4、 DBNet
DBNet是基于图像分割网络的文本检测方法,本文提出Differentiable Binarization module(DB module)来简化分割后处理步骤,并且可以设定自适应阈值来提升网络性能。DBNet的网络结构见图5,通过FPN网络结构(backbone)得到1/4的特征图F,通过F得到probability map (P ) 和threshold map (T),通过P、T得到binary map(B)。在训练期间对P、T、B进行监督训练,P和B使用相同的监督信号(即label)。在推理时,只需要P或B就可以得到文本框。
 图5 DBNet结构,其中 "pred "包括一个3×3卷积算子和两个跨度为2的去卷积算子。算子和两个跨度为2的去卷积算子。1/2"、"1/4"、... "1/32 "表示与输入图像相比的比例
图5 DBNet结构,其中 "pred "包括一个3×3卷积算子和两个跨度为2的去卷积算子。算子和两个跨度为2的去卷积算子。1/2"、"1/4"、... "1/32 "表示与输入图像相比的比例
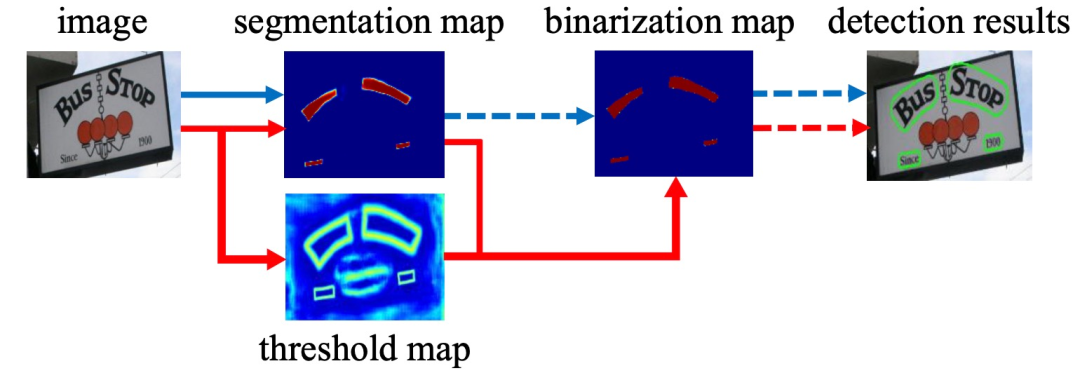 图6 传统pipeline(蓝色流程)和DBNet Pipeline(红色流程)。虚线箭头是仅有的推理运算符;实线箭头表示训练和推理中的可区分运算符
图6 传统pipeline(蓝色流程)和DBNet Pipeline(红色流程)。虚线箭头是仅有的推理运算符;实线箭头表示训练和推理中的可区分运算符
已有的一些基于分割的方法如图14中蓝色箭头所示:首先,它们设置了固定的阈值,用于将分割网络生成的概率图转换为二进制图像;然后,用一些启发式技术(例如像素聚类)将像素分组为文本实例。DBNet的做法如图6中红色箭头所示:在得到分割map后,与网络生成的threshold map进行一次联合后做可微分二值化得到二值化图,然后再经过后处理得到最终结果。将二值化操作插入到分段网络中以进行联合优化,通过这种方式,可以自适应地预测图像每个位置的阈值,从而可以将像素与前景和背景完全区分开。但是,标准二值化函数是不可微分的,因此,作者提出了一种二值化的近似函数,称为可微分二值化(DB),当训练时,该函数完全可微分:

对于预测图(probability map )label 生成任务,给定一个文本图像,其文本区域的每个多边形都由一组片段描述:

然后,通过使用Vatti剪裁算法将多边形G缩小到G_s,生成正面积。缩减的偏移量D是由原多边形的周长L和面积A计算出来的,r是shrink ratio,设置为0.4:

使用 Vatti clipping algorithm 将G缩减到G_s,A是面积,r是shrink ratio,设置为0.4,L是周长。通过类似的方法,可以为阈值图(threshold map)生成标签。首先,文本多边形G以相同的偏移量D对Gd进行扩张。把G_s和G_d之间的空隙视为文本区域的边界,在这里,阈值图的标签可以通过计算与G中最近的片段的距离来生成。二值(binary map)图的label由以上二者计算得来,计算后G_s外为0,G_s内为1。
在预测图(P)、阈值图(T)和估计二值图(B^)上分别定义损失为?_s、?_t、?_b,损失函数如下:

其中,?_s和?_b运用binary cross-entropy (BCE) loss,?_t运用L1 loss。只针对Gd里的像素点计算loss再求和:


最后在测试阶段,再运用下式还原缩小的文本区域:

其中,A'是缩小的多边形的面积,L'是缩小的多边形的周长,r'根据经验设置为1.5。
| 项目 | SOTA!平台项目详情页 |
| DBNet | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/dbnet_1 |
二、文字识别模型
1、 CRNN
CRNN 全称为 Convolutional Recurrent Neural Network,主要用于端到端地对不定长的文本序列进行识别。CRNN不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,就是基于图像的序列识别。CRNN是最经典的文字识别模型。CRNN网络结构包含三部分,如图15所示,从下到上依次为:卷积层,使用CNN,作用是从输入图像中提取特征序列;循环层,使用RNN,作用是预测从卷积层获取的特征序列的标签(真实值)分布;转录层,使用CTC,作用是把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果。

图7CRNN架构
CRNN的输入是100x32归一化高度的词条图像,基于7层CNN(一般使用VGG16)提取特征图,把特征图按列切分(Map-to-Sequence),然后将每一列的512维特征输入到两层各256单元的双向LSTM进行分类。在训练过程中,通过CTC损失函数的指导,实现字符位置与类标的近似软对齐。
CRNN借鉴了语音识别中的LSTM+CTC的建模方法,不同之处是输入LSTM的特征,即,将语音领域的声学特征替换为CNN网络提取的图像特征向量。CRNN既提取了鲁棒特征,又通过序列识别避免了传统算法中难度极高的单字符切分与单字符识别,同时序列化识别也嵌入时序依赖(隐含利用语料)。在训练阶段,CRNN将训练图像统一缩放至100×32;在测试阶段,针对字符拉伸导致识别率降低的问题,CRNN保持输入图像尺寸比例,然后将图像高度统一为32个像素,卷积特征图的尺寸动态决定LSTM时序长度。CRNN具体参数如下表1。

表1 CRNN网络配置摘要。第一行是top层。k"、"s "和 "p "分别代表内核大小、跨度和填充大小
CRNN中一共有四个最大池化层,最后两个池化层的窗口尺寸由 2x2 改为 1x2,也就是图片的高度减半了四次,而宽度则只减半了两次。采用这种处理方式是因为文本图像多数都是高较小而宽较长的,所以其feature map也是这种高小宽长的矩形形状。因此,使用1×2的池化窗口可以尽量保证不丢失在宽度方向的信息,更适合英文字母识别(比如区分i和l)。此外,如表1所示,CRNN 还引入了BatchNormalization模块,加速模型收敛,缩短训练过程。
在CRNN模型中,卷积层的组件是通过从标准CNN模型中提取卷积层和最大集合层来构建的(移除全连接层)。使用该组件从输入图像中提取一个连续的特征表示。在送入网络之前,所有的图像都需要缩放到相同的高度。然后,从卷积层组件产生的特征图中提取一连串的特征向量,这是RNN的输入。一个特征序列的每个特征向量在特征图上从左到右按列生成。这意味着第i个特征向量是所有map的第i列的连接。在作者原文设置中,每一列的宽度被固定为单像素。
RNN 有梯度消失的问题,不能获取更多的上下文信息,所以 CRNN 中使用的是 LSTM,LSTM 的特殊设计允许它捕获长距离依赖。LSTM 是单向的,它只使用过去的信息。然而,在基于图像的序列中,两个方向的上下文是相互有用且互补的。因此,CRNN将两个LSTM(一个前向和一个后向)组合到一个双向LSTM中。此外,可以堆叠多层双向LSTM,深层结构允许比浅层抽象更高层次的抽象。这里采用的是两层各256单元的双向 LSTM 网络:
 图8 (a) 一个基本的LSTM单元结构。一个LSTM由一个单元模块和三个门组成,即输入门、输出门和遗忘门。(b) 论文中使用的深度双向LSTM结构。将一个前向(从左到右)和一个后向(从右到左)的LSTM结合起来就形成了双向LSTM。将多个双向LSTM堆叠在一起,就形成了深度双向LSTM
图8 (a) 一个基本的LSTM单元结构。一个LSTM由一个单元模块和三个门组成,即输入门、输出门和遗忘门。(b) 论文中使用的深度双向LSTM结构。将一个前向(从左到右)和一个后向(从右到左)的LSTM结合起来就形成了双向LSTM。将多个双向LSTM堆叠在一起,就形成了深度双向LSTM
一个特征向量就相当于原图中的一个小矩形区域,RNN 的目标就是预测这个矩形区域为哪个字符,即根据输入的特征向量,进行预测,得到所有字符的softmax概率分布。将这个长度为字符类别数的特征向量作为CTC层的输入。因为每个时间步长都会生成一个输入特征向量 x^T,输出一个所有字符的概率分布y^T,所以输出为 40 个长度为字符类别数的向量构成的后验概率矩阵。然后将这个后验概率矩阵传入转录层。
CRNN中需要解决的关键问题是图像文本长度不定长,所以RNN需要一个额外的搭档来解决对齐解码的问题,这个搭档就是著名的CTC解码。CRNN采取的架构是CNN+RNN+CTC,CNN提取图像像素特征,RNN提取图像时序特征,而CTC归纳字符间的连接特性。转录层输入是一个序列y =y1, . . . , yT,其中T是序列的长度。这里,每个yt是集合L’ =L ∪上的概率分布,其中L包含任务中的所有标签(例如所有的英文字符),以及一个 "blank "标签。在序列π∈L’^T上定义了一个序列到序列的映射函数B,其中T是长度。B将π映射到l上,首先去除重复的标签,然后去除 "blank"。例如,B将"—hh-e-l-ll-oo-"('-'代表'blank')映射到 "hello"。然后,条件概率定义为由B映射到l上的所有π的概率之和:

无词典转录(Lexicon-free transcription)
在这种模式下,上式中定义的具有最高概率的序列l?被作为预测值。并不存在精确找到解决方案的可操作的算法,作者采用的方式是通过l?≈B(argmax_π p(π|y))近似地找到序列l?,即在每个时间戳t取最有可能的标签π_t,并将结果序列映射到l?。
基于词典的转录(Lexicon-based transcription)
在基于词典的模式下,每个测试样本都与一个词典D相关联。基本上,标签序列是通过选择词典中具有最高条件概率的序列来识别的,该概率由上式定义,即l?=argmax l∈D p(l|y)。可以将我们的搜索限制在最近的邻域候选人N_δ(l'),其中,δ是最大的编辑距离,l'是在无词典模式下从y转录的序列:

可以通过BK-树数据结构寻找候选者Nδ(l'),BK-树是一种专门适用于离散公制空间的公制树(metric tree)。BK-树的搜索时间复杂度为O(log |D|),其中|D|为词典大小。因此,这个方案很容易扩展到非常大的词典。在本文方法中,为一个词典离线构建一个BK-树。然后,通过寻找与查询序列的编辑距离小于或等于δ的序列,用BK-树进行快速的在线搜索。
通过对概率的计算,就可以对之前的神经网络进行反向传播更新。类似普通的分类,CTC的损失函数O定义为负的最大似然,为了计算方便,对似然取对数:

通过对损失函数的计算,就可以对之前的神经网络进行反向传播,神经网络的参数根据所使用的优化器进行更新,从而找到最可能的像素区域对应的字符。这种通过映射变换和所有可能路径概率之和的方式使得 CTC 不需要对原始的输入字符序列进行准确的切分。
对于测试阶段,使用训练好的神经网络来识别新的文本图像。文本事先未知,如果像训练阶段一样将每种可能文本的所有路径都计算出来,在时间步长较长和字符序列较长的情况下,这个计算量是非常庞大的。RNN 在每一个时间步长的输出为所有字符类别的概率分布,即一个包含每个字符分数的向量,取其中最大概率的字符作为该时间步长的输出字符,然后将所有时间步长得到的字符进行拼接以生成序列路径,即最大概率路径,再根据上面介绍的合并序列方法得到最终的预测文本结果。在输出阶段经过 CTC 的翻译,即将网络学习到的序列特征信息转化为最终的识别文本,就可以对整个文本图像进行识别。
| 项目 | SOTA!平台项目详情页 |
| CRNN | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/crnn-4 |
2、 RARE
RARE模型实现对不规则文本的端到端文字识别,RARE由STN(Spatial Transformer Network)和SRN(Sequence Recognition Network)组成,两个网络同时用BP算法进行训练。STN用于对输入的不规则文本进行矫正,得到形状规则的文本作为SRN的输入,SRN是一个基于注意力机制的网络结构,实现sequence to sequence的文本识别。
在测试中,先将一张图像通过Thin-Plate-Spline (TPS)变换成一个正规的、更易读的图像,此变换可以矫正不同类型的不规则文本,包括透射变换和弯曲的文本。TPS变换由一组基准点(fiducial points)表示,坐标通过卷积神经网络回归得到。然后再放入SRN中进行识别。SRN使用序列识别的基于注意力的方法,包含一个编码器和一个解码器。编码器生成一个特征表示序列,即序列的特征向量;解码器根据输入序列循环地生成一个字符序列。这个系统是一个端到端的文本识别系统,在训练过程中也不需要额外标记字符串的关键点、字符位置等。
STN主要包括三个部分:1) Localization network; 2) Grid Generator; 3) Sampler,具体结构如图17所示。其中,Localization network在没有任何标注数据的前提下,基于图像内容定位到基准点的位置。文中该网络结构与传统的CNN网络结构相似:4个卷积层,每个卷积层后接一个2 x 2的max-pooling层,再接2个1024维的全连接层,最后输出为40维的向量。此处的输出为基准点的坐标,设定基准点个数为 k=20。2) Grid Generator和Sampler中,Grid generator估计出TPS变换参数,生成一个采样网格。给定pi′的坐标,计算出pi的坐标。文章固定了基准点在目标图像中的位置,再来计算目标图像中每个坐标的像素值。得到原图中pi的坐标后,在Sampler中,pi坐标附近的像素值已知,通过双线性差值得到pi′坐标的像素值。以此类推,得到最终的目标图像I′。
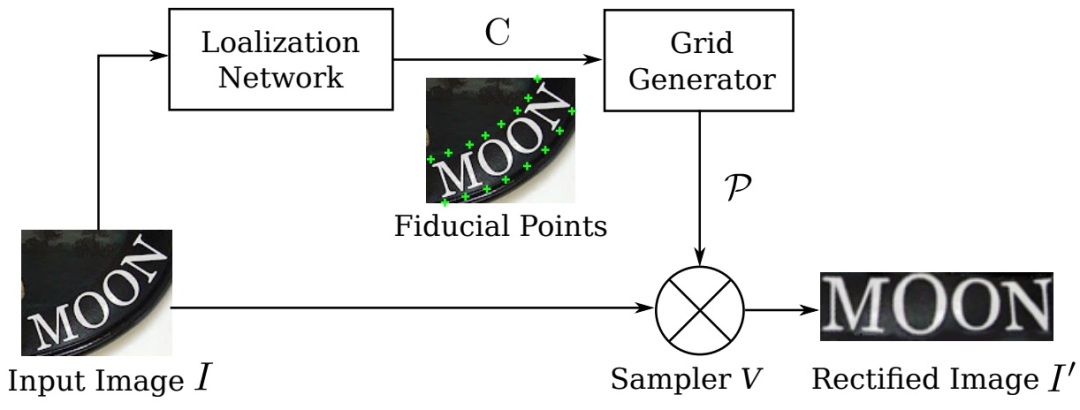 图9 STN结构
图9 STN结构
SRN是一个基于注意力的模型,包括encoder和decoder。Encoder由卷积层和BLSTM组成,Decoder由基于注意力机制的GRU(Gated Recurrent Unit)组成,如图18所示。Encoder包含7个卷积层,第1、2、4、6个卷积层后均接一个2x2的max-pooling层,卷积层上是一个双层的BLSTM网络,每一个LSTM有256个隐单元。encoder的输出序列为h=(h1,h2,…,hL),其中,L等于卷积层的宽度。decoder根据encoder输出的序列循环地生成目标字符序列。decoder是基于注意力机制的循环网络,此处网络结构采用的GRU是LSTM的一种变体,根据输出不断更新权重α。最后通过softmax函数来计算概率分布,l_t^为概率最高的字符:

SRN直接将一个输入序列映射到另一个序列。输入和输出的序列都可以有任意的长度。它可以只用单词图像和相关文本进行训练。

图10 SRN结构,它由一个编码器和一个解码器组成。编码器使用几个卷积层(ConvNet)和一个两层的BLSTM网络来提取输入图像的顺序表示(h)。解码器生成一个以h为条件的字符序列(包括EOS令牌)
为了训练模型,我们使训练集上的负对数可能性最小化:

RARE采用ADADELTA作为优化算法,收敛速度较快。模型参数是随机初始化的,除了Localization network,其输出全连接层是通过设置权重为零来初始化的。
当测试图像与词典相关联时,即一组供挑选的词,识别过程是挑选具有最高后验条件概率的词:

为了缩小词典集,构造前缀树,如下图:

图11一个由三个词组成的前缀树。"ten"、"tea "和 "to"。识别工作从树根开始。每一步计算所有子节点的后验概率。具有最高概率的子节点被选为下一个节点。这个过程反复进行,直到到达一个叶子节点。边缘上的数字是后验概率。蓝色节点是被选中的节点。在这种情况下,预测的词是 "tea"
| 项目 | SOTA!平台项目详情页 |
| RARE | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/rare |
前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及API等资源。
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。
