2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
文生图模型-Stable Diffusion
什么是生成式模型
所谓的生成式模型就是通过文本或者随机采样的方式来得到一张图或者一段话的模型,比如文生图,顾名思义通过文本描述来生成图像的过程。当前流行的文生图模型,如DALE-2, midjourney以及今天要介绍的Stable Diffusion,这3种都是基于Diffusion扩散模型。

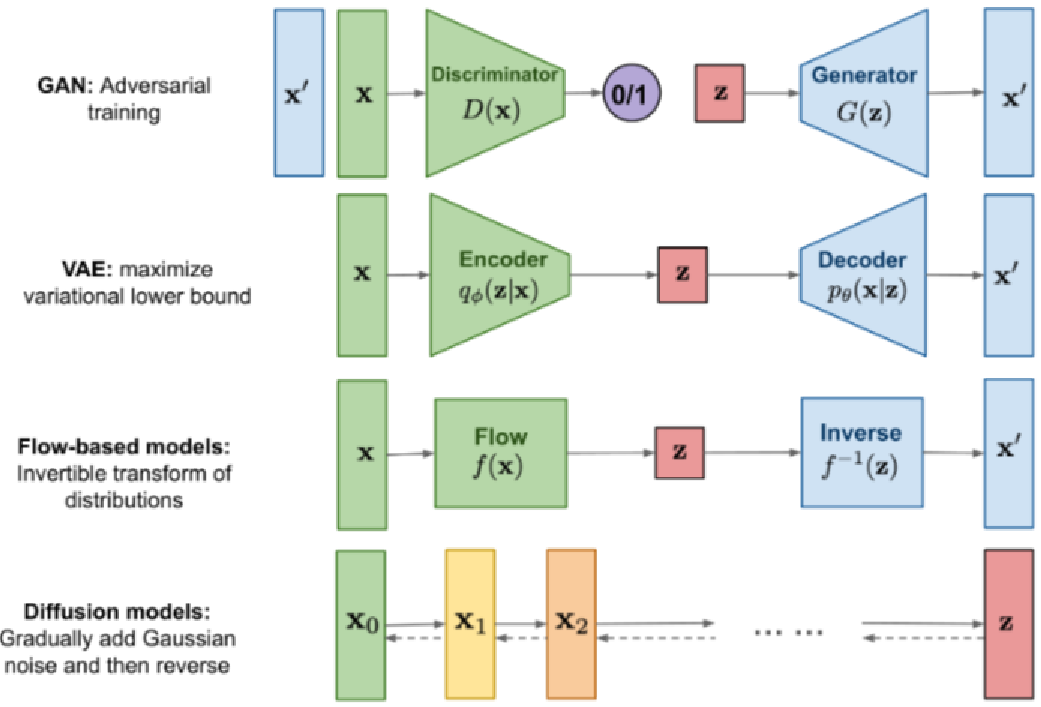
在Diffusion扩散模型之前,经典的生成模型是GAN和VAE。GAN是生成对抗网络(Generative Adversarial Network)的简称,是一种用于生成模型的深度学习框架。GAN由两个神经网络组成:生成器和判别器。生成器网络负责生成新样本,而判别器网络负责判断这些样本是真实的还是生成的。这两个网络相互对抗,通过不断的博弈和调整参数,最终达到生成逼真的样本的目的。最后通过采样一个随机分布来生成和训练数据分布相同的图片。

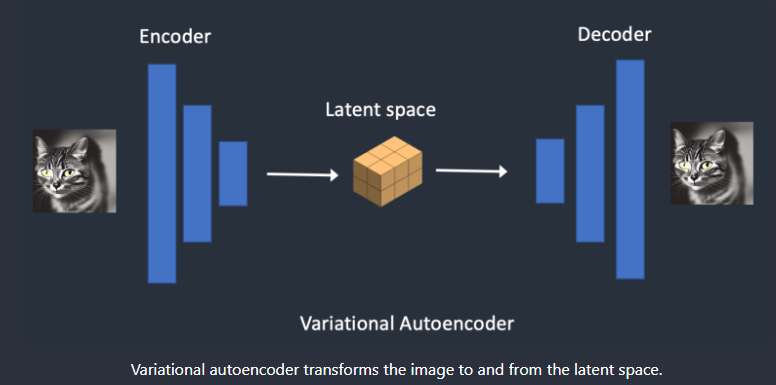
而VAE是变分的自回归模型,通过学习图片的潜在空间表示来生成图片。
扩散模型Diffusion
扩散一词来源于物体物理状态的变化,比如房间中的气味由浓逐渐扩散到周围,最终房间的气味处于一个平衡的状态,再比如热力的传播。
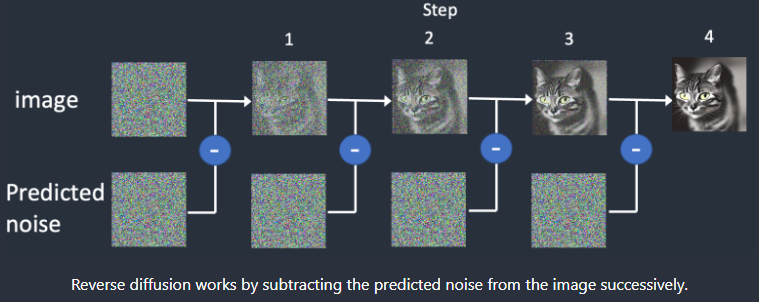
扩散模型(Diffusion Model)分为前向和逆向操作,前向阶段对图像逐步施加噪声, 直至图像被破坏变成完全的高斯噪声, 然后在逆向阶段学习从高斯噪声还原为原始图像的过程。

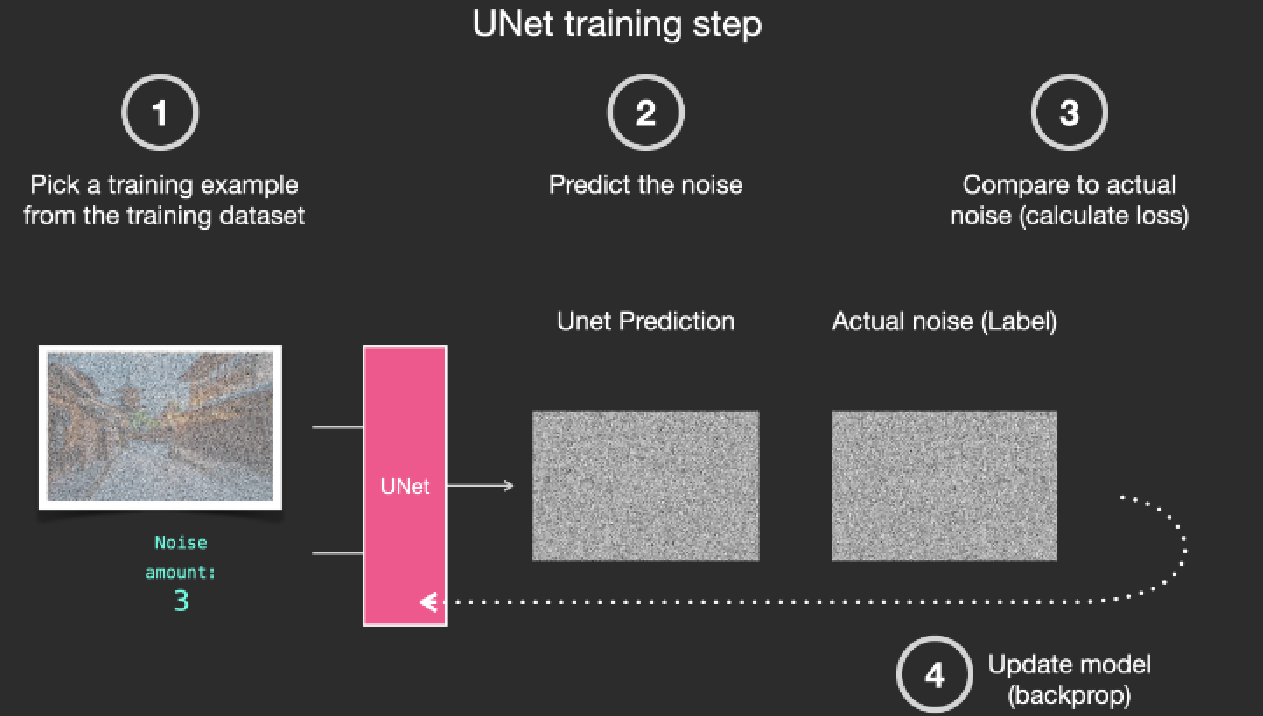
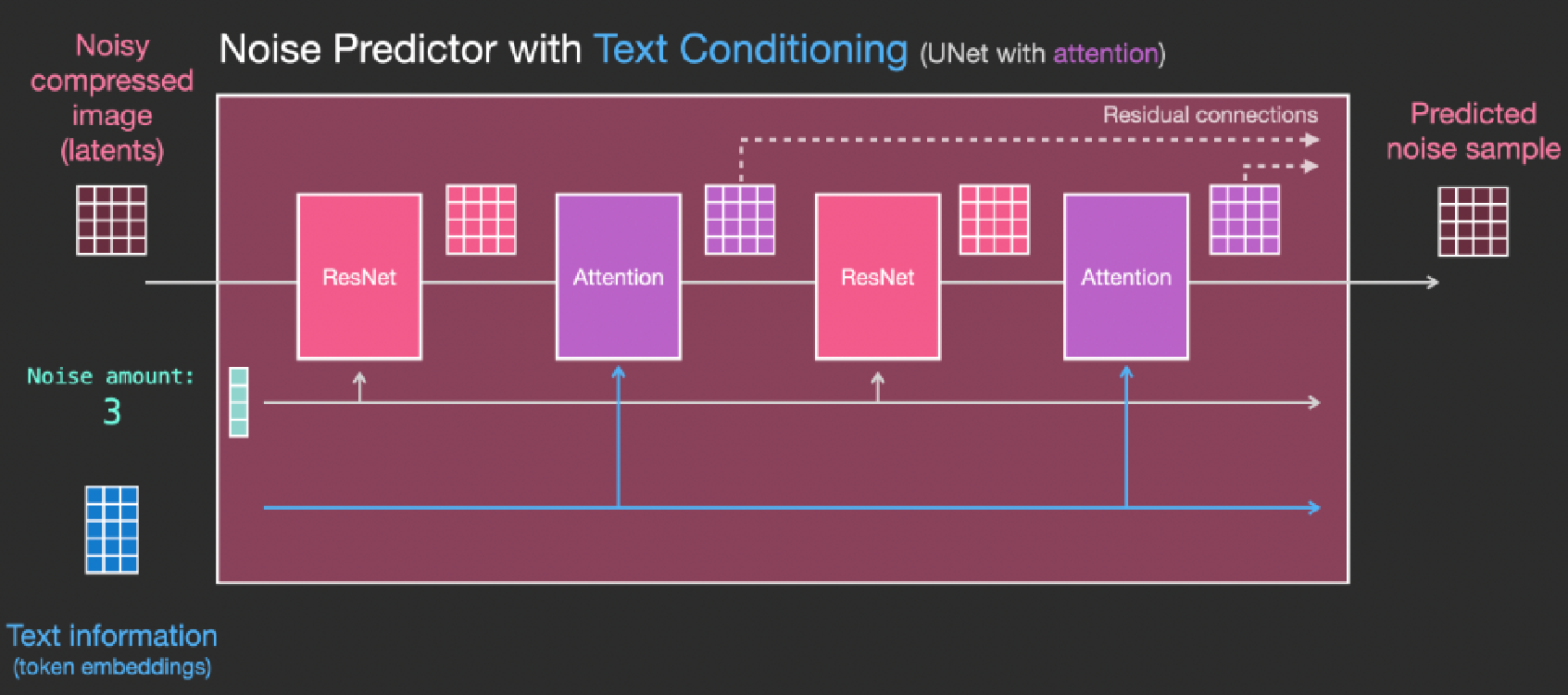
那么扩散模型是如何训练?训练的过程就是预测所加噪声的过程,模型是一个Unet模型。
- 正向:第i步的图像+高斯噪声=第i+1的图像
- 训练Unet时:输入第i+1的图像,预测的GT是所加的高斯噪声,复原过程就是第i+1的图像-高斯噪声


通过多步的操作,最终从一个采样的高斯噪声,逐步去噪还原回清晰图像的过程。每一步的Unet模型是共享参数的,所以需要额外的输入步长的信息,告知模型这个在做第几步的去噪。
最早的扩散模型(DPM)需要近1000步才能还原图像,这极大的增加了推理的时间。
于就有很多研究针对如何加快采样来减少推理时间的方法,通常就是我们说的Sampling method, 比如DPM++SDE等
扩散模型涉及到几个重要的概念:
- 步长Step:
- 采样策略:
一张图总结下VAE、GAN和Diffusion Model的区别
Stable Diffusion
从上面可知,Diffusion扩散模型是一个简单且高效的生成式模型。但是离本次要讲的文生图还有一定差别。
还差的环节是文本如何添加到扩散模型里。如果有一个模型可以很好的匹配文本和图像,就可以文本生成的图像向量作为额外的条件加到扩散模型里(有条件的扩散模型)
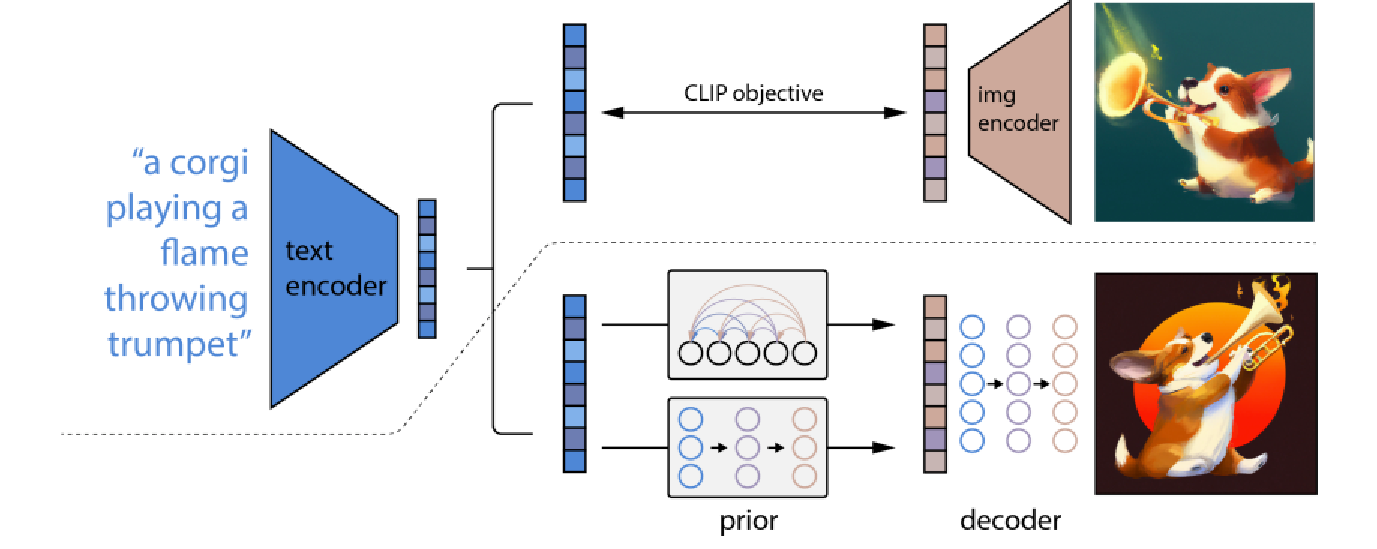
这个模型就是CLIP模型,CLIP模型是典型的多模态的对比学习模型,通过文本和图像的配对数据,分布对文本和图像进行编码,优化两者向量的相似度,使得配对的两向量相似度最大。

OPENAI的DALE-2利用clip生成文本和图像向量配对,训练一个文本映射到图像向量的模型,得到图像向量模型,在通过diffusion模型生成图片,达到文生图的目的。
而Stable Diffusion有些不同,总体的流程见下图,不同之处在于:
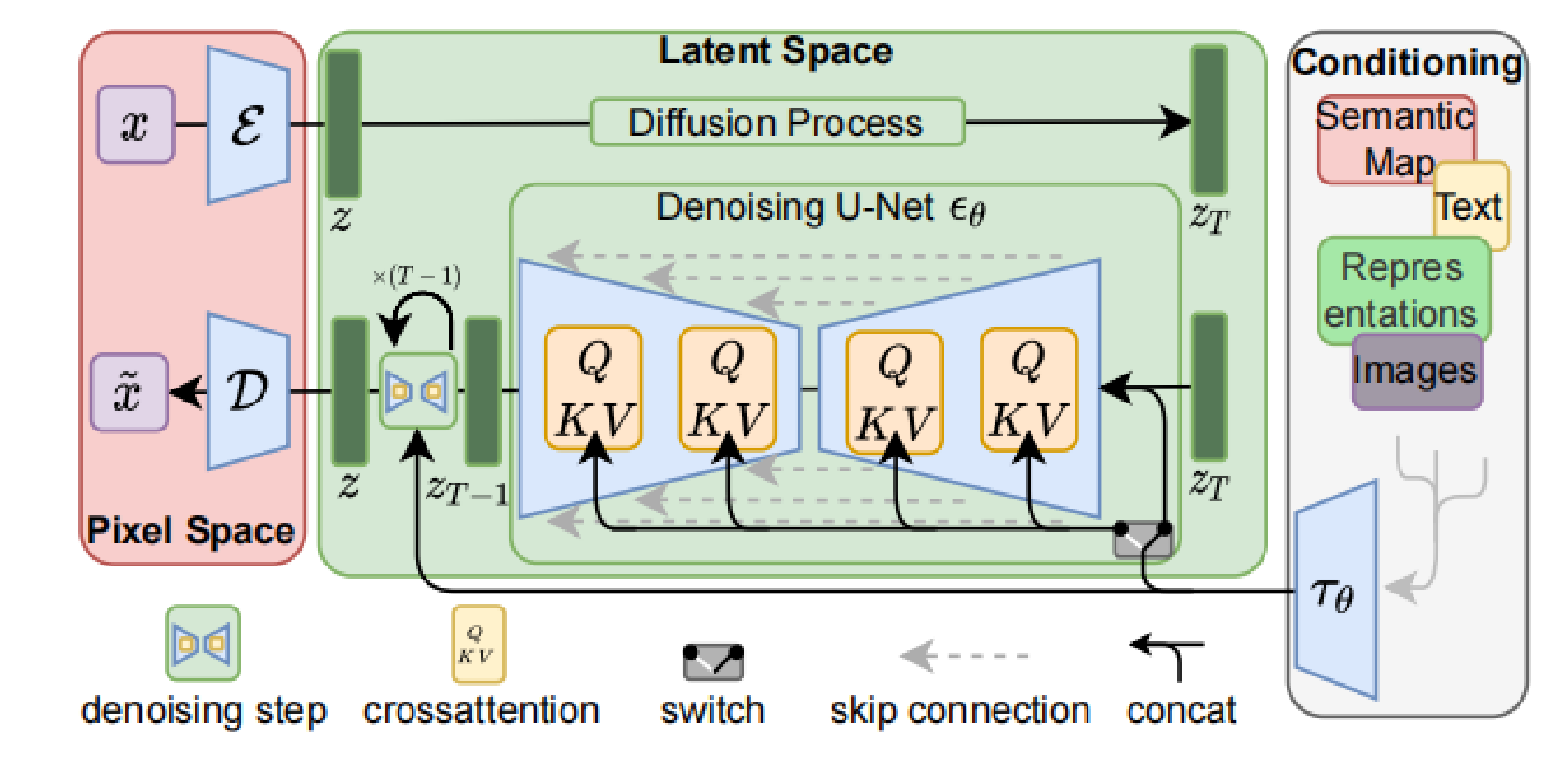
- 最右边是条件输入,可以引导模型生成的结果,针对文生图,先用预训练模型将文本转换text token embedding,预训练模型可以是CLIP也可以是其他GPT模型
- 为了融合图通的条件输入,采用一个cross attention的方式添加到Diffusion去噪过程中
- 另外一个不同是:diffusion的模型输入是图像尺寸大小,这样推理速度较慢。Stable Diffusion将输入改成图像的一个潜在空间的向量表示。那怎么将图像转换为向量表示呢?答案是VAE。也就是上图中最左边,预训练一个VAE模型,将图像encode潜在空间表示,经过diffusion去噪过程,得到一个恢复的潜在变量,经过一个decode恢复成图像。

参考资料
- https://zhuanlan.zhihu.com/p/620714629
- https://stable-diffusion-art.com/how-stable-diffusion-work/
- http://jalammar.github.io/illustrated-stable-diffusion/
- High-Resolution Image Synthesis with Latent Diffusion Models