框架。
被 CVPR 2018 会议接收的深度图像先验(DIP)网络,是一种可以用来对单个图像的低级统计数据进行生成的结构,而且只需要在单张图像上进行训练。而在论文中,作者向我们展示了如何通过耦合多个 DIP 网络得到一个强大的工具,来将图像分割为其基本组成,从而使其适用于各类任务。正因为所得数据来自于混合层的内部,相比其各个组成部分的数据更复杂且更具代表性,这使其多功能适用性具有实现的可能。作者们认为,模型能胜任多种任务的原因是,相比于在不同的层上各自进行,多种不同的层的内部统计特性更为鲁棒,也有更好的表征能力。
作者向我们展示了该方法在各类计算机视觉任务上的运用,比如:水印去除,前景/背景分割,图像去雾以及视频中的透明度分离等。在没有提供任何额外数据的情况下,只需要在单张图像上进行训练,就可以完成以上所有的任务。
关于「图像分割的统一框架」
由三个不同任务重新定义的原图分割,可以视为简单基本层的混合,如下图所示,图像分割、图像去雾、透明度分离这三种任务都可以看作是,先把原始图像拆分成一些基本层,然后再把这些层重新混合。
这种方法将图像分割成若干基本层,并提供一个统一的框架来对大量明显不同且无关的计算机视觉任务进行处理。所有这些图像分割的共同点是每个单独层内小块的分布比「混合」图像(即原始图像)更「简单」(均匀),从而导致每个单独层的内部相似性很强。已有研究证明小图像块(例如 5×5,7×7)的统计特征(分布)在自然图像中极具重复性,所以这种强内部重复性,可以很好的用于处理各种计算机视觉任务。
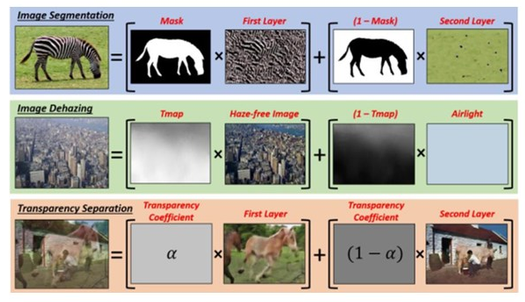
图1 图像分割的统一框架
作者的方法结合内部补丁重现,即小块图像的重复出现的特性(无需监督即可解决任务的能力)和深度学习的强大力量,提出了一种基于 DIP 网络的无监督框架。当 DIP 网络的输入是随机噪声时,它也能学会重建单个图像(该图像作为训练的唯一输入)时,单个 DIP 网络被证明可以很好的捕获单个自然图像的低级统计数据。这个网络还被证实在无监督情况下,完全能够解决如:去噪,超分辨率和修复等问题。
图像分割基本原理
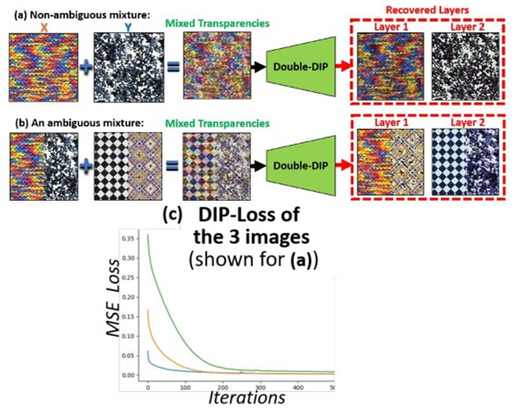
图2 图像分割基本原理
图 2 向我们说明了该方法的基本原理。它展示了如何利用 X 和 Y 两个图案,来混合产生新的更复杂的图像 Z。每个「纯」图案(X 和 Y)的小图像块的分布相比混合图像 Z 小图像块的分布更简单。众所周知,如果 X 和 y 是两个独立的随机变量,那么它们的和 Z = X + Y 的熵大于它们各自的熵。
图 2 的损失函数图还向我们详细展示了单个 DIP 网络作为时间函数(训练迭代)时的 MSE 重建损失。对于图中的 3 条线:(i)橙色是训练重建纹理图像 X 的 MSE 损失;(ii)蓝色是训练重建纹理 Y 的 MSE 损失;(iii)绿色是训练重建纹理图像 X+Y 的 MSE 损失。可以发现,MSE 损失值越大时,收敛时间越长。而且,混合图像的 MSE 损失值不仅大于两个单独图像的 MSE 损失值,实际上,还大于两个单独图像 MSE 损失值的总和。
为了证明这个现象不是偶然,作者从 BSD100 数据集(为了防止自然图像与规则图案间有差异)中随机选择了 100 对自然图像来重复该实验。而结果证明,混合图像与合成图像组之间 MSE 损失值的差值甚至更高。
图像分割工作模型
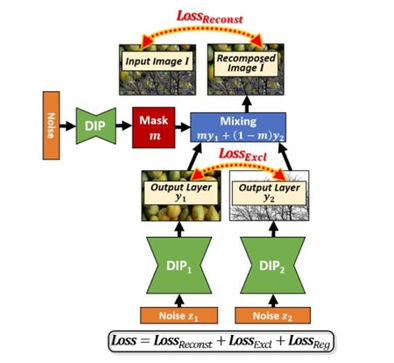
图3 图像分割工作模型
图 3 详细说明了 Double-DIP 对图像进行分割时的工作模型。两个深度图像先验(DIP)网络(DIP1 DIP2)将输入图像分割成对应的图像层(y1&y2),然后根据二进制掩模 m(x)进行重组,以形成尽可能接近于输入图像本身的重建图像 I。
什么样的分割是好的图像分割?有很多方法可以将其分割为基本图层,但作者提出有意义的分割应该满足这样几个标准:
重新组合时,恢复的图层能够重建输入图像
每层应该尽可能「简单」,即它应该具有很强的图像元素内部自相似性
恢复的图层之间彼此独立
这三个标准也是 Double-DIP 网络需要具体实现的参考。第一个标准通过最小化重建损失(衡量构造图像和输入图像之间的误差的参数)来实现;第二个标准通过采用多个 DIP(每层一个)实现;第三个标准由不同 DIP 的输出间的「不相容损失」强制执行(最小化它们的相关性)。
每个 DIP 网络重建输入图像 I 的不同图层 yi;每个 DIPi 的输入是随机采样的均匀噪声 zi; 使用权重掩模 m(x) 混合 DIP 输出 yi = DIPi(zi),从而生成重建图像:
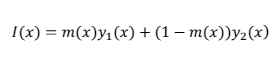
其应尽可能接近输入图像 I。
对于某些任务中,权重掩模 m 非常简单,而在其他情况下则需要进行学习(使用附加 DIP 网络)。学习的掩模 m 可以是均匀的或空间变化的,连续的或二进制的。对 m 的约束条件与任务相关联,并且使用指定任务的「正则化损失」来强制执行。因此优化损失是:
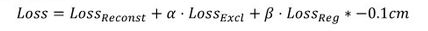
关于 Double-DIP 网络的训练和优化类似于基本 DIP。而在输入噪声中,增加额外的非恒定噪声扰动可以增加重建的稳定性。通过使用 8 个变换(4 个旋转 90°和 2 个镜像反射 - 垂直和水平)转换输入图像 I 和所有 DIP 的相应随机噪声输入,可以进一步丰富训练集。
优化过程使用到了 ADAM 优化器,而每张图片在 Tesla V100 GPU 上仅需要几分钟来完成。
研究成果
论文内提到的多个成果中,我们在下文中着重讨论:
1)前景/背景分割
2)水印去除
前景/背景分割
我们可以设想将图像分割成前景和背景区域,前景层为 y1,背景层为 y2,对于每个像素根据二进制掩模 m(x)进行组合,得到:
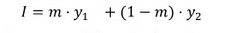
这个公式非常适合文中所提到的框架,它将「好的图像片段」定义为易于通过自身合成,但很难使用图像其他部分进行合成这个概念。为了使分割掩码 m(x)变为二进制,我们使用以下正则化损失:
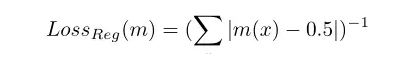
Double-DIP 能够基于无监督的层分割获得高质量的分割,如图 4 所示,更多图像分割结果可以在该项目的网站上进行观看。尽管有许多其他分割方法(其中包括语义分割)的表现甚至比 DIP 要好,然而它们都有一个的缺点——需要用大量的数据训练。

图 4 图像分割实例
水印去除
水印广泛用于保护受版权保护的图像和视频。Double-DIP 能够将水印作为图像反射的特殊情况来进行去除,其中图层 y1 和图层 y2 是分别是清理后的图像和水印。
和图像分割不同,在这种情况下,掩模没有被明确设置,而是使用两种实际解决方案之一来处理固有的透明层模糊性。如果仅涉及单个水印,则用户通过带有边界框来标记水印区域;而当有少量图像具有相同的水印时(通常 2-3 张图像),在训练过程中将由模糊性原则自行处理。图 5 为一些水印去除的实例:

图 5 水印去除实例
结论
「Double-DIP」为无监督层分割的提供了统一的框架,这个框架可以适用于各种各样的任务。除了输入图像/视频之外,它不需要任何其它训练数据。尽管这是一种通用的方法,但在某些任务中(如去雾),它所得到的结果可以与该领域的最先进的专业技术效果相当或甚至更好。该论文的作者认为,用语义/感知线索增强 Double-DIP 可能会使得语义分割和其他高级计算机视觉任务方面的进步,在接下来的工作中,他们也打算对这个方面做进一步的研究。
雷锋网(公众号:雷锋网) AI 科技评论将相关链接整理如下:
原论文地址
https://arxiv.org/abs/1812.00467
杂志原文地址
https://www.rsipvision.com/ComputerVisionNews-2019May/4/
雷锋网AI 科技评论

