2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
作者:励强(君瑜)
场景介绍
性能优化是企业级应用永恒的话题,关系型数据库查询优化更是如此。在前台核心业务场景中,类 KeyValue 查询(以下简称类 KV 查询)是非常常见的(例如,SELECT id, name FROM users WHERE id=1002),并且在应用总 SQL 流量占比很高,例如,天猫某核心业务的类 KV 查询占比近90%,商品某系统中占比近80%,交易订单系统中占比也有50%左右,菜鸟等其他核心业务场景中这个现象也是相当普遍。
这类 SQL 已经非常简单,如果仅在SQL层面进行进一步优化会非常困难,因此针对这类场景,TDDL/DRDS 配合 AliSQL 提出了全新的解决方案。
产品简介
在进入正题前,简单介绍下 TDDL/DRDS 产品,TDDL 是阿里巴巴集团为了解决淘宝电商数据库单机瓶颈,在2008年研制的中间件产品,以分库分表为核心理念,基于 MySQL 存储简单有效解决数据存储和访问容量问题,该产品支撑了历届天猫双十一核心交易链路的数据库流量,并且在此期间逐步成长为阿里巴巴集团访问关系型数据库的标准。
2014年,TDDL 团队和阿里云 RDS 团队合作,在云上输出这款产品,取名DRDS(Distributed Relational Database Service),专注于解决单机关系型数据库扩展性问题,目前该产品在公共云上具有超过 1000 家企业用户,并且在私有云输出,支撑多家大型企业和政府部门的核心业务,并且随着业务的扩大和业界技术的进展,DRDS 产品也会逐步给大家带来更加高效和务实的分布式数据库功能和解决方案。
新的思路
TDDL/DRDS 的类 KV 查询优化是怎么做的?这得从寻找基于 MySQL 的新优化思路说起。2015年,我们注意到社区版 MySQL 在5.6支持了 InnoDB memcached 插件,该插件允许应用的类 KV 查询走 Memcached 协议来直接访问 MySQL InnoDB 引擎的Buffer(走 Memcached 协议与走 MySQL SQL 协议都能访问 InnoDB 上的同一份数据)。这样让类 KV 查询直接绕开 MySQL Server 层的解析器、优化器与执行器等过程,从而大大降低应用类 KV 查询的 MySQL CPU 开销,扩大类似双十一极端场景下数据库容量,并且有效降低数据库响应时间。
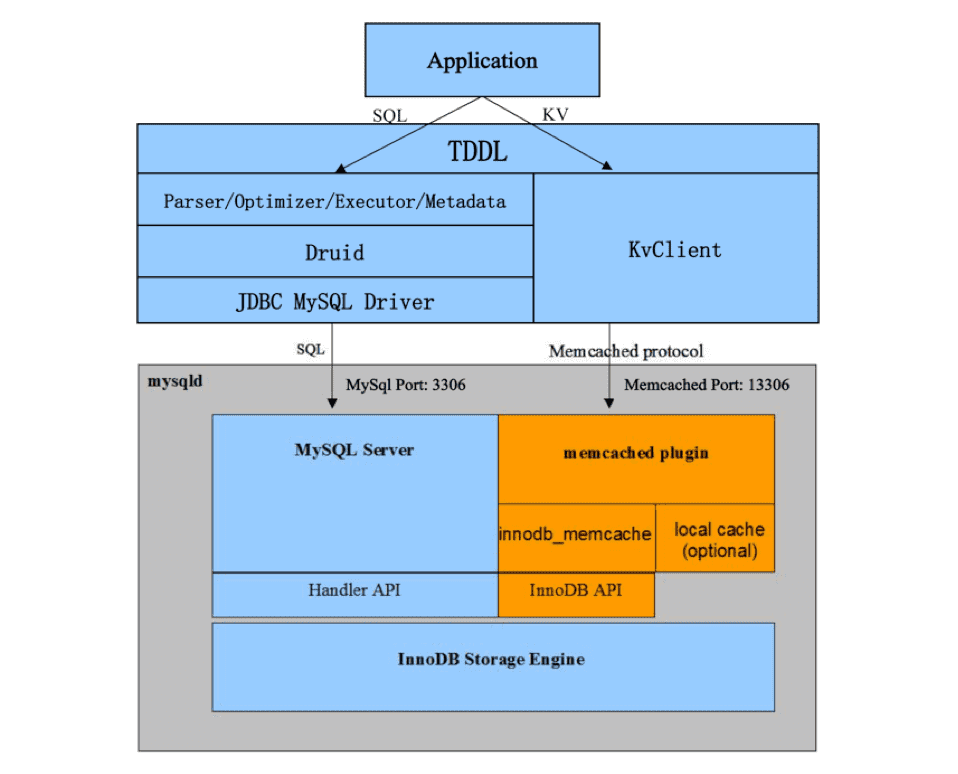
MySQL Memcahced Plugin 的类KV查询容量之所以能做到大幅度提升,是因为查询完全绕开了 SQL 在 MySQL Server 层的各项开销,查询链路被极致缩短,事实上,这样的优化思路对 TDDL/DRDS 也同样适用。
TDDL/DRDS 目前作为阿里巴巴集团关系型数据库的接入标准,为应用屏蔽了底层众多的水平拆分及主备库技术细节,然而,为业务带来便捷的分布式 SQL 入口同时,付出的代价也是有的。在 TDDL/DRDS 中,每一条 SQL,从入口到返回结果,需要经过 SQL 语法解析、查询优化、分布式执行计划生成,以及分布式执行、连接处理、类型处理等一系列过程,这些动作需要消耗大量应用端 CPU ( TDDL 客户端模式),因此如果类 KV 查询能在执行过程中完全绕开上述处理过程,直接走 Memcached 协议去查 MySQL 数据,那么整个链路将被进一步精简,从而提升应用的业务吞吐量和 DB 查询容量。
沿着这个优化思路,TDDL/DRDS 在阿里巴巴集团内提供了 KV 功能,专门针对此类查询场景实现极致的性能优化。
压测验证效果
为了专门验证 TDDL/DRDS 的这一项优化在具体业务场景中的实际效果,我们与天猫某核心业务团队共同在今年双11的全链路压测中进行 SQL 与 KV 的流量切换验证。
| KV场景 | TDDL-KV QPS | TDDL-SQL QPS | 提升情况 | 备注说明 |
|---|---|---|---|---|
| PK查询 | 1.7万 | 0.75万 | PK吞吐提升124% | PK类型是整数 |
| UK查询 | 1.6万 | 0.7万 | UK吞吐提升131% | UK类型是字符串 |
| 二级索引查询 | 1.6万 | 0.7万 | 二级索引吞吐提升132% | 平均每个二级索引的KV结果集是2行 |
在这次压测的过程中,应用层通过开关将集群QPS稳定在30w/s左右。然后,我们在 t1 时刻,将业务流量从走 KV 协议切回到走 SQL 协议,应用集群的 CPU 从 t1 时刻之后开始出现飙升,CPU从 46% 迅速升高到 63%,然后在 t2 时刻前后,业务再将流量从SQL切回KV,应用的 CPU 开始下降,整个过程持续5分钟,对比切换前后,同等QPS的流量,走 KV 比走 SQL 能节省 17% 左右的CPU,这个对于动则以万台来计算节点数量的核心应用而言,节省成本是明显的。
此外,TDDL/DRDS还做了更为纯粹的 KV 基准性能测试。在单纯的 KV 查询场景下,由于排除了业务处理逻辑的 CPU 开销,类 KV 查询走 KV 协议比走 SQL 协议吞吐提升会更为明显。
技术的创新点
在技术原理上,TDDL/DRDS 的类 KV 查询优化实现需要要依赖于 MySQL InnoDB Memcached 插件的特性。目前阿里巴巴集团 AliSQL 5.6 基于开源的 Memcached 插件代码支持了这一特性。
在 TDDL/DRDS 中,一个类 KV 查询走 SQL 接口与走 KV 接口却有着本质的不同,它们分别使用不同的端口来与MySQL进行通信。因此,这使TDDL在内部要维护两套不同的连接池,以及要处理两种不同的查询链路。
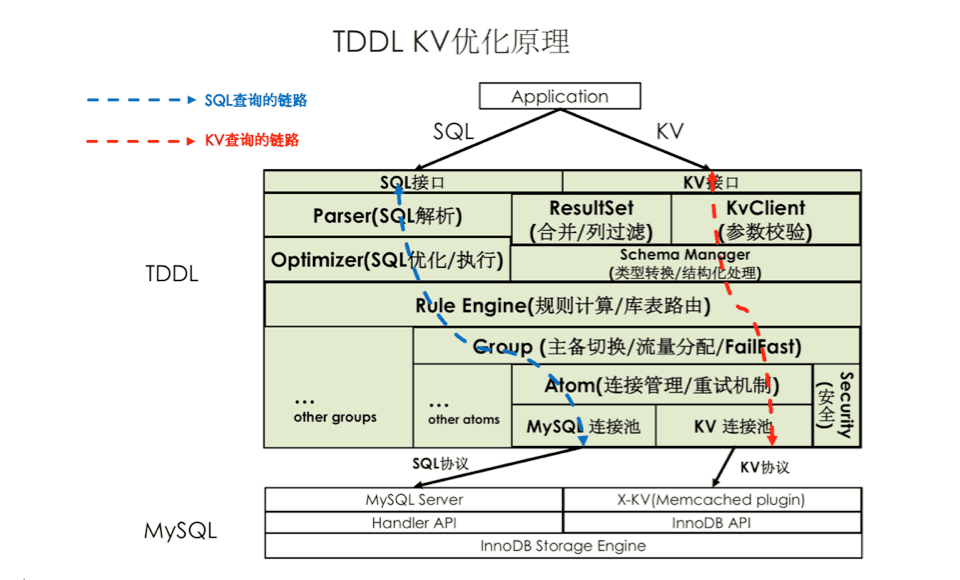
动态的分布式 KV 连接池
TDDL/DRDS 为保证 SQL 执行的稳定可靠,沉淀了各种成熟的保障机制,包括FailFast、主备切换、备库分流与连接池动态管理等等。这些机制为 TDDL/DRDS 的稳定性发挥着不可替代的作用。
同样为了保障 KV 优化功能在双11核心业务场景中稳定可靠,TDDL/DRDS 引入分布式 KV 连接池以及动态管理机制。
该机制的核心实现思想是 KV 连接池管理器会定时拉取相关配置信息,然后核对配置信息,如果发现有变更,自动对池中各个KV连接状态的进行相应的调整操作,例如完成KV的主备切换、备库分流、替换DB机器IP等等等。
TDDL/DRDS 采用这样的实现方案,一方面是为了保证 KV 连接池与 SQL 连接池的相互独立,另一方面是为保证 KV 连接池的变更能够与 SQL 连接池的变更保持协同。这样一旦 KV 连接池存在稳定性的风险,允许应用将流量及时切回 SQL 连接池并做到快速恢复,从而很好地管控风险。
此外,TDDL/DRDS 为 KV功能在稳定性上还做其它一些很有用的工作,例如,支持按分库灰度 KV ,这个特性允许单独对某个分库的查询流量在 SQL 协议与 KV 协议之间进行对应用透明的动态切换,这非常适合在 TDDL/DRDS 这种管理众多数据分片的场景下做流量的灰度验证。
优化的KV通信协议
原生的Memcached协议的查询结果默认使用“|”符号对一行记录的各个列进行分隔,使用这样的方式虽然简单,但缺点也显而易见。假如用户记录中含有“|”这种字符串或者因为中文乱码导致一些奇怪的字符,Memcached协议的结果的传输就会错乱,导致查询结果不正确。
TDDL/DRDS 为了解决这个问题,在原生 Memcached 协议的基础上进行了优化,设计了新的 KV 协议。新 KV 协议采用了更加普遍的通信协议设计方案,不再使用分隔符,而是改为固定长度字节的header描述一行记录中各个列值的长度,有效解决原生协议存在的问题。
KV 协议本身很简单,返回的数据包中只有数据本身,协议开销很低,并不像SQL协议,返回的数据包中除了含有结果集的数据外,还有相当部分是含有查询结果对应Meta信息(如每列的数据类型、列名、别名、表名和库名等等)。这些Meta信息会给SQL协议带来额外的CPU开销与网络开销,更严重的是,这些开销在KV查询的场景下会被放大,因为KV查询的返回结果通常是1~2条的记录,Meta的数据包在返回的数据包中的比重会明显增大,这并不太适全 KV 查询场景。因此,KV 协议更适合 KV 查询场景,这也是 TDDL/DRDS 的KV查询能做到吞吐优化的原因之一。
KV结果的自动类型转换
TDDL/DRDS 通过 KV 协议获取的数据都是字符串类型,直接返回给业务字符串类型数据不符合需求。因此,TDDL/DRDS 必须具备对查询结果各个列的字符串值进行自动类型转换的能力。与此同时,这个类型转换过程,必须严格遵循 MySQL 规范,才能良好适配 JDBC ResultSet 接口规范。
但是 KV 协议返回的数据包里并不含有列的元信息。因此,TDDL/DRDS 在解析 KV 返回结果之前,需要自己去获取表相关的Meta信息并进行缓存,这样,在解析过程中,就可以对结果按Meta进行类型转换。
后续的规划
TDDL/DRDS 目前还未在阿里云公共云或者私有云产品上输出这一特性,后续随着产品发展,我们慢慢会开放这种能力。另外产品层面,我们将会使用类Plan Cached方案,进一步优化性能,从而达到使用SQL转KV的链路如同直接使用KV一样损耗的效果。

