一、Havenask整体介绍
1、Havenask简介
Havenask是阿里巴巴自主研发的一款大规模分布式实时检索引擎,目前集团内的几乎所有的核心业务的搜索业务都是基于Havenask构建的。如为大众所熟知的淘宝和天猫商品搜索、菜鸟的订单物流搜索、优酷的视频搜索、高德的地理位置搜索,等等。而大家之所以选择Havenask,是因为与其他引擎相比,它在工程引擎性能、时效性、高可用上都有优异表现。如Havenask可支持万亿级别数据的实时检索,可以支持双十一百万QPS、TPS的交易洪峰,还能进行多机房的部署,具有较高的可用性等等。

2、Havenask应用场景
Havenask主要适用于检索场景和智能搜索场景,特别是海量数据检索、高性能检索等场景,智能搜索场景主要包括向量检索场景、商品智能搜索场景等。在性能上对比其他开源的搜索引擎进行测试,在70亿订单场景下,无论是按订单主键查询,或是按用户搜索词或标签的过滤查询,又或是按用户指定时间(如半年或是两年等历史订单)的查询,Havenask的QPS都会有百分之十几甚至十倍以上的提升,耗时可降至1/5,甚至1/10。

二、Havenask名词解释
Havenas相对复杂,掌握其专有的名词有助于大家更好地了解Havenask。
在线的系统是指提供在线检索服务的几个系统。离线系统是指能够提供索引构建的分布式系统。Swift是一些高性能的消息中间件。此外,如全量、增量、实时、索引分词、Term等。

三、Havenask架构
Havenask架构有两种形式。
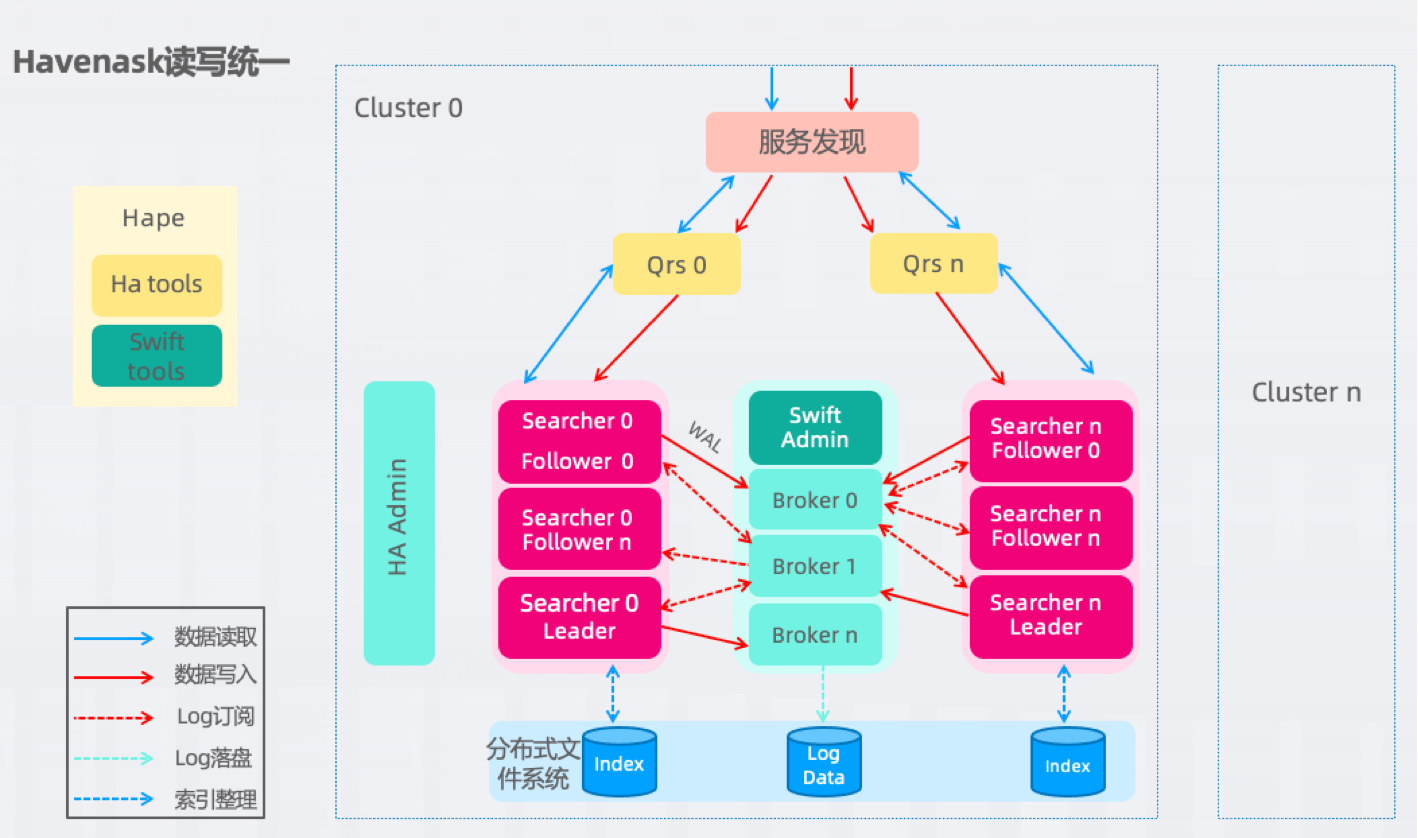
1、读写统一
即数据的写入和查询均由同一个节点完成,但又与其他系统不完全相同,其WAL是通过内置的消息中间件Swift实现的,这样就能避免随replica越多,数据写入变慢的问题。这种架构较为简单,其时效性性会更高,基本上可以实现read your write。
2、读写分离
即将索引构建流程独立形成一个分布式的索引构建的服务,这样在线系统会更加稳定。读写分离模式具备以下四个特点:

- 首先,其索引构建不会影响在线服务,反而会更加稳定,特别是对于一些索引构建消耗较大的场景,如向量检索场景。向量索引构建会消耗大量的计算资源。如果在读写统一架构下,它会影响在线服务的稳定性。
- 同时,读写分离可以支持全量数据的导入,可节省固定的时间,而读写统一模式数据的导入基本上都是通过API推入来完成的,当导入的数据量较大时,就需要花费很多的时间进行数据的推送,但在读写分离的模式下,其数据导入可通过调整离线资源直接从分布式存储系统中将全量的数据快速构建成索引,可以大大节省数据导入的时间。
- 另外,它对每个表索引构建都是按照独立的流程进行管理的,因此,其尤其适合需要定期做索引重建的算法场景。如模型或行为数据的更新,我们都会对数据重新进行一次全面的预测,换言之,要重新做一次索引的构建。这种独立的索引构建可以分任务进行管理,可以进行快速回滚,这种版本之间的快速切换可以保证日常索引构建变更的稳定性。
- 独立的索引构建流程,其资源可以单独进行控制,这样就可以通过单独的调整离线资源,以支持更高的数据写入。
四、Havenask代码结构
Havenask的代码结构相对清晰,其所有的核心代码都在aios目录下,与aios目录同级的是一些编译脚本、辅助工具及第三方的依赖。在aios目录下,我们主要关心四个主要的模块,即执行引擎sql、核心索引库indexlib、分布式构建服务build service及Swift消息中间件。前面的模块都是Havenask依赖的基础组件。
五、编译与部署
Havenask的编译与部署都是通过镜像的方式实现的。阿里云提供了两个镜像源供用户下载所需镜像,一个是Docker hub,另外一个是阿里云镜像。如果用户在国内,可以通过阿里云镜像下载,速度更快。编译Havenask之前,可以通过git克隆或代码包下载的方式,将代码下载到本地。目前,Havenask容器在Windows和Mac上还有一些适配问题。
1、镜像
- 镜像:
Docker hub:
havenask/ha3_dev:1.0.0
havenask/ha3_runtime:1.0.0
- 阿里云镜像:
registry.cn-hangzhou.aliyuncs.com/havenask/ha3 dev:1.0.0
registry.cn-hangzhou.aliyuncs.com/havenask/ha3_runtime:1.0.0
2、编译
- 下载代码:
cd~
git clone git@github.com:alibaba/havenask.git
- 创建容器:
cd ~/havenask/docker/havenask
docker pull registry.cn-hangzhou.aliyuncs.com/havenask/ha3_dev:latest
./create_container.sh registry.cn-hangzhou.aliyuncs.com/havenask/ha3_dev:latest
- 进入容器:
.//sshme
- 编译代码:
cd ~/havenask
./build.sh
- 单独编译某个目标:
bazelbuild //aios/sql:ha_sql--config=havenask
创建容器之后,进入容器,直接执行编译的脚本,可以编译出整个项目,也可以通过bazel的命令编译某个具体的目标。在执行bazel命令时,要指定Havenask配置选项。以下是一段代码演示:将代码下载到本地机器上后,首先进入docker Havenask目录下,执行create_container指令创建编译容器,通过ssh命令进入容器,再进入原代码所在目录。如果需要整体编译,可直接执行build.sh命令,如果需要编译某个具体的目标,可以通过bazel命令直接编译。
3、部署
- 创建容器:
cd ~/havenask/docker/havenask
docker pull registry.cn-hangzhou.aliyuncs.com/havenask/ha3_runtime:latest
./create_container.sh registry.cn-hangzhou.aliyuncs.com/havenask/ha3_runtime:latest
- 进入容器:
.//sshme
- 启动服务:
/ha3_install/hape start havenask
- 创建表:
/ha3_install/hape create table -t in0 -s /ha3_install/hape_conf/example/cases/normal/in0_schema.json -p 1
- 操作数据:
/ha3_install/sql_query.py --query "insert into in0 (createtime,hits,id,title,subject)values(1,2,4,'测试', '测试’)”
/ha3_install/sql_query.py --query "select * from in0"
目前,无论是单机版或是分布式版,Havenask的部署都是通过hape脚完成的。在部署之前,需要先创建可以运行hape脚本的容器,阿里云推荐用户使用Havenask中的create_container脚本,当然,也可以直接通过docker命令创建容器。容器创建完成之后,通过SSH脚本命令进入容器,然后通过hape命令启动集群,创建表,最后通过数据操作的封装脚本插入数据和检索数据。
六、结尾
具体Havenask简介及发展历史讲解视频可以通过链接查看,欢迎各位开发者使用。
视频链接:/live/253624?spm=a2c6h.13262185.profile.13.3713ee42mZuRGt
关注我们:
Havenask 开源官网:https://havenask.net/
Havenask-Github 开源项目地址:https://github.com/alibaba/havenask
阿里云 OpenSearch 官网:https://www.aliyun.com/product/opensearch
钉钉扫码加入 Havenask 开源官方技术交流群: