引言
通义实验室XR实验室重磅开源文生3D新模型,能够从一句文本描述构建3D模型及对应纹理,目前已经在Github面向外界开源!与该项技术一起开源的,还有通义实验室推出的Text-to-ND(文本生成深度、法向图)、Text-to-ND-MV(文本生成多视角的深度、法向图)两个大模型。我们先来直观感受一下这两个大模型的魔法能力:
Text-to-ND大模型:

Text-to-ND-MV大模型:

为了满足不同开发者的需求,通义实验室XR实验室开源了Text-to-ND的基础版本以及Multi-View版本,满足不同细粒度的算法开发需求。不仅如此,还同步开源了从大模型中蒸馏出(Score Distillation Sampling) 3D模型的优化代码,串联可以完成文本直接到3D模型的生成。
Text-to-3D效果:

目前,魔搭社区提供一站式体验、下载、推理、训练教程,欢迎开发者小伙伴体验!
模型效果体验
ModelScope提供了创空间在线体验算法:
创空间体验链接:https://modelscope.cn/studios/Damo_XR_Lab/3D_AIGC/summary
模型下载
模型链接:
Text-to-ND、Text-to-ND-MV大模型:
https://modelscope.cn/models/Damo_XR_Lab/Normal-Depth-Diffusion-Model/summary
模型下载:
# 以linux系统为例 git clone https://github.com/modelscope/normal-depth-diffusion cd normal-depth-diffuison && python tools/download_models/download_nd_models.py
模型推理
Text-to-ND、Text-to-ND-MV大模型推理:
# 模型下载 git clone https://github.com/modelscope/normal-depth-diffusion cd normal-depth-diffuison && python tools/download_models/download_nd_models.py # 安装依赖 conda create -n nd conda activate md pip install -r requirements.txt pip install git+https://github.com/openai/CLIP.git pip install git+https://github.com/CompVis/taming-transformers.git pip install webdataset pip install img2dataset # 或者使用dockerfile sudo docker build -t mv3dengine_22.04:cu118 -f docker/Dockerfile . # 进行推理 python demo_inference.sh
资源消耗:
Text-to-ND(512x512):

Text-to-ND-MV(256x256):

Text-to-3D模型推理:
## 代码及依赖项 git clone https://github.com/modelscope/RichDreamer.git --recursive cd RichDreamer conda create -n rd conda activate rd # install dependence of threestudio pip install -r requirements_3d.txt # Text-to-ND、Text-to-ND-MV模型下载 python tools/download_models/download_nd_models.py # 拷贝256分辨率的DMTet资源文件 cp ./pretrained_models/Damo_XR_Lab/Normal-Depth-Diffusion-Model/256_tets.npz ./load/tets/ # 下载SD1.5及SD2.1(/path/to/${download_sd}是models_sd.tar.gz的本地地址) bash prepare_sd_models.sh ## NeRF表达的推理 # 单张A100-80GB,Quick Start python3 ./run_nerf.py -t $prompt -o $output # 推理所有Prompts # 例如 bash ./scripts/nerf/run_batch.sh 0 1 ./prompts.txt bash ./scripts/nerf/run_batch.sh $start_id $end_id ${prompt.txt} # 如果没有80GB VRAM的A100, 我们提供了一个24GB VRAM的inference脚本 # 可以在单张3090/4090进行推理. python3 ./run_nerf.py -t $prompt -o $output -s 1 ## DMTet表达的推理 # 单张A100-80GB,Quick Start python3 ./run_dmtet.py -t $prompt -o $output # 推理所有Prompts # e.g. bash ./scripts/dmtet/run_batch.sh 0 1 ./prompts.txt bash ./scripts/dmtet/run_batch.sh $start_id $end_id ${prompt.txt} # 如果没有80GB VRAM的A100, 我们提供了一个24GB VRAM的inference脚本 # 可以在单张3090/4090进行推理. # 例如 bash ./scripts/dmtet/run_batch_fast.sh 0 1 ./prompts.txt bash ./scripts/dmtet/run_batch_fast.sh $start_id $end_id ${prompt.txt}
模型训练
Text-to-3D是基于Text-to-ND、Text-to-ND-MV的优化算法,我们提供Text-to-ND、Text-to-ND-MV的模型训练步骤。
数据准备:
## 下载 Laion-2B-en-5-AES(训练ND模型) # 从https://huggingface.co/datasets/laion/laion2B-en 下载filelist # 将该文件放在 ./laion2b-dataset-5-aes 路径下 cd ./tools/download_dataset bash ./download_2b-5_aes.sh cd - ## 下载Objaverse多视角数据 # 从我们的分享链接下载objaverse_dataset, 上传需要大量时间 # 上传完毕我们会在https://github.com/modelscope/normal-depth-diffusion更新数据链接 ln -s /path/to/objaverse_dataset mvs_objaverse
深度估计及法向估计预训练模型准备:
# 法向估计模型 # https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/RichDreamer/scannet.pt # 深度估计模型 # https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/RichDreamer/dpt_beit_large_512.pt mv /path/to/scannet.pt ./libs/ControlNet-v1-1-nightly/annotator/normalbae/scannet.pt mv /path/to/dpt_beit_large512.pt ./libs/omnidata_torch/pretrained_models/dpt_beit_large_512.pt
开始训练:
## 训练ND-VAE # 下载预训练权重 wget https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/RichDreamer/nd-vae-imgnet.ckpt # 修改config文件 configs/autoencoder_normal_depth/autoencoder_normal_depth.yaml model.ckpt_path=/path/to/nd-vae-imgnet.ckpt # 训练启动 bash ./scripts/train_vae/train_nd_vae/train_rgbd_vae_webdatasets.sh \ model.ckpt_path=${pretained-VAE weights} \ data.params.train.params.curls='path_laion/{00000..${:5 id}.tar' \ --gpus 0,1,2,3,4,5,6,7 ## 训练ND-Diffusion # 训练完成ND-VAE之后,使用训练好的权重或者下载我们训练的版本 # https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/RichDreamer/nd-vae-laion.ckpt # 步骤一 export SD-MODEL-PATH=/path/to/sd-1.5 bash scripts/train_normald_sd/txt_cond/web_datasets/train_normald_webdatasets.sh --gpus 0,1,2,3,4,5,6,7 \ model.params.first_stage_ckpts=${Normal-Depth-VAE} model.params.ckpt_path=${SD-MODEL-PATH} \ data.params.train.params.curls='path_laion/{00000..${:5 id}.tar' # 步骤二 修改 ./configs/stable-diffusion/normald/sd_1_5/txt_cond/web_datasets/laion_2b_step2.yaml # 中的model.params.ckpt_path 为第一步的权重地址。 bash scripts/train_normald_sd/txt_cond/web_datasets/train_normald_webdatasets_step2.sh --gpus 0,1,2,3,4,5,6,7 \ model.params.first_stage_ckpts=${Normal-Depth-VAE} \ model.params.ckpt_path=${pretrained-step-weights} \ data.params.train.params.curls='path_laion/{00000..${:5 id}.tar' ## 训练Multi-View的ND-Diffusion # 在训练完成ND-Diffusion之后得到预训练权重,或者下载我们训练的版本: # https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/RichDreamer/nd-laion.ckpt # 训练Multi-View的ND-Diffusion有两种训练方式,在latent-space计算loss以及经过VAE解码计算loss # 目前版本我们提供latent-space计算loss的预训练模型,开发者也可以自己尝试训练经过VAE解码计算loss的版本 # 不经过VAE解码的版本 bash ./scripts/train_normald_sd/txt_cond/objaverse/objaverse_finetune_wovae_mvsd-4.sh --gpus 0,1,2,3,4,5,6,7, \ model.params.ckpt_path=${Normal-Depth-Diffusion} # 经过VAE解码的版本 bash ./scripts/train_normald_sd/txt_cond/objaverse/objaverse_finetune_mvsd-4.sh --gpus 0,1,2,3,4,5,6,7, \ model.params.ckpt_path=${Normal-Depth-Diffusion}
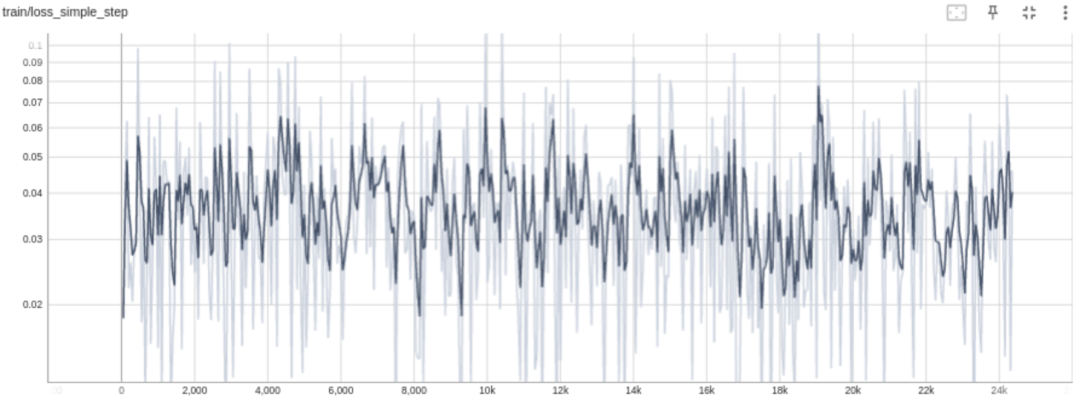
训练曲线:
Text-to-ND:
Text-to-ND-MV:

欢迎Star相关开源仓库:
点击了解模型详情:modelscope.cn/models/Damo_XR_Lab/Normal-Depth-Diffusion-Model/summary
