一、物理架构
物理架构 - 企业大数据系统的各层次系统最终要部署到主机节点中,这些节点通过网络连接成 为一个整体,为企业的大数据应用提供物理支撑 ,企业大数据系统由多个逻辑层组成,多个逻辑层可以映射到一个物理节点上,也可以映射到多个物理节点上
在映射时需要考虑三个方面的问题:一是是否容易识别,二是是否足够集约,三是是否能够同构
二、集成架构
集成架构 - 企业大数据系统由多个系统集成而成,每个系统都提供了多种协议和接口, 以便企业大数据系统的内部系统间集成和外部系统与大数据系统的集成
企业大数据系统的集成可以分为总体集成和专项集成,总体集成是指各组成系统间的集成,通过总体集成可以构成高校,可靠,安全运行的企业大数据系统,若企业大数据系统之外的某个应用系统或大数据系统之内的某个应用系统只想与存储系统,调度系统等进行集成,那么可通过调用这些系统开放的接口来实现,这种集成方式就是专项集成
三、安全架构
安全架构 - 由于企业大数据系统的数据资源和计算资源广泛地分布在多个节点上,所以用户的 身份、权限等安全,数据资源的存储、传输、访问等安全,以及计算资源的访问、监控、调整、恢复等安全,都是企业大数据系统在进行安全架构设计时需要考虑的问题
一般来讲,企业大数据的安全架构由针对三层的安全设计构成,这三层分别是用户层,应用层和数据层,针对每一层的关键行为加入安全因素的设计,以确保系统的整体安全
四、阿里云飞天系统体系架构
飞天(Apsara)是由阿里云自主研发、服务全球的超大规模通用计 算操作系统
它可以将遍布全球的百万级服务器连成一台超级计算机、以在线公共服务的方式为社会提供计算能力
7年过去,飞天已经为全球200多个国家和地区的创新创业企业、政府、机构等提供服务
阿里云飞天整体架构 - 飞天平台的体系架构如图所示,整个飞天平台包括飞天内核和飞天开发服务两大部分
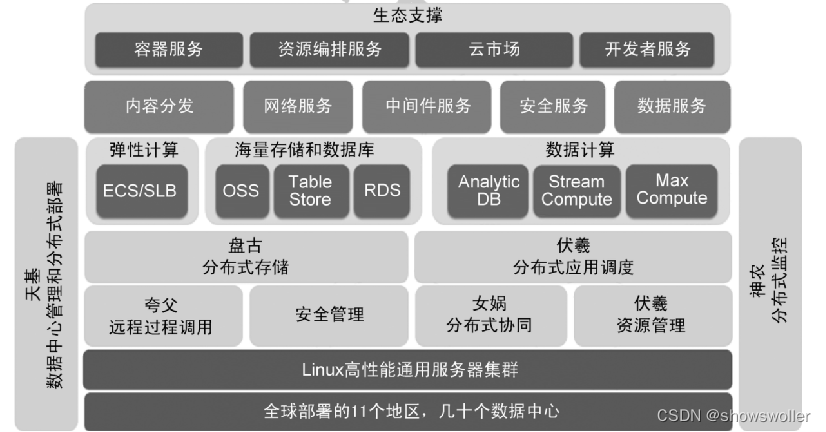
飞天管理着互联网规模的基础设施。其最底层是遍布全球的几十个数据中心和数百个PoP节点
飞天内核跑在每个数据中心里面,它负责统一管理数据中心内的通用服务器集 群,调度集群的计算、存储资源,支撑分布式应用的部署和执行
安全管理根植在飞天内核最底层。飞天内核提供的授权机制能够有效实现“最小权限原则 (principle of least privilege)”,同时还建立了自主可控的全栈安全体系
监控报警诊断是飞天内核最基本的能力之一。飞天内核对上层应用提供了非常详细的、无间断的监控数据和系统事件采集
在基础公共模块之上有两个最核心的服务,一个叫盘古,一个叫伏羲
天基是飞天的自动化运维服务,负责飞天各个子系统的部署、升级、扩容以及故障迁移
阿里云飞天平台内核可以分成以下几个部分
分布式系统底层服务 - 其提供分布式环境下所需要的分布式协调服务、远程过程调用服务、安全管理、分布式资源调度等功能
盘古分布式文件系统 - 盘古(Pangu)是一个分布式文件系统, 盘古系统 的设计目标是将大量通用机器的存储资源聚合在一起,为用户提供大规模、高可靠、高可用、高吞吐量和可扩展的存储服务
伏羲任务调度系统 - 该系统为集群中的任务提供调度服务,同时支持强调响应速度的在线 服务(Online Service)和强调处理数据吞吐量的离线任务(Batch Processing Job)
集群监控和部署 - 神农(Shennong )是飞天平台内核中负责信息收集 、监控和诊断的模块,大禹 (Dayu)是飞天内核中负责提供配置管理和部署的模块
飞天开放服务
包括弹性计算 (ECS)、阿里云对象存储(OSS)、表格存储服 务(Table Store)、关系型数据库服务(RDS)、流式计算服务 (Stream Compute)和大数据计算服务(MaxCompute)等
弹性计算 (ECS) - 云服务器ECS(Elastic Compute Service)是一种云计算服务 , 它的管理方式比物理服务器更加简单、高效
阿里云对象存储(OSS) - 阿里云对象存储 (Object Storage Service, OSS)是阿里云对外提供的海量、安全、低成本、高可靠的云存储服务
表格存储 (Table Store) - 它是构建在阿里云飞天分布式系统之上的NoSQL数据存储服务,提供海量结构化数据的存储和实时访问
大数据计算服务(MaxCompute) - 大数据计算服务(MaxCompute,原名 ODPS)是一种快速、完全托管的TB/PB级数据仓库解决方案
阿里云飞天 OpenStack 和 Hadoop 的不同
OpenStack和 Hadoop是软件,它们并没有解决客户的CAPEX 投入问题、运维人员投入问题,需要部署到自有的硬件上,一般只用于单个企业的内部环境
飞天上面提供了基于 Hadoop、EMR、Mongo等开源软件的托管服务,这是飞天开放 能力的体现
阿里云飞天与 VMware 、华为 FusionSphere 的不同
虚拟化不等于云计算,云的实时在线、海量弹性、多租户隔离、专业运维都是传统虚拟化软件所欠缺的
VMware的三大件主要解决了计算的效率问题,但是没有解决计算的规模问题
华为的 FusionSphere 其实是基于开源软件进行定制并适配华为硬件的软件系统,飞天内核在规模、性能、稳定性和通用性上都超越了 FusionSphere
五、主流大数据厂商
Cloudera
Cloudera是一家专业从事基于Apache Hadoop的数据管理软 件销售和服务的公司 , 它发布的实时查询开源项目Impala比基于 MapReduce的HiveSQL的查询速度提升了3~90 倍

Hortonworks
Hortonworks的开放式互联平台帮助企业管理所拥有的数据(动态数据以及静态 数据),为用户组织启用可操作情报。

Amazon
Amazon 的 AWS 本身就是最完整的大数据平台, Amazon Web Services 提供了一系列广泛的服务,可以快速 、轻松地构建和部署大数据分析应用程序

Google提出的 MapReduce计算框架在很多大数据领域得到了非常广泛的应用

微软
微软推出的商业数据分析系统 Microsoft Analytics Platform System 能够通过其扩充的大规模平行处理整合式系统支持混合格式的数据仓库,借此适应数据仓库环境不断发展的需求

阿里云数加平台
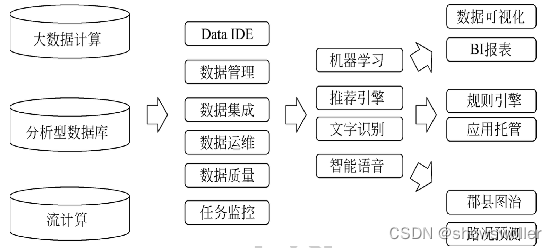
数加是阿里云为企业大数据的实施提供的一套完整的一站式大数据解决方案,
数加平台由大数据计算服务(MaxCompute)、分析型数据库(Analytic DB)、流计算 (StreamCompute)共同组成了底层强大的计算引擎, 速度更快, 成本更低

创作不易 觉得有帮助请点赞关注收藏~~~

