七、模型训练最佳实践
开源代码链接:https://github.com/modelscope/modelscope/blob/master/examples/pytorch/llm/llm_sft.py
准备环境
# Avoid cuda initialization caused by library import (e.g. peft, accelerate) from _parser import * # argv = parse_device(['--device', '1']) argv = parse_device()
命令行参数导入:
from utils import * @dataclass class SftArguments: seed: int = 42 model_type: str = field( default='openbuddy-llama2-13b', metadata={'choices': list(MODEL_MAPPER.keys())}) # baichuan-7b: 'lora': 16G; 'full': 80G sft_type: str = field( default='lora', metadata={'choices': ['lora', 'full']}) ignore_args_error: bool = True # False: notebook compatibility dataset: str = field( default='alpaca-en,alpaca-zh', metadata={'help': f'dataset choices: {list(DATASET_MAPPER.keys())}'}) dataset_seed: int = 42 dataset_sample: Optional[int] = None dataset_test_size: float = 0.01 prompt: str = DEFAULT_PROMPT max_length: Optional[int] = 2048 lora_target_modules: Optional[List[str]] = None lora_rank: int = 8 lora_alpha: int = 32 lora_dropout_p: float = 0.1 gradient_checkpoint: bool = True batch_size: int = 1 max_epochs: int = 1 learning_rate: Optional[float] = None weight_decay: float = 0.01 n_accumulate_grad: int = 16 grad_clip_norm: float = 1. warmup_iters: int = 200 save_trainer_state: Optional[bool] = None eval_interval: int = 500 last_save_interval: Optional[int] = None last_max_checkpoint_num: int = 1 best_max_checkpoint_num: int = 1 logging_interval: int = 5 tb_interval: int = 5 def __post_init__(self): if self.sft_type == 'lora': if self.learning_rate is None: self.learning_rate = 1e-4 if self.save_trainer_state is None: self.save_trainer_state = True if self.last_save_interval is None: self.last_save_interval = self.eval_interval elif self.sft_type == 'full': if self.learning_rate is None: self.learning_rate = 1e-5 if self.save_trainer_state is None: self.save_trainer_state = False # save disk space if self.last_save_interval is None: # Saving the model takes a long time self.last_save_interval = self.eval_interval * 4 else: raise ValueError(f'sft_type: {self.sft_type}') if self.lora_target_modules is None: self.lora_target_modules = MODEL_MAPPER[self.model_type]['lora_TM'] args, remaining_argv = parse_args(SftArguments, argv) if len(remaining_argv) > 0: if args.ignore_args_error: logger.warning(f'remaining_argv: {remaining_argv}') else: raise ValueError(f'remaining_argv: {remaining_argv}')
导入模型:
seed_everything(args.seed) # ### Loading Model and Tokenizer support_bf16 = torch.cuda.is_bf16_supported() if not support_bf16: logger.warning(f'support_bf16: {support_bf16}') model, tokenizer, model_dir = get_model_tokenizer( args.model_type, torch_dtype=torch.bfloat16) if args.gradient_checkpoint: # baichuan-13b does not implement the `get_input_embeddings` function if args.model_type == 'baichuan-13b': model.get_input_embeddings = MethodType( lambda self: self.model.embed_tokens, model) model.gradient_checkpointing_enable() model.enable_input_require_grads()
准备LoRA:
# ### Preparing lora if args.sft_type == 'lora': lora_config = LoRAConfig( replace_modules=args.lora_target_modules, rank=args.lora_rank, lora_alpha=args.lora_alpha, lora_dropout=args.lora_dropout_p) logger.info(f'lora_config: {lora_config}') model = Swift.prepare_model(model, lora_config) show_freeze_layers(model) print_model_info(model) # check the device and dtype of the model _p: Tensor = list(model.parameters())[-1] logger.info(f'device: {_p.device}, dtype: {_p.dtype}')
导入datasets:
# ### Loading Dataset dataset = get_dataset(args.dataset) train_dataset, val_dataset = process_dataset(dataset, args.dataset_test_size, args.dataset_sample, args.dataset_seed) tokenize_func = partial( tokenize_function, tokenizer=tokenizer, prompt=args.prompt, max_length=args.max_length) train_dataset = train_dataset.map(tokenize_func) val_dataset = val_dataset.map(tokenize_func) del dataset # Data analysis stat_dataset(train_dataset) stat_dataset(val_dataset) data_collator = partial(data_collate_fn, tokenizer=tokenizer) print_example(train_dataset[0], tokenizer)
配置Config:
# ### Setting Config cfg_file = os.path.join(model_dir, 'configuration.json') T_max = get_T_max( len(train_dataset), args.batch_size, args.max_epochs, True) work_dir = get_work_dir(f'runs/{args.model_type}') config = Config({ 'train': { 'dataloader': { 'batch_size_per_gpu': args.batch_size, 'workers_per_gpu': 1, 'shuffle': True, 'drop_last': True, 'pin_memory': True }, 'max_epochs': args.max_epochs, 'work_dir': work_dir, 'optimizer': { 'type': 'AdamW', 'lr': args.learning_rate, 'weight_decay': args.weight_decay, 'options': { 'cumulative_iters': args.n_accumulate_grad, 'grad_clip': { 'norm_type': 2, 'max_norm': args.grad_clip_norm } } }, 'lr_scheduler': { 'type': 'CosineAnnealingLR', 'T_max': T_max, 'eta_min': args.learning_rate * 0.1, 'options': { 'by_epoch': False, 'warmup': { 'type': 'LinearWarmup', 'warmup_ratio': 0.1, 'warmup_iters': args.warmup_iters } } }, 'hooks': [ { 'type': 'CheckpointHook', 'by_epoch': False, 'interval': args.last_save_interval, 'max_checkpoint_num': args.last_max_checkpoint_num, 'save_trainer_state': args.save_trainer_state }, { 'type': 'EvaluationHook', 'by_epoch': False, 'interval': args.eval_interval }, { 'type': 'BestCkptSaverHook', 'metric_key': 'loss', 'save_best': True, 'rule': 'min', 'max_checkpoint_num': args.best_max_checkpoint_num, 'save_trainer_state': args.save_trainer_state }, { 'type': 'TextLoggerHook', 'by_epoch': True, # Whether EpochBasedTrainer is used 'interval': args.logging_interval }, { 'type': 'TensorboardHook', 'by_epoch': False, 'interval': args.tb_interval } ] }, 'evaluation': { 'dataloader': { 'batch_size_per_gpu': args.batch_size, 'workers_per_gpu': 1, 'shuffle': False, 'drop_last': False, 'pin_memory': True }, 'metrics': [{ 'type': 'my_metric', 'vocab_size': tokenizer.vocab_size }] } })
开启微调:
# ### Finetuning def cfg_modify_fn(cfg: Config) -> Config: cfg.update(config) return cfg trainer = EpochBasedTrainer( model=model, cfg_file=cfg_file, data_collator=data_collator, train_dataset=train_dataset, eval_dataset=val_dataset, remove_unused_data=True, seed=42, cfg_modify_fn=cfg_modify_fn, ) trainer.train()
可视化:
Tensorboard 命令: (e.g.)
tensorboard --logdir runs/openbuddy-llama2-13b/v0-20230726-172019 --port 6006
# ### Visualization tb_dir = os.path.join(work_dir, 'tensorboard_output') plot_images(tb_dir, ['loss'], 0.9)
训练和验证损失
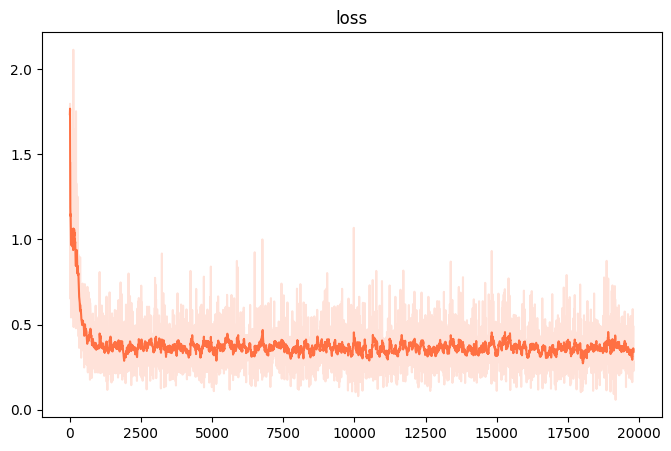
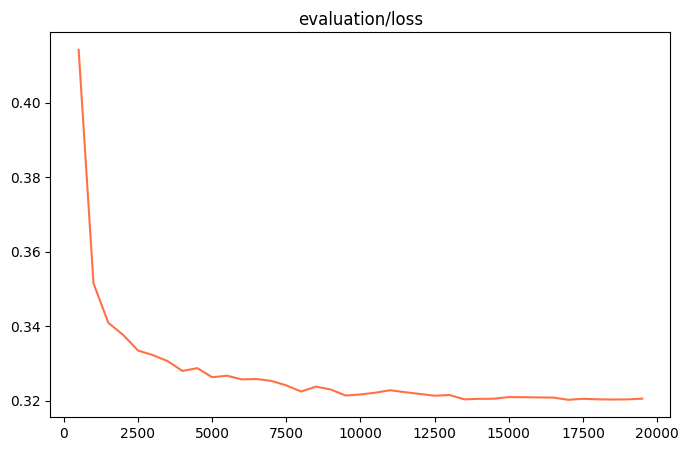
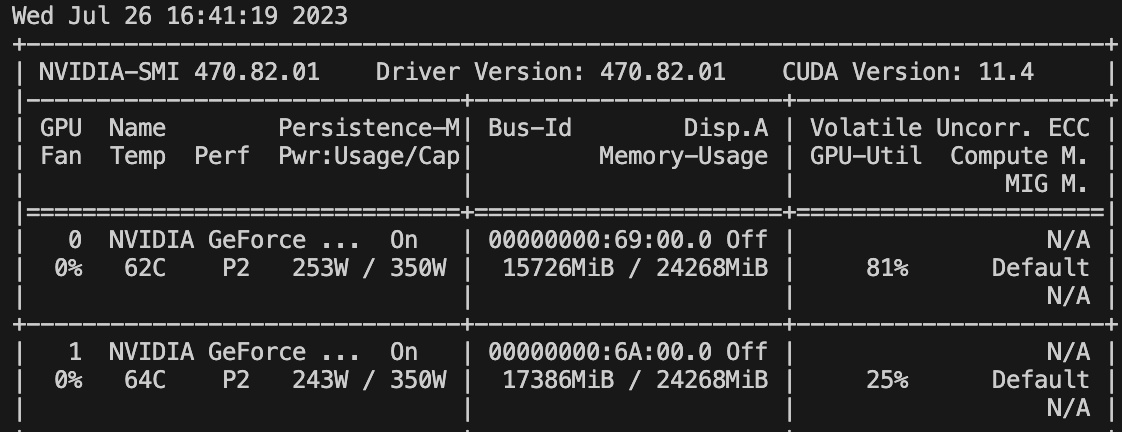
资源消耗
openbuddy-llama2-13b用lora的方式训练的现存占用如下,大约34 G
八、推理训练后的模型
开源代码链接:https://github.com/modelscope/modelscope/blob/master/examples/pytorch/llm/llm_infer.py
# ### Setting up experimental environment. # Avoid cuda initialization caused by library import (e.g. peft, accelerate) from _parser import * # argv = parse_device(['--device', '1']) argv = parse_device() from utils import * @dataclass class InferArguments: model_type: str = field( default='openbuddy-llama2-13b', metadata={'choices': list(MODEL_MAPPER.keys())}) sft_type: str = field( default='lora', metadata={'choices': ['lora', 'full']}) ckpt_path: str = '/path/to/your/iter_xxx.pth' eval_human: bool = False # False: eval test_dataset ignore_args_error: bool = True # False: notebook compatibility dataset: str = field( default='alpaca-en,alpaca-zh', metadata={'help': f'dataset choices: {list(DATASET_MAPPER.keys())}'}) dataset_seed: int = 42 dataset_sample: Optional[int] = None dataset_test_size: float = 0.01 prompt: str = DEFAULT_PROMPT max_length: Optional[int] = 2048 lora_target_modules: Optional[List[str]] = None lora_rank: int = 8 lora_alpha: int = 32 lora_dropout_p: float = 0.1 max_new_tokens: int = 512 temperature: float = 0.9 top_k: int = 50 top_p: float = 0.9 def __post_init__(self): if self.lora_target_modules is None: self.lora_target_modules = MODEL_MAPPER[self.model_type]['lora_TM'] if not os.path.isfile(self.ckpt_path): raise ValueError( f'Please enter a valid ckpt_path: {self.ckpt_path}') args, remaining_argv = parse_args(InferArguments, argv) if len(remaining_argv) > 0: if args.ignore_args_error: logger.warning(f'remaining_argv: {remaining_argv}') else: raise ValueError(f'remaining_argv: {remaining_argv}') # ### Loading Model and Tokenizer support_bf16 = torch.cuda.is_bf16_supported() if not support_bf16: logger.warning(f'support_bf16: {support_bf16}') model, tokenizer, _ = get_model_tokenizer( args.model_type, torch_dtype=torch.bfloat16) # ### Preparing lora if args.sft_type == 'lora': lora_config = LoRAConfig( replace_modules=args.lora_target_modules, rank=args.lora_rank, lora_alpha=args.lora_alpha, lora_dropout=args.lora_dropout_p, pretrained_weights=args.ckpt_path) logger.info(f'lora_config: {lora_config}') model = Swift.prepare_model(model, lora_config) elif args.sft_type == 'full': state_dict = torch.load(args.ckpt_path, map_location='cpu') model.load_state_dict(state_dict) else: raise ValueError(f'args.sft_type: {args.sft_type}') # ### Inference tokenize_func = partial( tokenize_function, tokenizer=tokenizer, prompt=args.prompt, max_length=args.max_length) streamer = TextStreamer( tokenizer, skip_prompt=True, skip_special_tokens=True) generation_config = GenerationConfig( max_new_tokens=args.max_new_tokens, temperature=args.temperature, top_k=args.top_k, top_p=args.top_p, do_sample=True, pad_token_id=tokenizer.eos_token_id) logger.info(f'generation_config: {generation_config}') if args.eval_human: while True: instruction = input('<<< ') data = {'instruction': instruction} input_ids = tokenize_func(data)['input_ids'] inference(input_ids, model, tokenizer, streamer, generation_config) print('-' * 80) else: dataset = get_dataset(args.dataset) _, test_dataset = process_dataset(dataset, args.dataset_test_size, args.dataset_sample, args.dataset_seed) mini_test_dataset = test_dataset.select(range(10)) del dataset for data in mini_test_dataset: output = data['output'] data['output'] = None input_ids = tokenize_func(data)['input_ids'] inference(input_ids, model, tokenizer, streamer, generation_config) print() print(f'[LABELS]{output}') print('-' * 80) # input('next[ENTER]')
