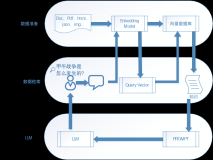
一、背景
7月7日,阿里云在2023世界人工智能大会上宣布,AI绘画创作大模型通义万相开启定向邀测。通义万相是阿里云“通义”大模型系列第三个产品,此前的通义千问、通义听悟分别具备文字问答和语音文字处理的功能。

目前该模型已经开启定向邀测,网址:通义万相 (aliyun.com)
二、产品体验
这次产品发布无疑给我带来了非常多的好奇与激动,所以发布会结束之后我立刻就去体验了这款产品。
通义万相首批上线3大能力分别是文生图、相似图像生成、图像风格迁移。
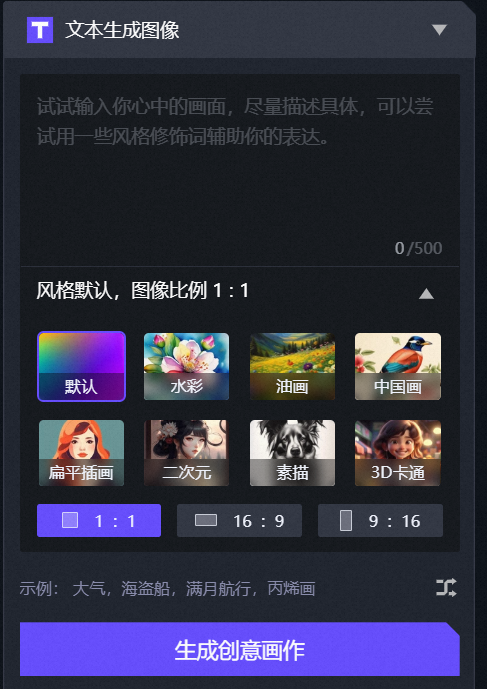
1.文生图
文生图页面左侧有一个简洁的界面,上方有一个文本输入框,在输入框内可以输入prompt。文本框下方提供8个可选的画面风格(水彩、油画、中国画、扁平插画、二次元、素描、3D卡通等)以及生成按钮。


图丨左:水彩风格的夜晚的海滩,月光洒在波澜壮阔的海面上;右:默认风格的夜晚的海滩,月光洒在波澜壮阔的海面上(来源:通义万相生成)
常规景色下万相的表现非常优秀。图中的海面波光粼粼,月光洒在海滩上,给人一种宁静祥和的感觉。左侧水彩图片的色彩饱满,绘画效果非常逼真;而右侧默认风格的海滩让人仿佛置身于夜晚的海滩中!


图丨左:油画风格的咖喱蛋包饭;右:3D卡通风格的咖喱蛋包饭(来源:通义万相生成)
针对美食类图像,万相的表现也相当不错。图中油画风格的蛋包饭色彩鲜艳,让人非常有食欲,而卡通风格的蛋包饭图像细节处理很到位,并且远景也值得称赞!


图丨左:中国画风格的冬天的梅花;右:扁平插画风格的冬天的梅花(来源:通义万相生成)
生成的中国画效果的梅花实打实的惊艳到了我,让我一度误以为是哪一古画上的截图!而插画风格的冬天梅花无论是构图还是风格都让人赞叹。
接下来让我们看看终极挑战:当万相面对我们拥有文化内蕴的古诗词时,它将如何表现呢?


图:采菊东篱下,悠然见南山丨左:默认风格;右:中国画风格(来源:通义万相生成)


图:执子之手,与子偕老丨左:默认风格;右:中国画风格(来源:通义万相生成)
在遇到描写景物的诗句时,万相生成的图片能够精准捕捉诗句中关键信息点,例如‘采菊东篱下,悠然见南山’中的菊花以及高山。所生成的中国画风格的图片还带有一丝悠然田园的意境。
然而在面对一些抽象的古诗词时,模型的表现就不太稳定了。例如‘执子之手,与子偕老’一句中,原是指战士之间的约定,曾经在一起发过誓,一同生死不分离。现代常常形容爱情的永恒。而万相所生成的默认风格图像似乎只能捕捉一些关键信息,并不能理解诗句的含义,素描风格比较贴合。但是风格受限。
2.相似图像生成
相似图像生成的界面支持上传不超过10M的jpg、jpeg、png、bmp图片。点击生成按钮,右侧生成4张相似图片可供下载。


图丨左:原图;右:相似图像生成(来源:通义万相生成)
左侧我们输入一张猫咪图片,万相生成的图片把猫咪的毛发纹路,特色都得以保留,让人觉得是同一个画手所画出的。


图丨左:原图;右:相似图像生成(来源:通义万相生成)
输入美食图片,生成的相似图简直达到了以假乱真的地步。相似图与原图在风格上高度统一的同时,内容上又完全不同。


图丨左:原图;右:相似图像生成(来源:通义万相生成)
这次我们来挑战高难度,左图是画面复杂的古风小姐姐,而万相生成的实测效果就有些差强人意。虽然内容上做到了同步,但是风格和原图就大有不同了。看来对于复杂图像的相似图生成来说,万相的模型训练还有待进一步加强。
3.图像风格迁移
风格迁移界面支持输入两张图片,一张为原图,一张为指定风格图。生成的图像会保留原图的内容和风格图的风格。



图丨图一:原图;图二:风格图;图三:生成图(来源:通义万相生成)
本次测试我采用的是万相生成的荷花图片(图一)与同是万相生成的插画风图片(图二)的风格相融合,生成了具有插画风格的荷花图(图三)。整体表现优秀,将原图的大部分内容插画风的同时,色彩上也做了统一。



图丨图一:原图;图二:风格图;图三:生成图(来源:通义万相生成)
这一次我选取了难度较高的两张图进行风格融合,可以看到万相融合了图一的内容和图二的色彩,完成了图三。图三整体风格迁移完整,细节保留也恨完好,但是并没有生成我期望的真正的Q版画风的女孩形象,希望后续可以提供更多给用户操作的空间。
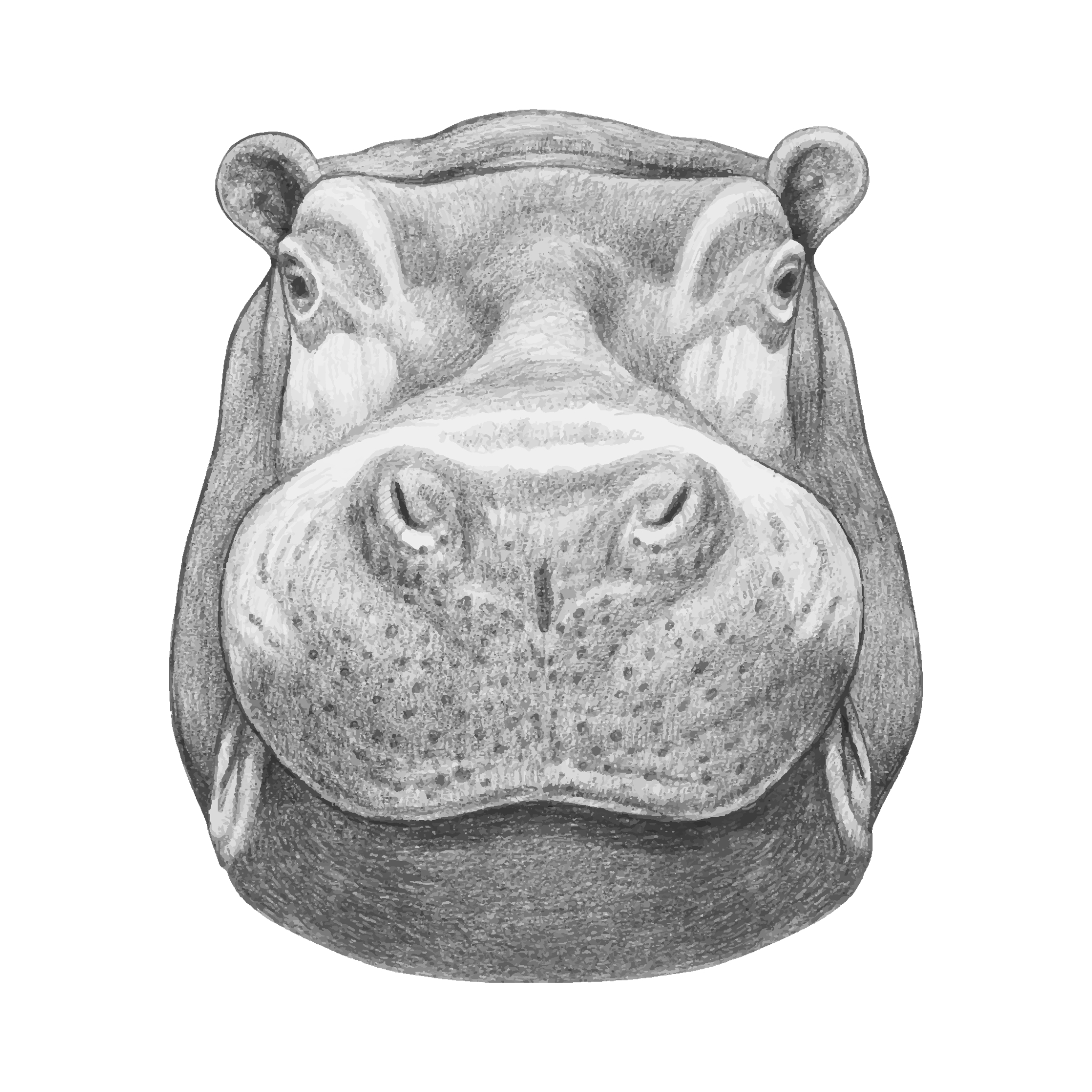


图丨图一:原图;图二:风格图;图三:生成图(来源:通义万相生成)
本次测试我采用的是官方示例图,可以看到,万相将素描风原图(图一)与手绘风图(图二)的风格迁移是非常优秀的。相较于第一次测试来说,本次原图的内容保留几乎完美,风格也完美的融合了图二。是真正意义上可以代表这一功能的示范图。
三、总结
这次体验总的来说,我对‘通义万相’这款产品的功能使用体验是非常满意的。产品的优点非常显著,能够满足目前大部分人对于ai文生图、图生图的功能需求。但产品还在发布初期,总归有一些功能不太完善。以下是我对【通义万相】这一产品的优点总结以及建议。
优点
- 生成速度快:经实测,复杂的图像生成在45s以下,简单图像在30s以下,图像生成的速度可以达到我的需求,这对于忙碌的用户来说非常方便。
- 文生图风格多样:支持8种风格,并且风格之间的差别,特色都十分显著。无论是二次元风格还是写实风格,表现力都不错。作为用户都可以找到适合自己的选择,这种多样性使得使用者可以根据自己的独特需求和喜好来创作出个性化的作品。
- 相似图与原图贴合程度极高:产品将相似图片与原图进行精确匹配,保留了原本图片的特征和细节。使用过程中无需担心生成的图片与原图差异过大。
- 风格迁移保留原本图像信息:万相能够保留原本图像的信息,使得生成的图片在拥有新的艺术风格的同时仍然能够保持原始图像的特征。这种特点使得生成的图片更具有艺术性和个性化,同时让使用者感受到了作品与自己原始创意的融合。
一些建议
- 完善模型对抽象词句的理解:在处理文本时,AI经常难以理解抽象的词句,导致生成的结果与用户期望的不一致。文学创作中的古诗、成语除了字面意思上之外通常有其他更抽象的含义,希望后续万相能够更好地理解抽象词句。
- 图生图功能提供关键词、保留词:建议在图生图功能中提供更多的操作空间,例如给用户提供关键词和保留词,让用户能够更灵活地生成图像。用户可以通过输入关键词来指定所需图像的风格或主题,同时通过保留词来决定图像中哪些内容需要保留。此外,还可以考虑加入背景颜色更换功能,让用户能够自由选择最适合的背景颜色。
- 画作管理库:希望万相能够提供一个画作管理库。目前,虽然可以保留20条生成记录,但对于大部分用户来说还是有些不够。通过建立一个画作管理库,用户可以将生成的画作按照图片、风格、内容等分类进行管理和查找。这样不仅方便用户整理生成记录,也能帮助用户更快地找到之前生成的作品。
近年来,随着人工智能技术的发展和应用,越来越多的软件和平台开始提供AI绘画创作功能,这些功能不仅给了不具备绘画技巧但有创意的人一个表达的方式,也为设计师、广告人员等提供了快速生成素材的选择。
尽管目前的功能在创作上有一定的局限性,但随着技术的不断进步,相信将来能够更好地满足用户的需求,生成更加多样化、精美的图片。我期待未来能见到‘通义万相’在艺术创作领域的更多应用,为我们带来更多惊喜和创意。
四、通义万相体验链接
在此附上‘通义万相’试用链接,邀请感兴趣的小伙伴一起体验~