kubernetes GPU的困境和破局
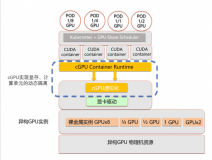
随着人工智能与机器学习技术的快速发展,在 Kubernetes 上运行模型训练、图像处理类程序的需求日益增加,而实现这类需求的基础,就是 Kubernetes 对 GPU 等硬件加速设备的支持与管理。
kubernetes 调度 GPU-使用篇
Kubernetes 支持对节点上的 AMD 和 NVIDIA GPU (图形处理单元)进行管理,目前处于实验状态。
在 GPU 的支持上,最基本的诉求其实非常简单:我只要在 Pod 的 YAML 里面,声明某容器需要的 GPU 个数,那么 Kubernetes 为我创建的容器里就应该出现对应的 GPU 设备,以及它对应的驱动目录。
以 NVIDIA 的 GPU 设备为例,上面的需求就意味着当用户的容器被创建之后,这个容器里必须出现如下两部分设备和目录:
- GPU 设备,比如
/dev/nvidia0;- GPU 驱动目录,比如
/usr/local/nvidia/*。
其中,GPU 设备路径,正是该容器启动时的 Devices 参数;而驱动目录,则是该容器启动时的 Volume 参数。
所以,在 Kubernetes 的 GPU 支持的实现里,**kubelet 实际上就是将上述两部分内容,设置在了创建该容器的 CRI (Container