
为了更好的方便各位开发者和用户了解并应用ECS倚天实例,由阿里云弹性计算联合基础软件团队 & 平头哥 & 安谋科技(Arm China)等十余位专家、架构师、开发工程师等,共同发起的【倚天实例迁移课程】正式上线,本次系列课程共计10节,共分为基础篇,架构迁移篇,性能优化篇等三个篇章,从不同角度为用户带来更加丰富和专业的讲解。
2023年8月15日,系列课程第二节《Arm Neoverse 软件生态介绍》正式上线,由安谋科技(Arm China)高级软件经理别再平主讲,内容涵盖:Arm Neoverse 介绍,Arm Neoverse 软件生态系统,Arm Neoverse 软件迁移,本期节目在阿里云官网、阿里云微信视频号、阿里云钉钉视频号、InfoQ官网、阿里云开发者微信视频号、阿里云创新中心直播平台&微信视频号同步播出,同时可以点击【/topic/ecs-yitian】进入【倚天实例迁移课程官网】了解更多内容。
以下内容根据别再平的分享整理而成,供读者阅览:
- Arm Neoverse介绍
首先,我们一起了解一下Arm Neoverse平台。2018年,Arm战略性地将客户端芯片设计与服务器芯片设计分离,推出了专为数据中心而设计的Neoverse平台。

Neoverse平台涵盖了三个系列的产品,主要聚焦在基础设施市场,并已在数据中心、云计算、5G数据传输以及边缘计算等领域得到广泛应用,构成了未来智能终端设备发展的基础。
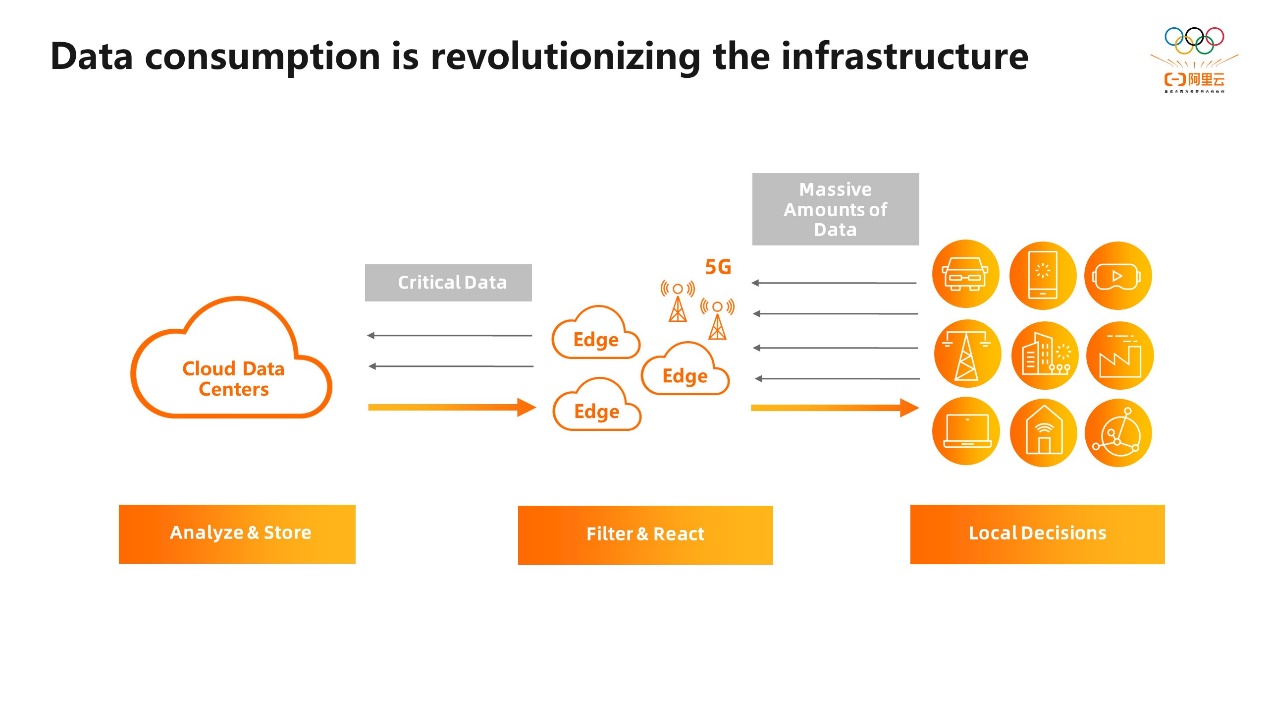
随着智能产业的迅速发展,全球智能终端设备规模预估也正呈指数级增长,而这些设备将产生海量数据,向上游传输并等待处理。针对快速响应、传输延迟、成本以及数据安全性等问题,通过将数据处理设备部署在网络边缘可有效解决这些问题,这就是所谓“边缘计算”的概念,而在边缘计算这一领域中,Neoverse 已被广泛应用,这也再次突显了 Neoverse 平台的高可用性和高可扩展性。
Arm从设计之初就考虑了从数据中心到云计算再到边缘计算的各种场景,确保在不同场景中使用相同的CPU核心。通过相同的CMN互联总线、中断控制器、MMU等IP,可以集成不同的CPU规格,例如4至8个核心的小芯片,或集成64至128个核心的大芯片。
这种设计策略允许高规格的CPU核心应用于数据中心和云计算,而较低规格的CPU核心适用于边缘计算、5G接入等场景,以满足不同应用需求。
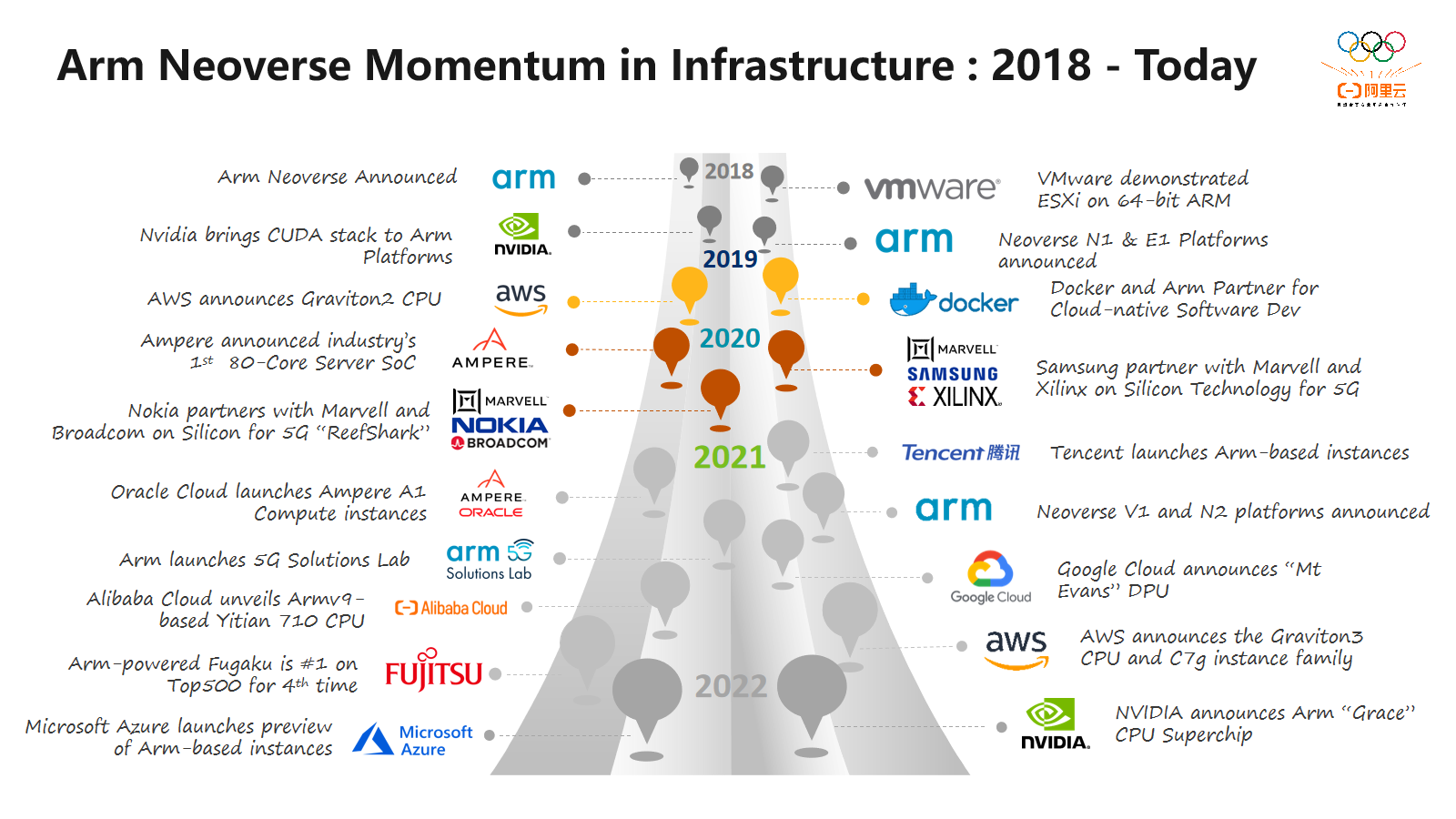
自2018年Arm发布Arm Neoverse平台以来,基于该平台的CPU已被广泛部署于国内外数据中心。阿里云、腾讯云、AWS、微软、谷歌等公司在过去几年内发布了基于Arm架构的云实例。
2021年,阿里云正式发布了基于 Armv9 架构的倚天710的云实例。在智能网卡领域,Marvell发布了新型DPU,谷歌云与英特尔合作发布了基于 Neoverse 平台的DPU。在企业领域,惠普发布了基于 Arm 架构的 ProLiant十一代平台,表示基于 Arm 架构的芯片已进入传统企业数据中心领域。生态系统方面,Nvidia宣布Cuda软件栈,正式支持Arm架构。
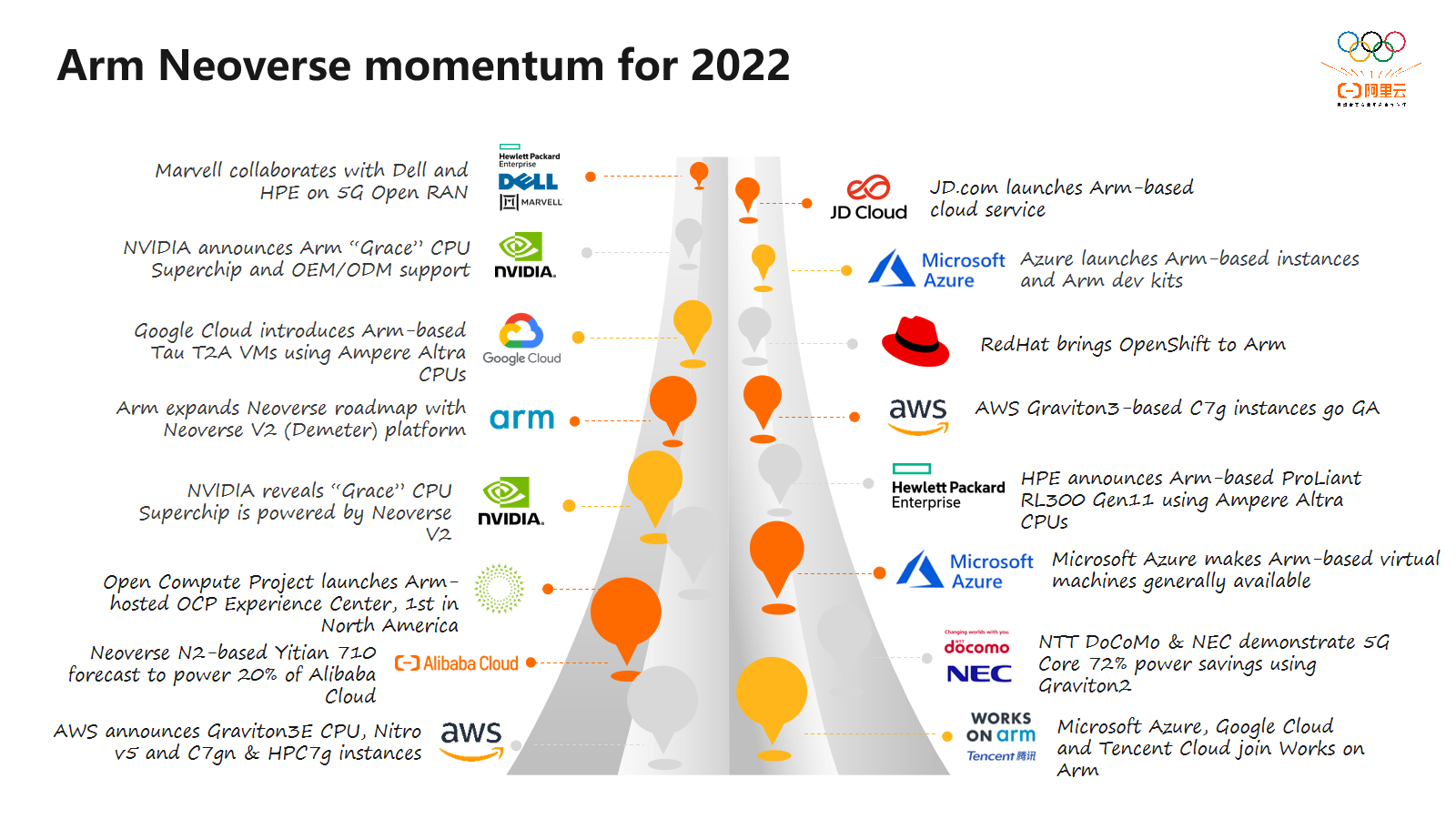
最后,为了确保最终客户能够方便使用采用Arm架构的系统,Arm提出了 SystemReady 认证项目,对基于 Arm 架构的系统硬件和固件进行认证测试,确保通过认证的系统能自由安装操作系统。此认证项目在推出两年以来,已有近100个系统获得认证。这一页总结了2022年Neoverse平台的重要进展。在云、数据中心和网络等领域,Neoverse平台已得到广泛部署。
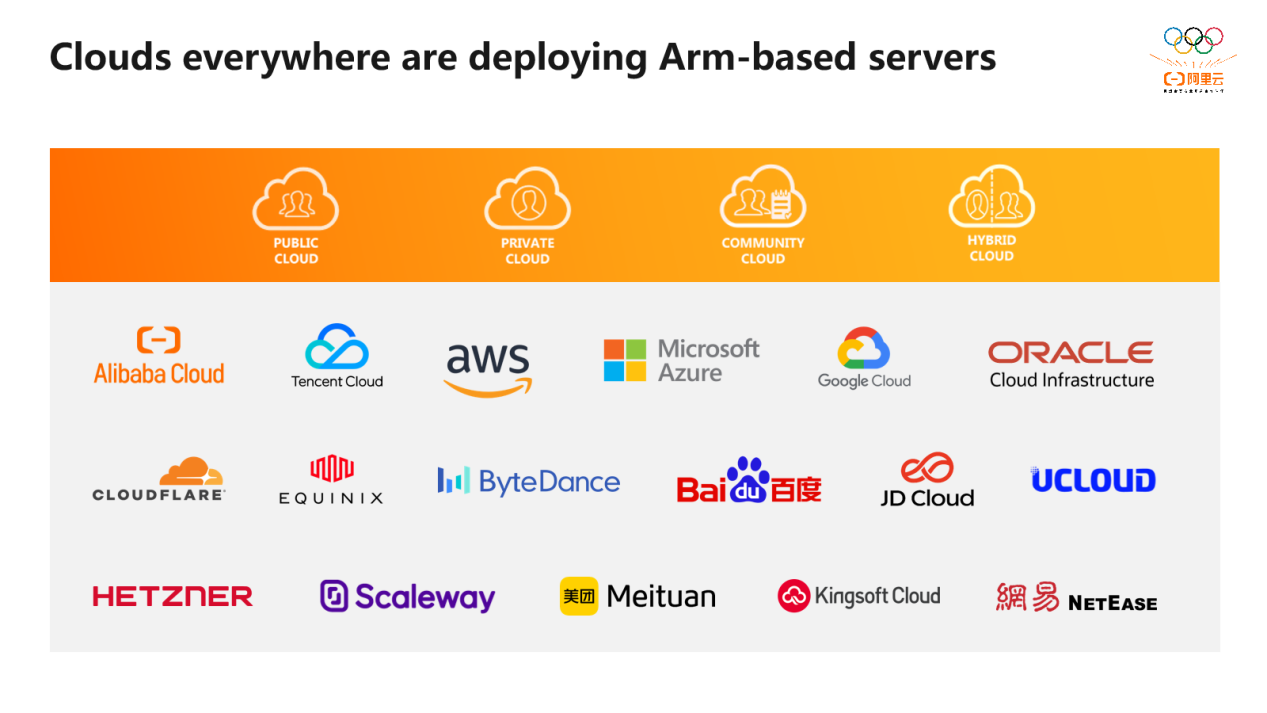
聚焦于云计算产品市场,由于 Neoverse 平台在可扩展性和功耗方面具有领先的优势,Arm 的生态伙伴可以自由创新。Arm 服务器应用范围涵盖了公有云、私有云、混合云等领域。自2018年起,基于 Neoverse 平台的CPU 已被国内主流云服务提供商广泛采用。从图中可看出,国内外诸多云服务提供商,如阿里云、亚马逊、谷歌、微软等,已发布基于Arm架构的云实例或在自身云环境中部署Arm服务器。
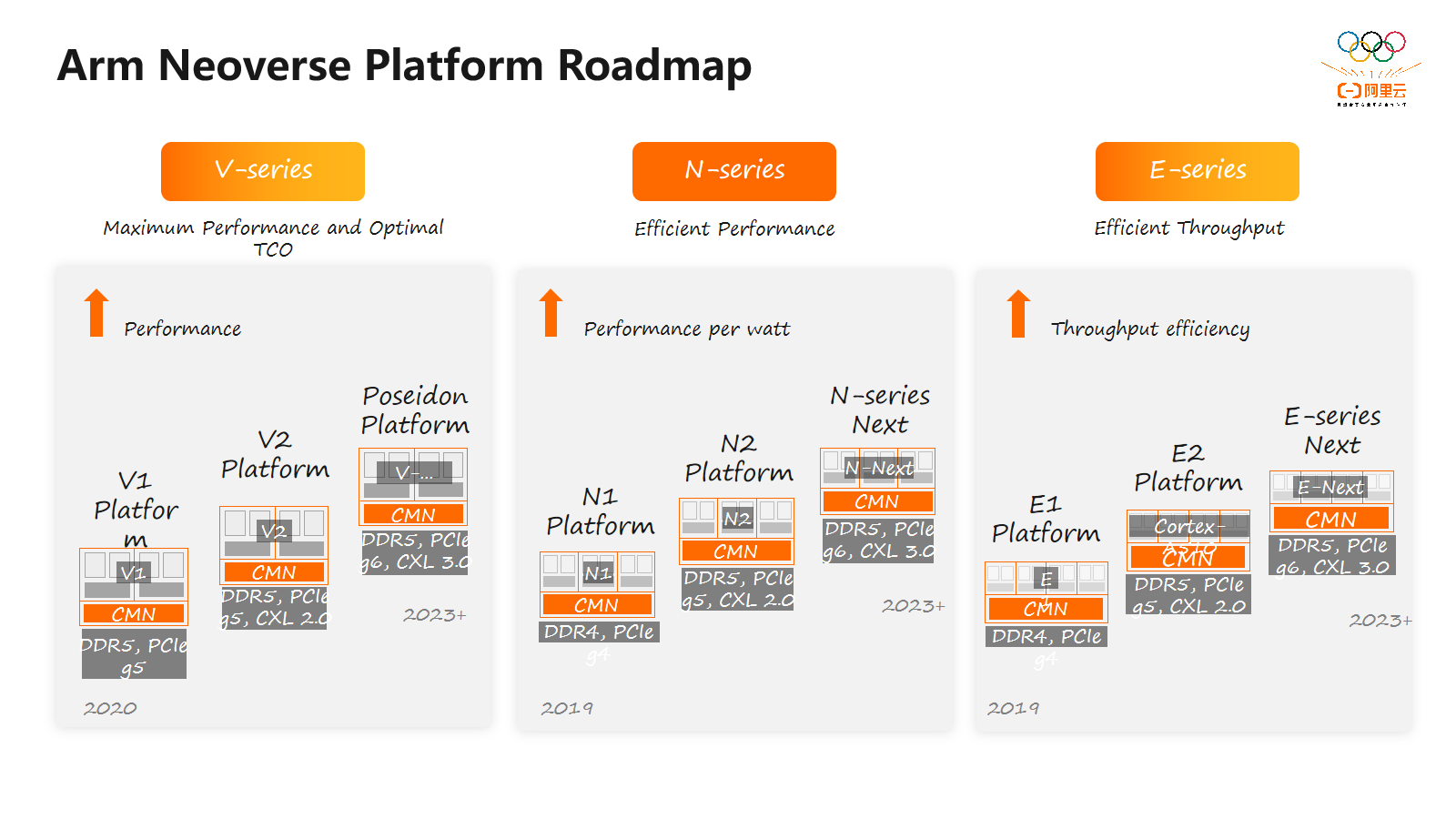
接下来,我们一起了解一下 Arm Neoverse 平台的路线图。该平台分为V系列、N系列和E系列三大系列。V系列注重性能,单核心单线程性能优越,适用于高性能计算和数据中心云计算。N系列注重功耗、性能与面积的平衡,CPU核心扩展性强,适用于数据中心云计算至边缘计算等多个领域。E系列侧重功耗和面积,主要应用于无线接入等功耗受限的场景。接下来,我们将介绍几个关键的Neoverse 产品。
首先,是2019年推出的Neoverse N1,这是首款聚焦基础设施特性的CPU核心。与之前的Cortex-A72相比,Neoverse N1整数计算性能提高了60%,并具有出色的能效比。基于Neoverse N1的芯片已在云服务提供商部署,如AWS和谷歌云。
其次是Neoverse V1,它增加了对256位SIMD引擎的支持,支持BF16等数据类型。相比Neoverse N1,Neoverse V1的计算性能提高了50% 以上,单线程处理能力强,专为数据中心云计算和高性能计算而设计。
接下来是Neoverse N2,这也是Neoverse平台中首个支持Armv9架构的CPU核心,支持2×128位SIMD引擎,单线程处理能力比Neoverse N1提高了40%以上。同时继承了Neoverse N1的高能效比,适用于超大规模数据中心的云计算。阿里的倚天710芯片便是采用Neoverse N2核心而设计,性能卓越。
- Arm Neoverse软件生态系统

接下来我们将为大家介绍Arm生态系统的概况。Arm是一个持续致力于开源的公司,并与各软件生态系统中的合作伙伴保持着深入的合作。目前,我们为云原生软件领域的100多个开源项目提供支持。其中包括许多大家熟知的软件项目,概述如下:
首先,在操作系统领域,无论是官方发行版还是社区版,都为基于Arm架构的系统提供了良好支持。主流的操作系统发行版都宣布对Arm系统的正式支持。社区版操作系统中,包括国内诸如龙蜥等,都原生支持Arm64系统。
从底层软件到上层,我们支持多种关键技术,如虚拟化的KVM,各种网络应用等。在编程语言方面,主流的编程语言如C、C++、Java和Python都在Arm架构上得到了良好支持。

Arm 同时也在编译器方面持续投入。此外,我们还支持各种计算、加速库,例如压缩库(如snappy、lz4)、加解密库(如open ssl、isa-l),以及视频编解码库(如h264、h265)。
Arm在软件工程方面拥有专业团队,能直接进行这些库的优化工作。此外,我们还支持多种工作负载,如数据库(如PostgreSQL)、缓存和网页服务器,大数据框架(如Spark、Hadoop)等。
经过多年的持续投入和与业界的紧密合作,Arm生态系统为Arm64架构和Arm服务器提供了广泛的支持。由于背靠Arm生态系统,开发者可以直接使用大多数主流开源应用,无需进行迁移,从而节约开发和部署成本。
在多年的持续投入下,Arm架构的软件生态系统取得了显著成就。超过100个开源项目已经正式支持Arm架构,并支持原生构建。此外,约有100多家独立软件供应商为Arm架构提供商业支持。在容器领域,支持Arm架构的Docker镜像数量超过10万个,可供免费下载使用。针对Arm架构进行的CI/CD构建时间已超过每月100万分钟。
此外,主流的云服务提供商针对基于Arm架构的实例提供了软件优化和支持,为用户提供了强大的生态环境。
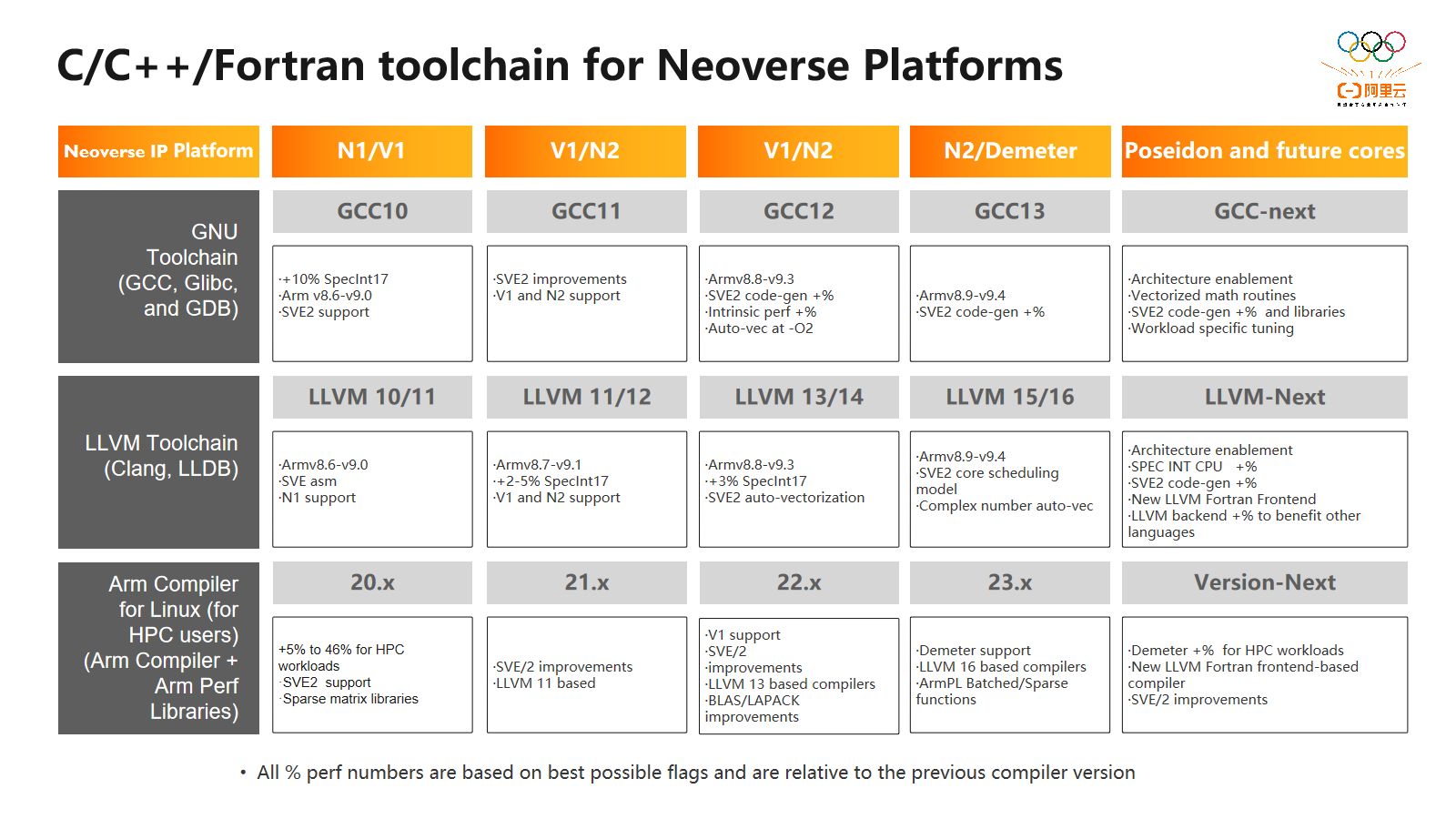
接下来,我们将关注编译器领域,这是Arm持续投入的重点领域。Arm在编译器领域承诺进行持续的开发、并投入资源和给予支持,以确保在硬件系统面世之前,各种架构特性和CPU微架构特性在编译器中得到支持。
随着编译器版本的不断更新,新的架构特性,如原子操作和向量化计算SVE(Scalable Vector Extension)支持,将陆续添加,以生成最优化的目标代码。此外,更新的编译器版本不仅支持架构特性,还带来对更新的微架构的支持,例如对特定CPU架构(如Neoverse N1和Neoverse N2)的支持。这使得开发者在构建目标代码时可以使用简化的编译选项,以获得最优化的结果输出。
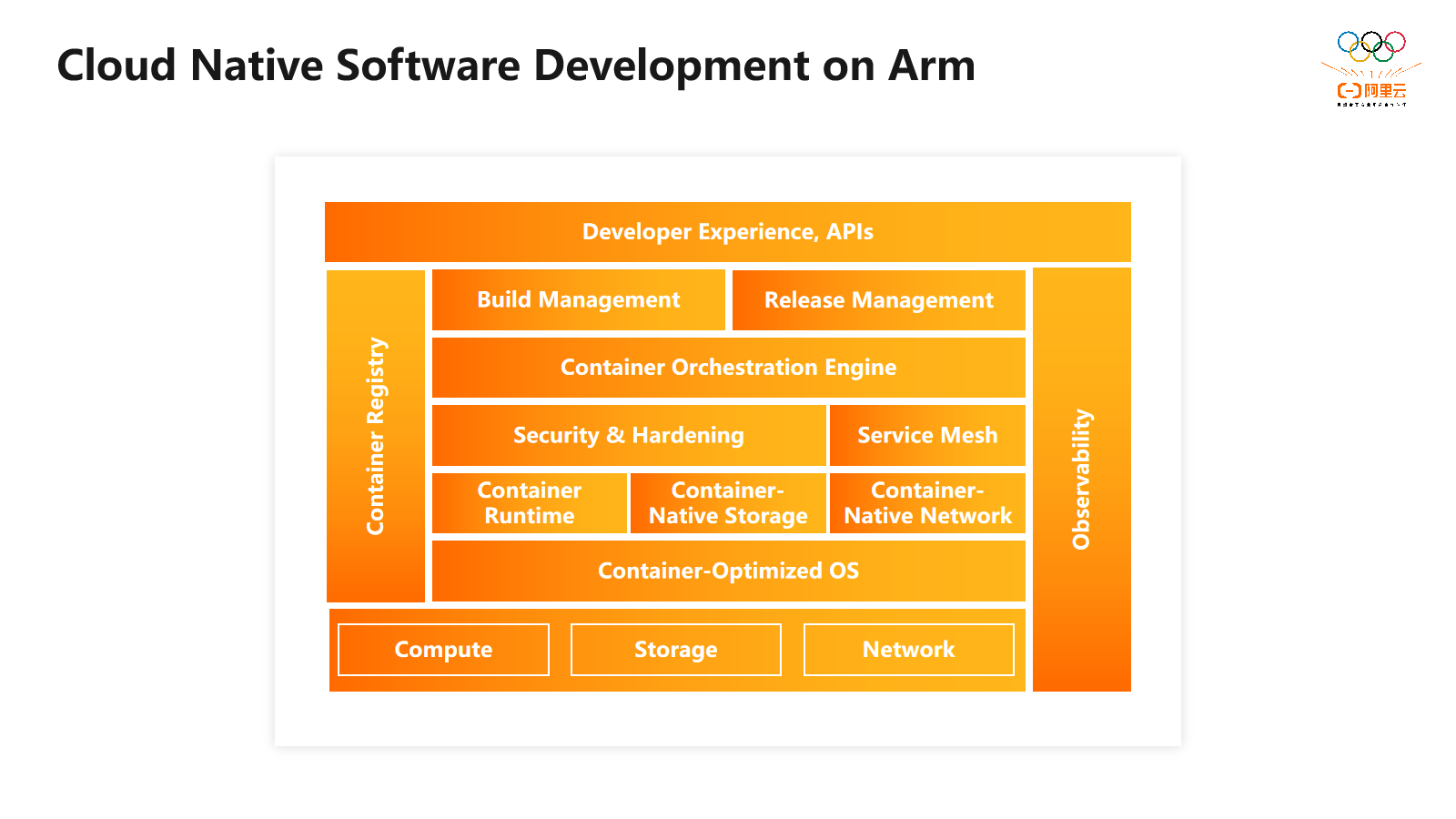
在下一页中,我们将介绍Arm架构在云原生软件栈的支持情况。云原生软件栈基于微服务容器构建,为在云上部署现代化应用提供基础。在软件栈的不同层面上,Arm架构得到良好支持。从服务支持的最底层开始,涵盖计算、存储和网络,专门针对容器优化的操作系统(如Centos、Ubuntu和k3os等)也对Arm架构提供了正式支持。
容器运行时管理容器的生命周期,并在操作系统与上层应用之间充当桥梁。常见的容器运行时,如Docker和各种安全容器,以及轻量级虚拟机方案,都支持Arm架构。
云原生网络方面有几个主流的开源项目,Arm在这些项目上有直接的软件开发与投入, 例如Flannel、Calico、Cilium。微服务中的核心项目和服务网格(Istio和linkerd)也原生支持Arm架构,支持开箱即用,可轻松部署。这使得开发者能够方便地利用这些项目,在Arm系统或Arm云实例上部署应用。
在可观测性方面,最终用户可以使用Datadog、Grafana等主流监控系统,对运行时产生的数据进行代码级的可视化操作和分析。总之,云原生软件栈的主流开源软件项目都支持Arm架构。
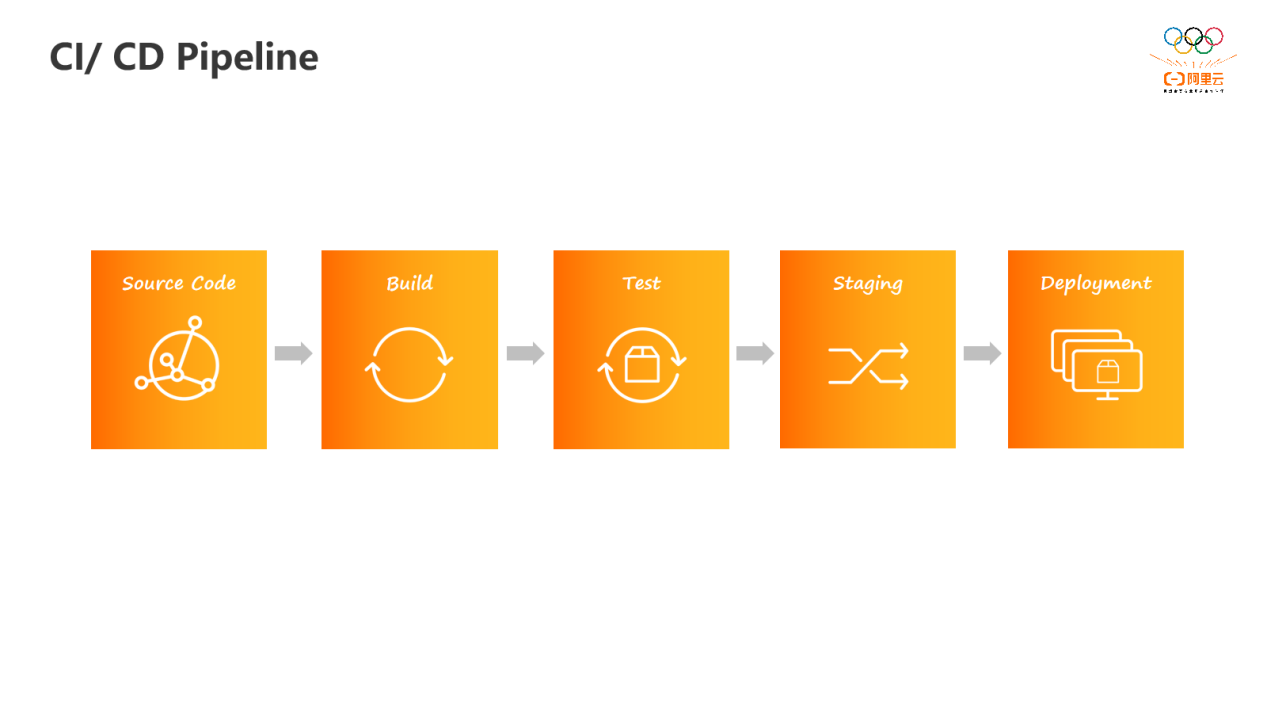
接下来我们将讨论持续集成与持续交付(CI/CD)的重要性,以及其在云原生软件领域的关键作用。CI/CD是软件开发流程中的一种方法论,它可以分解为多个阶段,包括源代码管理、代码构建、自动化测试、暂存验证环境和部署等。一旦经过这些步骤,开发者编写的程序就可以直接部署到生产系统,为客户正式提供服务。
在软件迁移方面,CI/CD的支持至关重要。只有通过有效的CI/CD流程,整个软件开发、测试和部署链条才能无缝地协同工作。在CI/CD方面,我们与生态伙伴进行了深入的合作,确保其在Arm架构上获得原生的支持。无论是托管在云上还是自行搭建的CI/CD工具,包括各种操作与工具,都对Arm架构提供了完全的支持。
经过实际测试,我们发现将CI/CD工作负载部署在基于Arm架构的服务器实例上,相较于传统的x86架构实例,可以获得更好的性价比。具体来说,基于Arm架构的实例在编译构建阶段可以缩短约30%至40%的时间,并且可以节约至少20%的成本支出。这一实测结果表明,选择基于Arm架构的服务器实例进行CI/CD托管是一个具有实际效益的决策。
下面我们将详细介绍Arm对整个开发者生态的支持。其中包括Arm与相关社区和生态合作伙伴的合作。他们共同推出了面向开发者的Arm Developer Program。该计划的主要目标是建立一个统一且稳健的框架,以支持最终开发者的一致性体验。该计划还包括有Arm开发者网站(developer.arm.com)以及各种线上和线下的研讨会。此外,计划还提供了各种资源,例如白皮书、产品手册、演示demo等,以及面向企业的文档内容。
值得一提的是,Arm还特别推出了名为“Learning Paths”的项目。该项目旨在设计一系列课程,帮助开发者快速熟悉在Arm系统上的软件应用、安装部署和性能优化工作。这个项目是开源的,任何使用者都可以为其做出贡献,分享自己的实践经验。
另外,Arm还推出了一个名为“Works on Arm”的计划,通过此项目为开发者提供免费的Arm架构开发平台,以促进他们的创新。这为开发者提供了广泛的选择。开发者可以登录Arm官网(arm.com),提交资源申请,并开始构建基于Arm架构的软件系统。在国内市场中,阿里云最近也推出了一个免费试用活动,开发者可以登录阿里云开发者社区官网,选择特定规格的服务器进行测试评估。这是一个免费获得最新的Armv9架构云实例的绝佳机会。
- Arm Neoverse软件迁移

首先,针对所述业务,我将解释如何在Arm架构下进行软件优化。为了更好地理解,我将通过一个简单的示例来说明。随着Arm生态的不断发展,实现在Arm硬件系统上获得良好性能变得相对简单。
举例来说,我们可以考虑一个使用C语言编写的"Hello World"程序。要对其进行基本的优化,首先需要在编译构建过程中传递适当的编译参数。这样可以确保编译器能够充分利用硬件的优势,从而提升性能。需要注意的是,在之前的一些传统架构中,通常使用"-march=native"这种编译参数来让编译器根据当前的系统自动选择优化策略。
然而,在Arm架构中,具体来说就是Arm64架构,我们需要将原来的"-march=native"参数替换为"-mcpu=native"。这样在编译Arm系统时,编译器会根据当前的CPU型号进行优化,从而获得更好的性能。

在这种情况下,各个步骤保持一致。在这时,编译器会自动调用最新的优化策略,以实现理想的性能优化结果。在这里,我想介绍一个架构的基本概念。在Arm的生态系统中,涉及到CPU架构、CPU微架构和芯片实现这三个不同的概念。
首先,CPU架构是对处理器预期行为的定义。微架构则涉及CPU核心的设计和具体实现。最终是以微架构实现为基础的芯片实现。在这一基础上,还包括了各种组件,如系统总线、中断控制器和特殊加速引擎,以实现完整的芯片功能。同一CPU架构可以有不同的微架构实现。例如,倚天710基于Neoverse N2 CPU核心,它采用Armv9架构。另外,Cortex- A710也是基于Armv9架构的CPU核心。
因此,相同的软件可以在这两种不同的CPU架构上运行,因为它们都基于Armv9架构定义。只是这些不同的核心可能具有不同的流水线深度和特定实现。
总之,这涵盖了架构和微架构之间的区别。对于相同的CPU微架构实现,例如Neoverse N2,芯片厂商和合作伙伴可以根据需求进行定制,从而适应不同的匹配总线实现。这包括设计不同核心数、系统拓扑和规格,选择适当的内存控制器,并应用不同的加速引擎,最终实现不同功能的芯片。

随后,当提及先前所介绍的内容时,涉及到的是架构、微架构以及芯片实现之间的区别。对于编译器而言,它能够辨识传入的特定架构参数,例如我们使用march,其中包括其CPU架构的特性, 假设我们指定其为Armv8.2架构,并且增加了fp16和crypto指令等特性。这等效于设置mcpu=neoverse-n1,同时添加crypto指令支持,两者的效果是一致的。
对于编译器而言,设置CPU架构特性、直接指定特定型号的CPU核心或者在本地原生编译都是可行的。假设我们在本地进行原生编译,例如拿到倚天的云实例,建议在设置编译选项时,直接传入mcpu=native。这样就能避免处理架构细节,比如当前CPU是否是Armv8.x架构,是否支持crypto和SVE等特性。
然而,在集成构建环境中,尤其是在不同云实例或平台上,涉及到不同的CPU核心,甚至不同的CPU架构。在这种情况下,考虑编译并在特定环境上运行最终生成的二进制程序时,就需要考虑适配问题。需要确定使用何种架构特性,或者程序将在何种CPU上执行,这方面的决策将会略有复杂。若在本机进行原生编译,例如在云实例上直接编译,并运行程序,那么直接使用mcpu=native是最可靠的做法。
在此页中,我们将介绍在 Armv8.1架构中提取的一个名为"Large System Extension"的技术。该扩展引入了一系列的原子操作指令。通过这些原子操作指令,我们可以在Arm处理器上更有效地处理锁和并发竞争。由于Arm的CPU核心数量通常比其他架构更多,从而可支持更多同时运行的线程。然而,由于核心较多,线程数较多,因此锁和并发竞争可能会更加激烈。
在Armv8.1之前,如果没有"Large System Extension",实现锁操作需要使用繁琐的独占读写操作,导致效率较低。但是自从Armv8.1引入了这一系列的原子操作指令后,通过使用这些指令来实现锁操作,可以显著提高锁和竞争的效率。
要使编译器识别并支持这个特性,在gcc10之前的版本中,需要使用"-moutline-atomics"选项来传递给编译器。通过传递这个选项,编译器将知道使用LSE指令而不是传统的exclusive操作来实现锁定。
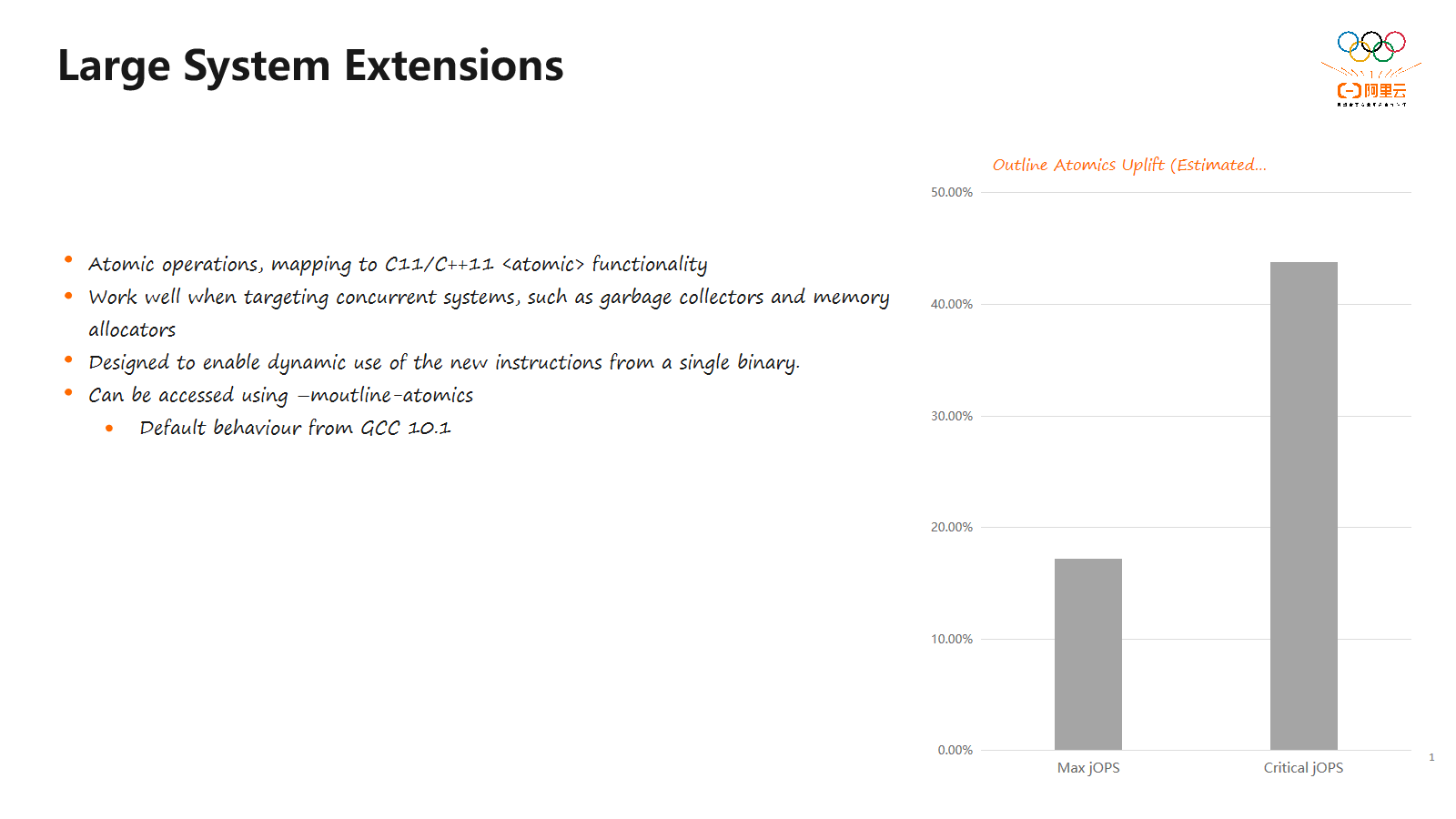
这个"LSE"扩展对于整个应用的性能影响非常显著。例如,在一个SPECjbb测试中,我们可以看到在启用LSE指令与不启用之间的性能对比。测试包括两种场景:一种是最大吞吐量,另一种是在保证时延情况下的吞吐量。结果显示,在最大吞吐量的情况下,启用LSE指令可以获得近20%的性能提升。对于关键的操作(Critical jOPS)而言,启用LSE指令可以获得超过40%的性能提升。
基于这个实例,我们建议开发者在构建软件时,如果使用gcc10之后的版本,可以直接受益于LSE扩展。而对于gcc10之前的版本,需要传递"-moutline-atomics"编译选项以启用LSE扩展。

接下来的内容将列出编译器常见的优化策略和方向。在此图表中,横轴代表性能表现,而纵轴则表示生成的二进制机器代码的尺寸。对于服务器环境,一般不太关注尺寸方面的问题。这主要考虑在嵌入式设备和手持设备等情况下,需要资源占用较小。
然而,在服务器环境中,性能优化更为重要。编译器的默认编译选项是不进行任何优化,这对大多数软件版本来说并不合适。我们建议至少使用 `-O2` 级别的优化。如果需要更高级别的优化,可以尝试使用 `-O3`,这将自动启用相应的SIMD操作优化。

关于编译器,还有一个重要的话题是一项名为"Link Time Optimization"(LTO,链接时优化)的优化技术。传统的编译方式是逐个处理文件进行编译,而启用LTO后,它将在链接阶段综合考虑整个程序中的所有目标文件,并进行全局的优化。这种方法对于整体性能提升非常明显。
因此,我们建议在构建过程中,特别是对于大型软件项目,采用类似SIMD进行编写,并在构建时开启LTO选项以实现链接时的编译优化。
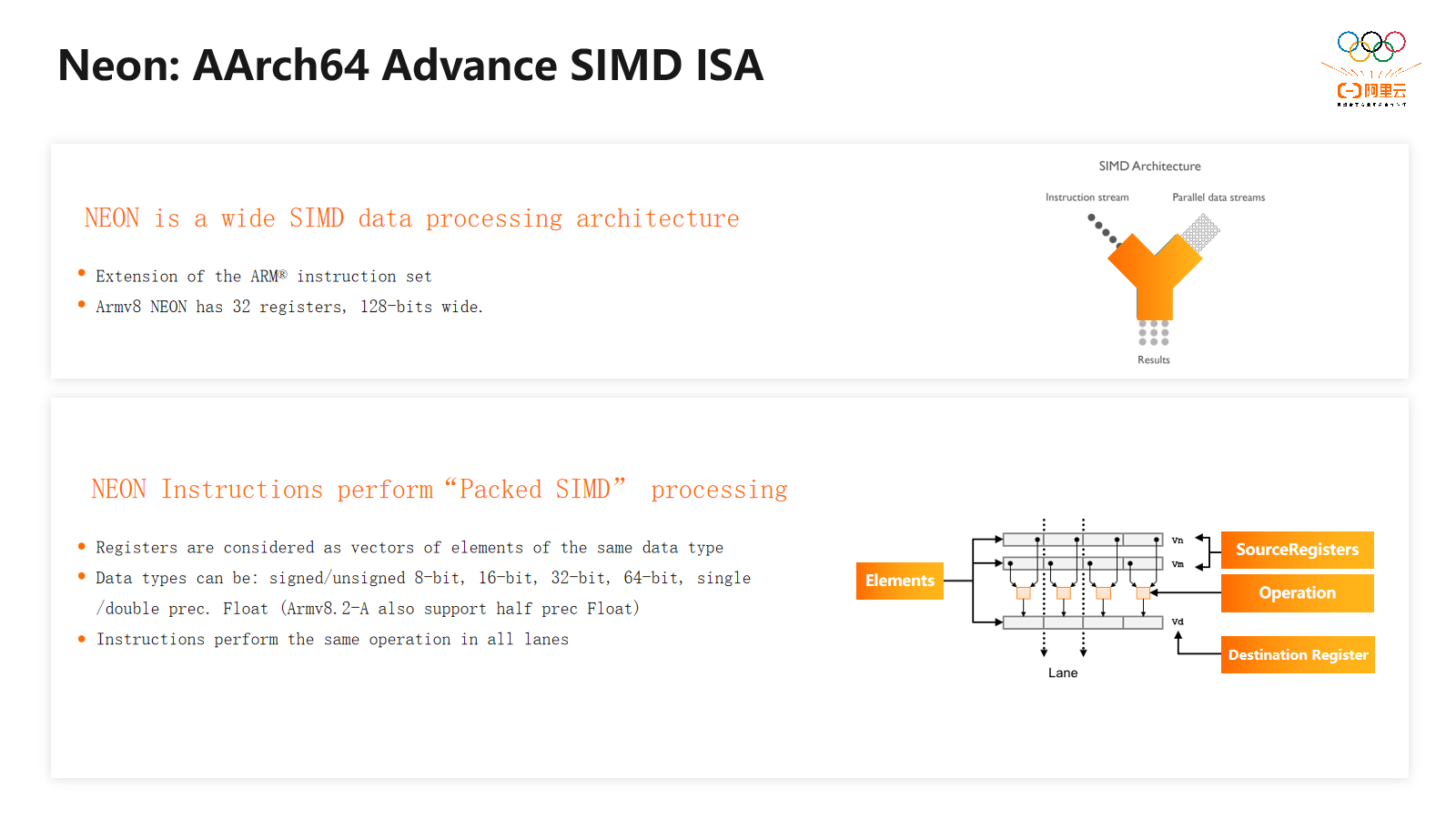
接下来我将对Arm架构下的向量化加速技术进行介绍。这个概念与x86架构下的SSE、AVX等类似。在软件迁移过程中,这是一项重要的性能优化手段。通过使用SIMD技术,可以在单条指令中同时操作多个数据,从而提高操作的并行度和IPC。Arm架构下的SIMD技术主要包括Neon和SVE。这项技术广泛应用于数据量较大的应用场景,如视频编解码、图形图像处理、压缩、解压缩和网络处理等。
首先,我们来看一下Neon指令集扩展。Neon指令可以执行并行数据处理,其寄存器宽度固定为128位。这可以被视为一系列元素的向量,即向量化。每个元素在这里被称为一个通道。计算器可以分为多个通道,但要求每个元素具有相同的数据类型和宽度,可以是8位、16位、32位或64位整数,也可以是浮点数。
当执行指令时,在所有通道中同时执行相同操作。通过这种方式,一条指令可以同时处理多个数据。例如,原先需要四条32位整数加法指令来执行的操作,使用Neon后可以将这四个整数放入一个128位寄存器中,然后用一条指令完成。这种技术有助于提高计算性能和效率,特别是在涉及大量数据的应用中。
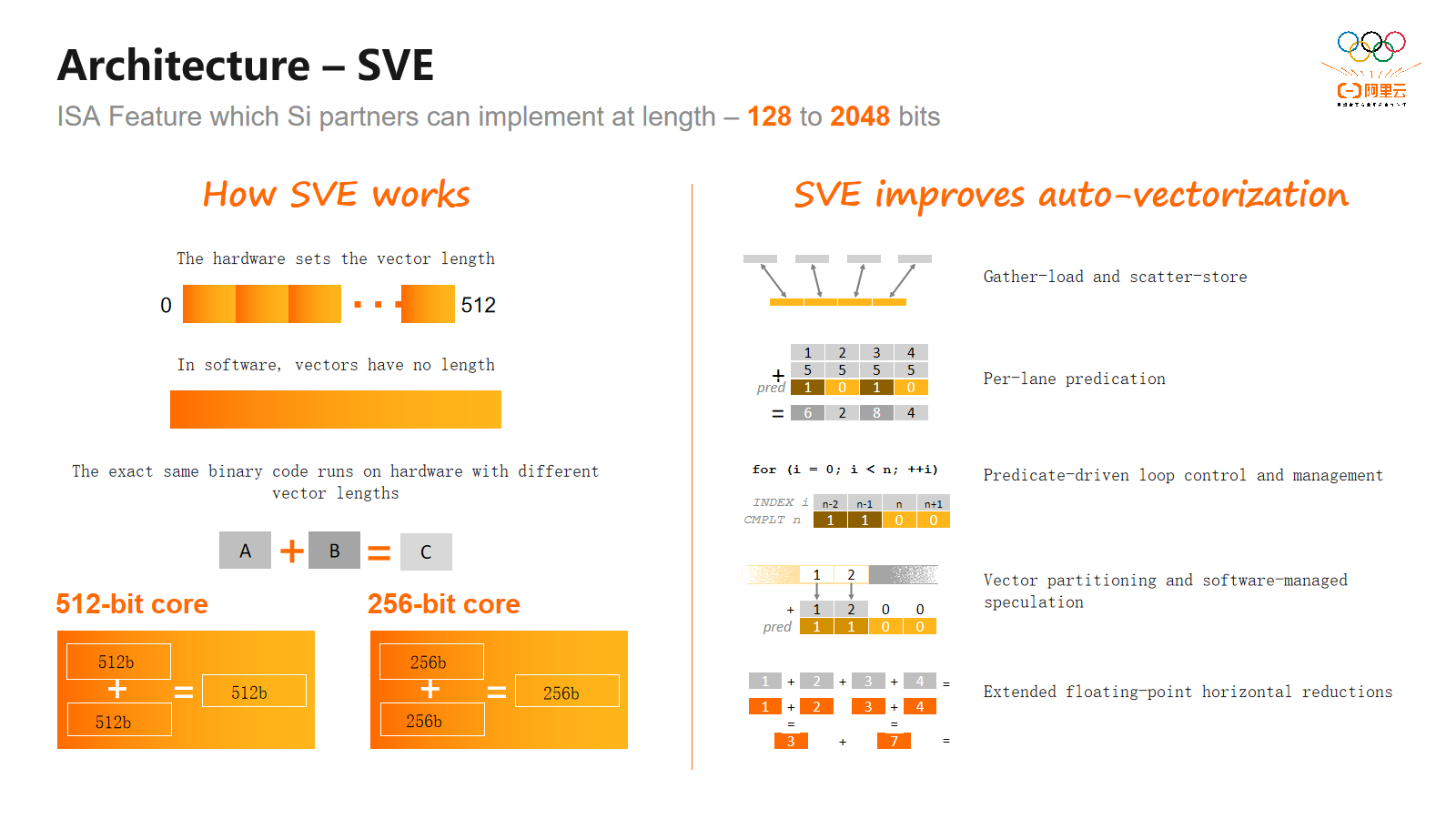
接下来我们将介绍SVE的架构扩展,该扩展在Neon之后引入。SVE是一种面向高性能计算和机器学习等任务的可扩展向量指令架构,引入了全新的指令集。
与Neon不同的是,Neon支持固定宽度的128位,而SVE支持从128位到2048位的向量长度,以128位为步长。此外,SVE的一个重要特点是,经过适当编译后,同一个二进制应用程序可以在不同向量长度的机器上运行,无需重新编译。
SVE的主要特性与Neon不同之处在于,除了向量宽度外,它引入了离散的加载和存储机制。这为开发者和编译器构建向量寄存器提供了便利。其次,SVE引入了面向每个通道的预测机制,通过引入掩码来控制指令执行过程中的参与通道。对循环处理提供了更好支持, 配合通道预测寄存器,提升了对循环的支持。在以往编程中,可能需要处理尾循环情况,即当循环次数不是通道数的整数倍时, 要单独处理剩下的元素。而通过SVE的额外指令和掩码寄存器,无需再处理尾循环,这是一个显著的优势。

在前述内容中,我们详细介绍了Neon和SVE这两种向量处理架构。接下来,我们将讨论如何在Arm架构中应用向量化操作。首先,最常见且重要的方法是依赖编译器,通过传递类似于march的编译选项,并在选项中添加SVE或Neon来启用向量化支持。
编译器将自动根据这些选项调用适用于Neon和SVE的优化策略。此外,我们还可以在本地原生编译时,使用mcpu参数指定特定的CPU微架构,或者直接使用mcpu=native。这将使编译器自动进行向量化优化。
例如,在以前的代码中,只需在编译时添加-mcpu=neoverse-n2选项,编译器将自动应用向量化优化,从而生成性能更优的代码。此外,对于需要针对计算库进行优化的情况,开发人员可以从Arm官网下载相关资源(arm.com)。在Arm开发者网站(developer.arm.com)上,可以获取到针对CPU软件优化的指南。这些指南包含指令的执行时延,以及一些并行执行操作的示例等信息,供开发人员参考。

在这个情境下,编译器自动向量化优化发挥了关键作用。对于开发人员而言,当意识到性能瓶颈存在时,有两种主要方法可以考虑。一种方法是采用手写汇编语言,另一种方法是使用intrinsic技术。当然,还可以利用编译器提供的自动化优化功能。
在此基础上,还可以探索其他增强性能的手段。相较于手写汇编语言,更倾向于采用intrinsic方法,因为手写汇编语言的开发效率较低且繁琐,需要处理诸如寄存器分配等问题,效率较低。相反,采用intrinsic的方法则在性能和开发便捷性之间取得了很好的平衡。
这种方法通过定义适当的函数和数据类型,使得开发人员可以在需要优化时,通过包含适当的头文件(例如arm_neon.h arm_sve.h),直接调用C函数来使用SVE和Neon的操作。另一个优势是,与直接编写汇编代码相比,intrinsic的函数仍然可以受益于编译器的进一步优化。
举个例子,左侧是Intrisics代码,右侧是相应的汇编代码。从这个例子中可以清楚地看出,用这种方法编写的代码与一般程序的写法相似,无需过多考虑底层寄存器的使用和分配,这种方法既直观又高效。
以上就是我本次课程的全部内容。
想要关注更多【倚天实例迁移课程】直播的同学可以点击链接进入活动官网了解更多资讯!


