一、Havenask介绍
Havenask 是阿里巴巴广泛使用的自研大规模分布式检索系统,是过去十多年阿里在电商领域积累下来的核心竞争力产品,广泛应用在搜推广和大数据检索等典型场景。在2022年云栖大会-云计算加速开源创新论坛上完成开源首发,同时作为阿里云开放搜索OpenSearch底层搜索引擎,OpenSearch 自2014年商业化,目前已有千余家外部客户。
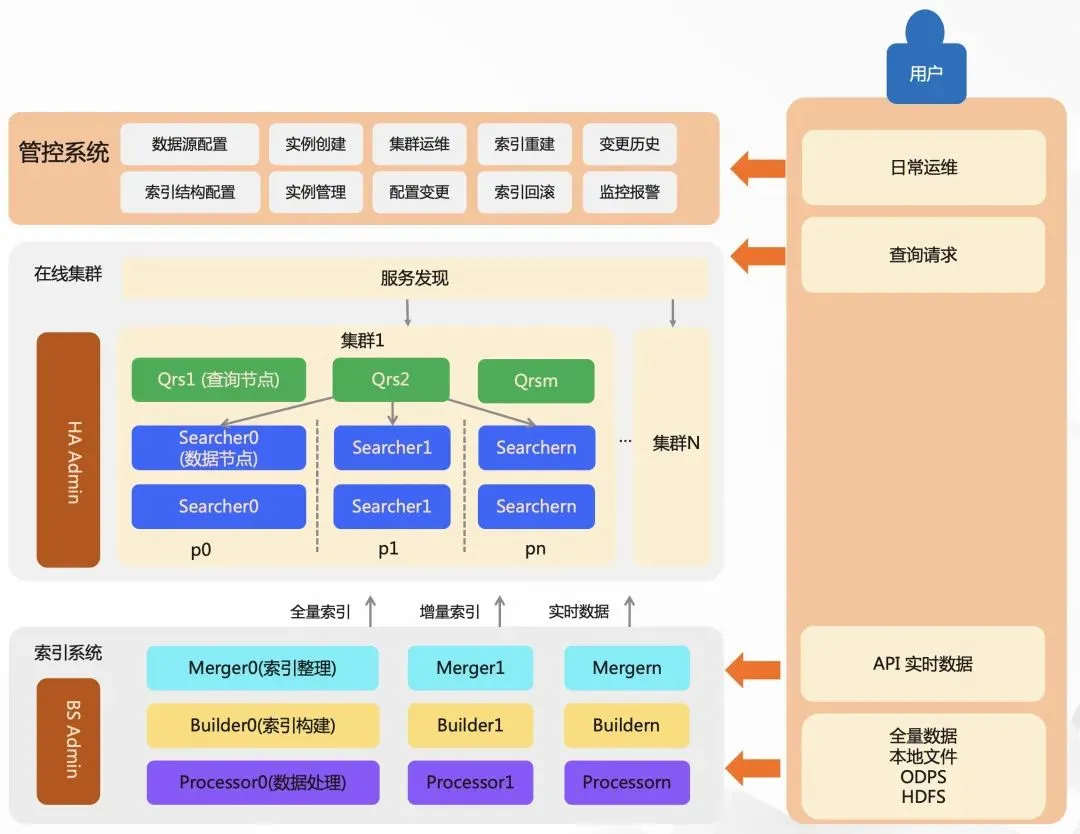
在性能上Havenask 支持千亿级别数据实时检索、百万 QPS 查询,百万 TPS 高时效性写入保障,毫秒级查询延迟和数据更新,并具有良好的分布式架构、极致的性能优化,能够实现比现有技术方案更低的成本,普惠更多的开发者和企业。(Github地址:https://github.com/alibaba/havenask)
二、需求说明
下面以电商场景的检索为例说明性能测试的流程,一件商品有多个属性,用户希望能够通过多种方式查询,比如召回某个品牌的手机、召回某个价格区间的笔记本电脑,或者多个条件同时满足等。用户需要提供商品各个维度的信息,比如编号(id)、名字(title)、价格(price)等,并将其组织成一篇文档,在hape的概念里称为document(简称doc),如下表所示:
id |
title |
price |
1 |
红棉优级小粒老黄冰糖1.2kg大罐炖煮煲汤红烧肉酵素柠檬花茶雪梨 |
32.9 |
2 |
异形魔方顺滑风火轮移棱 枫叶变幻金刚 镜面粽子二阶齿轮五魔方 |
15.8 |
3 |
纳米双面胶带双面胶无痕贴纳米双面胶高粘度强力防水胶带魔力胶带 |
10.9 |
4 |
定制皇冠黑金生日蛋糕水果蛋糕男士女神深圳广州上海全国同城配送 |
199 |
5 |
Meizu/魅族 魅蓝E2 全网通正面指纹快充4G智能手机 |
1299 |
6 |
原厂正品巨化R134a 制冷剂 汽车冰柜 冷媒 雪种 氟利昂净重13.6kg |
500 |
7 |
挂耳染假发片女徐璐同款渐变编发绳嘻哈脏辫挑染拳击辫挂耳染发片 |
10.8 |
8 |
开关用保开套家灯关贴墙贴插座贴护纸装饰框套夜光创意防边脏遮丑 |
5.9 |
9 |
测速器测速仪初速射速动能 汉特 液晶语音 wifi HT-X3005水弹NERF |
699 |
10 |
8067634|正版包邮现货全面预算管理:案例与实务指引第2版 龚巧莉财务知识轻松学经济管理财务管理财政税收预算支出 |
50.9 |
为了模拟真实的高压场景,我们需要准备好与真实线上环境相同体量的数据,每篇doc的属性最好也都与线上真实数据相似,将测试数据都写入Havenask集群后,还需要模拟线上用户的查询,虚拟出一批相似的查询,压测时使用这批查询从而产出真实可靠的性能指标。同时,在压测时需要时刻关注集群的水位,如CPU负载和内存使用情况等,从而能更全面地衡量系统性能。
三、测试数据
搭建好Havenask集群后,可以开始准备向集群中写入测试数据,这里使用电商行业的少量测试数据举例说明具体的操作步骤。
按照说明下载数据集,并转换为Havenask格式,将转换好的文件保存为ecom.data,示例如下:
CMD=add^_ id=1^_ title=红棉优级小粒老黄冰糖1.2kg大罐炖煮煲汤红烧肉酵素柠檬花茶雪梨^_ price=32.9^_ ^^ CMD=add^_ id=2^_ title=异形魔方顺滑风火轮移棱 枫叶变幻金刚 镜面粽子二阶齿轮五魔方^_ price=15.8^_ ^^ CMD=add^_ id=3^_ title=纳米双面胶带双面胶无痕贴纳米双面胶高粘度强力防水胶带魔力胶带^_ price=10.9^_ ^^ CMD=add^_ id=4^_ title=定制皇冠黑金生日蛋糕水果蛋糕男士女神深圳广州上海全国同城配送^_ price=199^_ ^^ CMD=add^_ id=5^_ title=Meizu/魅族 魅蓝E2 全网通正面指纹快充4G智能手机^_ price=1299^_ ^^ CMD=add^_ id=6^_ title=原厂正品巨化R134a 制冷剂 汽车冰柜 冷媒 雪种 氟利昂净重13.6kg^_ price=500^_ ^^ CMD=add^_ id=7^_ title=挂耳染假发片女徐璐同款渐变编发绳嘻哈脏辫挑染拳击辫挂耳染发片^_ price=10.8^_ ^^ CMD=add^_ id=8^_ title=开关用保开套家灯关贴墙贴插座贴护纸装饰框套夜光创意防边脏遮丑^_ price=5.9^_ ^^ CMD=add^_ id=9^_ title=测速器测速仪初速射速动能 汉特 液晶语音 wifi HT-X3005水弹NERF^_ price=699^_ ^^ CMD=add^_ id=10^_ title=8067634|正版包邮现货全面预算管理:案例与实务指引第2版 龚巧莉财务知识轻松学经济管理财务管理财政税收预算支出^_ price=50.9^_ ^^
注意:
- 文档中的
^_和^^均是一个字符,对应的Unicode编码分别为^_: "\x1F"和^^: "\x1E",换行符是linux格式'\n',如果是windows环境编辑则换行是'\r\n',此种情况下索引build不成功。请勿在windows环境中编辑任何配置、数据。 - 文档的最后一行要有一个'\n',否则最后一篇文档会丢失。
四、配置文件及索引构建
配置schema文件,并使用全量模式构建索引。
- schema文件用于描述doc各个字段的类型,以及索引配置等信息。一般需要对用户搜索的字段建立倒排索引,对用于过滤、排序的字段建立正排索引,配置最好也要与线上一致;特别地,注意TEXT类型的索引,需要配置分词器对其进行分词后再建立倒排索引,选用不同的分词器会建立起完全不同的索引,使得同一个查询召回的doc数量不同,对压测的指标有较为明显的影响。
- 具体的schema配置方法可以参考Havenask官方文档,这里以ecom数据集简单举例
{ "columns": [ { "name" : "id", "type" : "UINT64" }, { "analyzer": "jieba_analyzer", "name" : "title", "type" : "TEXT" }, { "name" : "price", "type" : "DOUBLE" } ], "indexes": [ { "name": "default", "index_type": "PACK", "index_config": { "index_fields": [ { "boost": 1, "field_name": "title" } ] } }, { "name": "id", "index_config" : { "index_fields": [ { "field_name": "id" } ] }, "index_type": "PRIMARY_KEY64" }, { "name": "price", "index_config" : { "index_fields": [ { "field_name": "price" } ] }, "index_type": "ATTRIBUTE" }, { "name": "summary", "index_type": "SUMMARY", "index_config": { "index_fields": [ { "field_name": "id" }, { "field_name": "title" }, { "field_name": "price" } ] } } ] }
- 索引构建(以hape单机模式为例)
/ha3_install/hape create table -t ecom -p 1 -s ./ecom_schema.json -f ./ecom.data
- 等待索引构建完成,压测集群就准备好了。
五、生成用于压测的查询语句
接下来需要准备测试用的查询语句,可以随机从线上取样一些真实的query。针对不同的查询场景,可以分类取样多种查询,测试在不同场景下Havenask集群的性能,例如可以只对简单的召回场景做测试,或者是可以加上一些过滤和排序来衡量较为复杂场景下的性能表现,也可以是简单和复杂查询都有的混合case。
不同的查询语句有着不同的复杂度,这里简单举例查询ecom表title字段的查询语句:
{"assemblyQuery": "select * from ecom where MATCHINDEX('default', '纳米')&&kvpair=databaseName:database;formatType:string"} {"assemblyQuery": "select * from ecom where MATCHINDEX('default', '魔方')&&kvpair=databaseName:database;formatType:string"} {"assemblyQuery": "select * from ecom where MATCHINDEX('default', '皇冠')&&kvpair=databaseName:database;formatType:string"} {"assemblyQuery": "select * from ecom where MATCHINDEX('default', '汽车')&&kvpair=databaseName:database;formatType:string"} {"assemblyQuery": "select * from ecom where MATCHINDEX('default', 'wifi')&&kvpair=databaseName:database;formatType:string"}
为了保证测试结果与真实场景相似,可以准备一定量级的查询以模拟真实的查询场景。将查询文件保存为query.data。
六、压测工具及压测脚本
使用开源的压测工具wrk: (https://github.com/wg/wrk)以得到Havenask集群的QPS、查询耗时等性能指标。
git clone https://github.com/wg/wrk.git cd wrk make
wrk是一个开源的HTTP性能测试工具,可以基于lua脚本灵活地控制压测流程,以下是一个wrk的lua脚本示例:
-- 指定请求方法都为 POST,MIME 类型为简单的 url-encode wrk.method = "POST" count = 0 query_count = 0 -- 定义读取 query 内容的函数,query 已预处理好并且转义 function get_query(path) local file, errorMessage = io.open(path, "r") if not file then error("Could not read file: "..errorMessage.."\n") end local content = file:read "*all" file:close() return content end -- wrk 运行阶段初期,先加载所有的 body 内容到一个 table 中,运行时直接随机读取 init = function (args) query_table={} local file, errorMessage = io.open("../../query.data", "r") -- 加载query数据 if not file then error("Could not read file: "..errorMessage.."\n") end local query = file:read "*line" while (query ~= nil) do query_table[query_count]=query; query_count = query_count + 1 query = file:read "*line" end file:close() end -- wrk 运行阶段,选取query,构造具体发送的请求 request = function () local query = query_table[count] count = (count + 1)%query_count return wrk.format("POST", "/QrsService/searchSql", nil, query) end -- 打印返回结果,确认请求成功后可以注释掉 response = function(status, headers, body) print(status, body) end
通过命令行执行wrk,对Havenask集群进行压测:
./wrk -c4 -d30s -t2 -s scripts/search.lua http://127.0.0.1:45800 --latency
-c: 连接数
-d: 压测时间
-t: wrk线程数
-s: 使用的脚本
--latency: 打印详细的性能指标信息
启动wrk后,可以通过top等系统命令查看机器负载,压测结束后wrk会自动打印出各项性能指标,如下:
Running 30s test @ http://127.0.0.1:45800 2 threads and 4 connections Thread Stats Avg Stdev Max +/- Stdev Latency 16.26ms 20.24ms 71.67ms 79.80% Req/Sec 295.74 24.83 460.00 72.00% Latency Distribution 50% 2.72ms 75% 29.15ms 90% 52.11ms 99% 66.08ms 17679 requests in 30.03s, 13.24MB read Requests/sec: 588.73 Transfer/sec: 451.64KB
七、总结
随着互联网的快速发展,信息爆炸已经成为一个普遍的现象,大量的数据需要被存储、管理和检索,庞大的数据量和用户对于延时的高要求逐渐成为了很多业务的挑战。通过性能测试能够提前掌握系统的性能,需要接入大流量的请求时也能够提前准备好足够的资源,性能测试对于维护业务稳定性的重要性不言而喻。Havenask具有实时数据更新秒级完成,能支持海量数据索引构建、检索性能高等优点,自己动手搭建Havenask集群,并参考真实的生产环境对Havenask进行压测,可以帮助学习Havenask的使用方法,并对其性能有一个初步的了解。
参考资料:
Havenask官网-Hape命令:https://havenask.net/#/doc/v1-1-0/sql/petool/command#update
关注我们:
Havenask 开源官网:https://havenask.net/
Havenask-Github 开源项目地址:https://github.com/alibaba/havenask
阿里云 OpenSearch 官网:https://www.aliyun.com/product/opensearch
钉钉扫码加入 Havenask 开源官方技术交流群:

