问题一:有人用过Flink CDC 3.0版本的整库同步吗?
有人用过Flink CDC 3.0版本的整库同步吗?我用Flink CDC3.0整库同步mysql到starRock提交任务异常,有人遇到过这个问题吗? 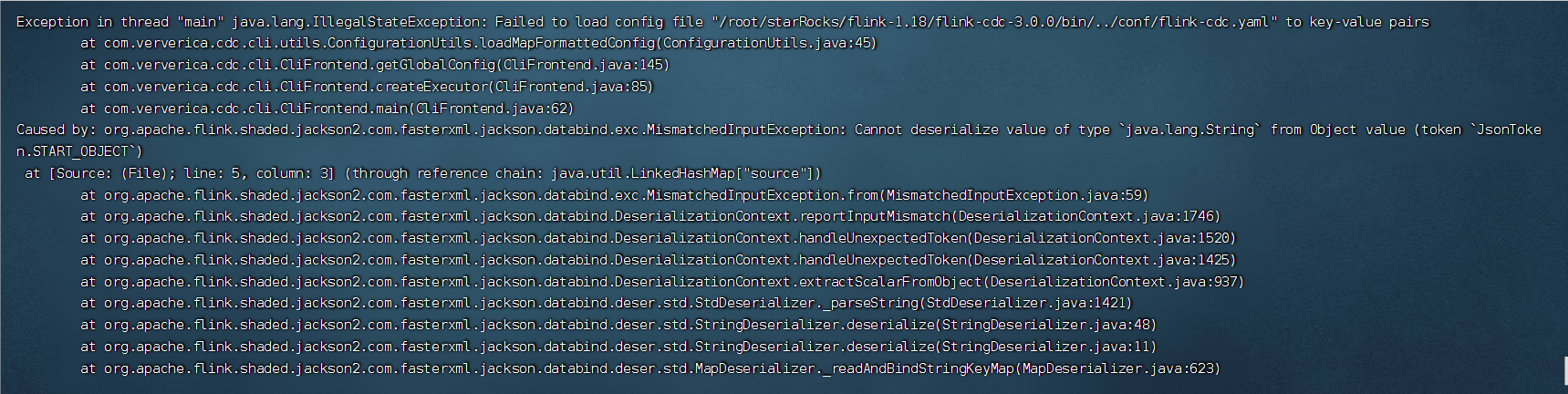
参考回答:
先保持原来的参数,任务写到另外的文件里。 
关于本问题的更多回答可点击原文查看:/ask/592256
问题二:Flink CDC里 flink集群jps命令 报错怎么办?
Flink CDC里 flink集群jps命令 报错java.lang.OutOfMemoryError: unable to create new native thread 内存不足无法创建新的进程 我看了下机器内存情况 好像确实不多了 但是buffer 和available里面有 是不是没释放啊 ?
参考回答:
可能的原因
OutOfMemoryError: unable to create new native thread出现的情况有两种:
- 服务器剩余内存不足(非JVM内存),不能创建新的线程
- 超出服务器用户最大进程限制:
ulimit -u。
关于本问题的更多回答可点击原文查看:/ask/592258
问题三:Flink CDC里 为啥cache会占用这么多内存? 怎么才能让他自动释放掉?
Flink CDC里 为啥cache会占用这么多内存? 怎么才能让他自动释放掉? 
参考回答:
Apache Flink CDC(Change Data Capture)在处理数据流时可能会积累大量的内存,尤其是当捕获的数据量较大或处理过程中存在状态存储时。Flink CDC任务取消后,如果内存没有及时释放,可能是因为以下几个原因:
- 状态后置清理:
- Flink在取消任务后,会异步清理task的状态,包括checkpoint状态和managed memory中的数据结构。这部分清理过程可能需要一定时间,并且在极端情况下,可能不会立即回收所有内存。
- 堆外内存(Off-heap Memory):
- 如果Flink作业使用了堆外内存(例如 RocksDB状态后端),内存释放可能更加复杂,因为它不受JVM垃圾回收机制管理,需要Flink自身去释放这部分资源。
- 资源泄漏:
- 如果存在资源泄露,如未能正确关闭网络连接、文件流或其他系统资源,可能导致内存无法正常释放。
- Flink内部缓存或队列:
- CDC组件可能在内部维护了一些缓存或者队列,即便任务取消,这些结构如果没有被正确清空或关闭,也可能导致内存占用较高。
解决Flink CDC内存占用过大的问题,可以尝试以下措施:
- 等待资源释放:给Flink一段合理的时间自行清理资源。
- 检查和优化状态后端配置:确保状态后端配置合理,例如 RocksDB的配置,包括内存大小和checkpoint策略。
- 确认作业终止后状态清理:如果使用了checkpoint,确保作业在停止后完成了checkpoint的清理工作。
- 排查是否存在资源泄漏:审查代码和配置,确保所有资源在任务取消或失败时都能得到妥善清理和关闭。
- 手动触发GC:在诊断阶段,可以尝试触发Java垃圾收集器来回收堆内存,但这不是长期解决方案。
- 重启TaskManager或整个集群:在必要时,重启受影响的TaskManager或整个Flink集群可以彻底释放资源,但这应该是最后的手段,因为会导致服务中断。
总的来说,优化Flink CDC内存管理的关键在于合理配置和有效监控任务运行状态。如果问题持续存在,建议深入分析Flink的日志和监控指标,以便定位具体的问题根源。
关于本问题的更多回答可点击原文查看:/ask/592260
问题四:Flink CDC里为什么我运行好了demo没有数据出来?
Flink CDC里为什么我运行好了demo没有数据出来?public class MySqlCDCSourceExample {
public static void main(String[] args) throws Exception {
MySqlSource mySqlSource = MySqlSource.builder()
.hostname("localhost")
.port(3306)
.databaseList("demo") // set captured database
.tableList("demo.answer_paper") // set captured table
.username("root")
.password("Hadoop.123456")
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // enable checkpoint env.enableCheckpointing(3000); env .fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source") // set 4 parallel source tasks .setParallelism(4) .print().setParallelism(1); // use parallelism 1 for sink to keep message ordering env.execute("Print MySQL Snapshot + Binlog"); }
}
参考回答:
根据cdc文档来部署。scan.startup.mode:initial。或者你设置下 startupOptions。
我用的是这个。
关于本问题的更多回答可点击原文查看:/ask/592263
问题五:Flink CDC里为什么这样写不生效?
Flink CDC里为什么这样写不生效?debezium.column.exclude.list。 
参考回答:
试下column.exclude.list =schemaName.tb.column。 
关于本问题的更多回答可点击原文查看:/ask/592264
