
问题一:PolarDB这个问题怎么解决?
PolarDB这个问题怎么解决?[语句1]:
ALTER TABLE tb_ai_inspect_item_result ENGINE = InnoDB
Invalid default value for 'id'
TraceId : 0abb7edb17087373776544413e277d
参考答案:
根据提供的知识内容,您在尝试将PolarDB MySQL版中的表tb_ai_inspect_item_result的存储引擎修改为InnoDB时遇到了错误:“Invalid default value for 'id'”。这意味着在该表结构中,列id的默认值设置不被InnoDB存储引擎接受。
通常情况下,当从一个存储引擎转换到另一个存储引擎(如MyISAM转为InnoDB)时,需要确保表结构的所有元素都符合目标存储引擎的要求。例如,在MySQL 8.0及PolarDB MySQL版中,InnoDB引擎对于列的默认值可能有更严格的约束。
建议您检查以下几点:
确认id列的默认值定义是否符合InnoDB存储引擎的规定。
检查该列的数据类型和默认值设定是否存在语法错误或与InnoDB不兼容的地方。
如果id列为自增(AUTO_INCREMENT)字段,请确保其默认值为空或正确设置了AUTO_INCREMENT属性。
若要解决此问题,请按照以下步骤进行排查和修正:
查看表tb_ai_inspect_item_result的创建语句,特别是id列的部分。
根据InnoDB存储引擎的要求调整id列的默认值设定。
使用正确的ALTER TABLE语句更改存储引擎,例如:ALTER TABLE tb_ai_inspect_item_result ENGINE = InnoDB;
如果需要进一步的帮助,请提供具体的表结构信息以便给出更精确的指导。
关于本问题的更多回答可点击进行查看:
/ask/600097?spm=a2c6h.12873639.article-detail.47.787343787T80t7
问题二:PolarDB冷存数据到OSS之后如何恢复?
PolarDB冷存数据到OSS之后如何恢复?
参考答案:
在阿里云PolarDB MySQL数据库中,将冷存数据从OSS恢复到PolarDB的过程如下:
如果您归档的数据是CSV或ORC格式存储在OSS上,您可以使用ALTER TABLE语法将OSS上的冷数据导入回PolarDB的PolarStore中进行修改。具体操作为:
ALTER TABLE database_name.table_name ENGINE = InnoDB;
这将会把OSS表转换成可读写的InnoDB表,然后您可以在该表上执行INSERT、UPDATE和DELETE等操作。
在对数据进行修改后,如果需要再次将修改后的表归档至OSS,可以使用以下语句:
ALTER TABLE table_name ENGINE = CSV CONNECTION = 'default_oss_server';
或者
ALTER TABLE t ENGINE = CSV STORAGE OSS;
对于通过STORAGE_TYPE OSS归档的IBD格式冷数据,若要切回PolarStore块存储模式并查询/修改数据,首先执行:
ALTER TABLE table_name STORAGE_TYPE NULL;
然后,对于不再需要的OSS上对应文件,调用存储过程删除:
CALL dbms_oss.delete_table_file('database_name', 'table_name');
注意,从OSS恢复和删除文件的操作可能需要一定时间,并且有异步时延。
总结来说,恢复OSS上的冷数据至PolarDB主要涉及更改表引擎类型以及根据实际需求进行相应的数据迁移与清理操作。在操作前,请确保您的数据恢复符合业务需求,并充分测试以满足性能要求。
关于本问题的更多回答可点击进行查看:
/ask/600096?spm=a2c6h.12873639.article-detail.48.787343787T80t7
问题三:对于大批量的数据,例如一张表一天有1000万行新数据,一个月就3亿行,PolarDB如何应对?
对于大批量的数据,例如一张表一天有1000万行新数据,一个月就3亿行,PolarDB如何应对? (问答ID: #TGHFyNcE5RJZaw2ryEmf7a#3666183#)
参考答案:
请参考文档 https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/partitioned-tables-faq
关于本问题的更多回答可点击进行查看:
/ask/600095?spm=a2c6h.12873639.article-detail.49.787343787T80t7
问题四:Polardb 监控 图 展示的数据是不是不准确?
Polardb 监控 图 展示的数据是不是不准确? 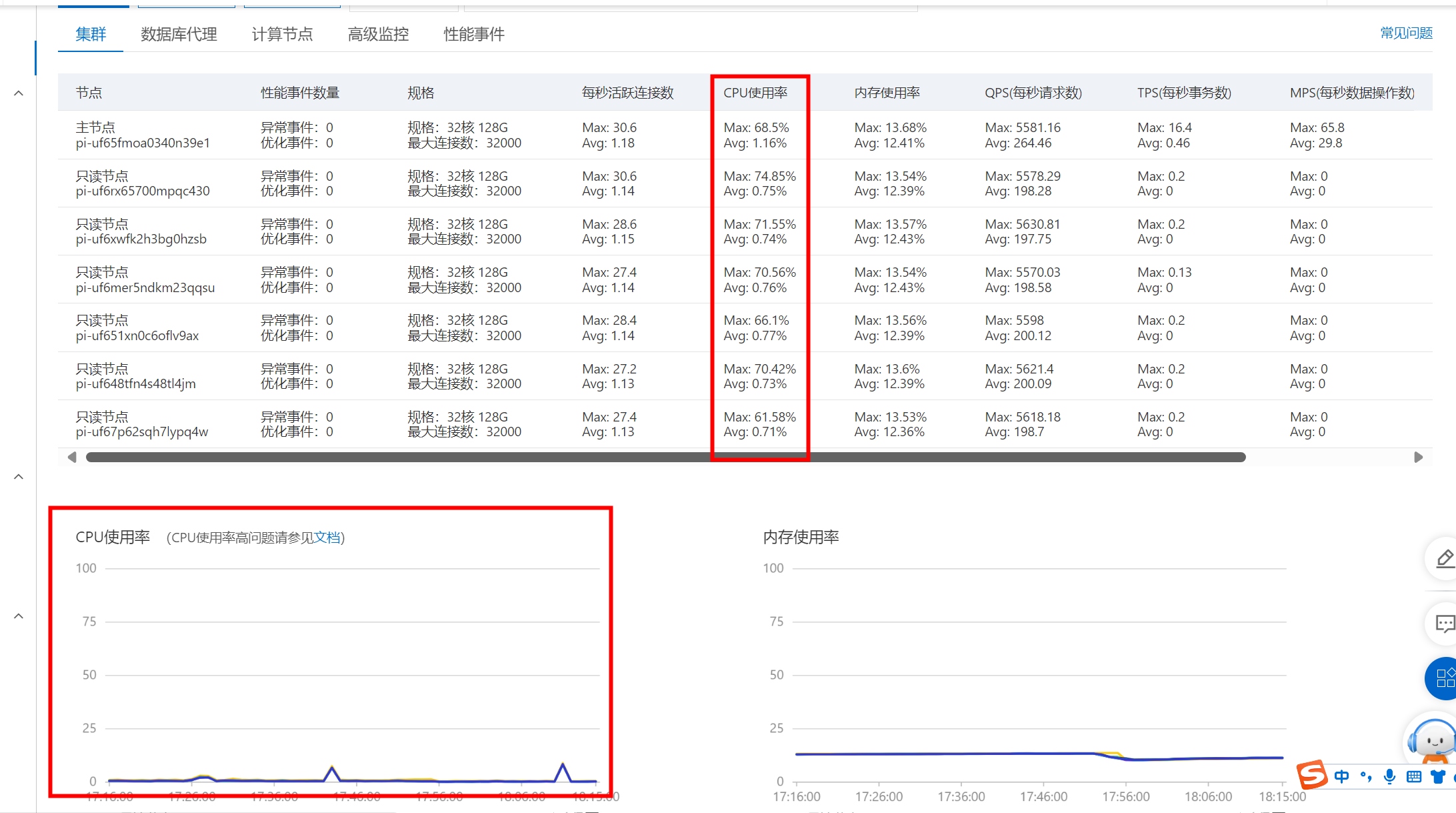
参考答案:
准确的,图上展示的数据是每一个时间段取了平均值的数值。
关于本问题的更多回答可点击进行查看:
/ask/600094?spm=a2c6h.12873639.article-detail.50.787343787T80t7
问题五:当前rds mysql用的对应到polardb mysql 应该是什么规格?
当前rds mysql用的是rds.mysql.c1.xlarge高可用本地盘-通用型 8核 32GB, 对应到polardb mysql 应该是什么规格?
参考答案:
可以选择PolarDB标准版 通用型 8核 32GB +PL1存储。
关于本问题的更多回答可点击进行查看:
/ask/600092?spm=a2c6h.12873639.article-detail.51.787343787T80t7
