2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
作者|于喜千(千浪)
实验简介
MySQL Connector 可以将本地或远程的 MySQL 数据库连接到 Flink 中,并方便地使用 Flink Table API 与之交互、捕获数据变更、并将处理结果写回数据库。
本场景主要介绍如何在阿里云实时计算平台上使用 Flink MySQL 连接器的相关功能,并使用 Table API 编写一个简单的例子,尝试 MySQL 作为源表、维表、汇表的不同功能。
实验资源
实验所开通的云产品因数据连通性要求,需使用同一 Region 可用区,建议都选取北京 Region 的同一可用区。涉及的云产品包括阿里云实时计算 Flink 版、阿里云数据库 RDS。
本场景使用到的实验资源和配置如下:
- 资源一:阿里云实时计算 Flink 版
| 配置项 | 规格 |
|---|---|
| Task Manger 个数 | 4 个 |
| Task Manager CPU | 2 核心 |
| Task Manager Memory | 8 GiB |
| Job Manager CPU | 1 核 |
| Job Manager Memory | 2 GiB |
- 资源二:阿里云数据库 RDS
| 配置项 | 规格 |
|---|---|
| CPU | 2 核心 |
| 内存 | 4 GiB |
| 最大连接数 | 1200 |
| 最大 IOPS | 2000 |
体验目标
本场景将以 阿里云实时计算Flink版为基础,使用 Flink 自带的 MySQL Connector 连接 RDS 云数据库实例,并以一个实时商品销售数据统计的例子尝试上手 Connector 的数据捕获、数据写入等功能。
按步骤完成本次实验后,您将掌握的知识有:
- 使用 Flink 实时计算平台创建并提交作业的方法;
- 编写基于 Flink Table API SQL 语句的能力;
- 使用 MySQL Connector 对数据库进行读写的方法。
背景知识
本场景主要涉及以下云产品和服务:
阿里云实时计算 Flink 版是一种全托管 Serverless 的 Flink 云服务,开箱即用,计费灵活。具备一站式开发运维管理平台,支持作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。100% 兼容 Apache Flink,支持开源 Flink 平滑迁移上云,核心企业级增强 Flink 引擎较开源 Flink 有约两倍性能的提升。拥有 Flink CDC、企业级复杂事件处理(CEP)等企业级增值功能,并内置丰富上下游连接器,助力企业构建高效、稳定和强大的实时数据应用。
云数据库 RDS(Relational Database Service,简称 RDS)是一种稳定可靠、可弹性伸缩的在线数据库服务。基于阿里云分布式文件系统和 SSD 盘高性能存储,RDS 支持 MySQL、SQL Server、PostgreSQL、PPAS 和 MariaDB 引擎,提供了容灾、备份、恢复、监控、迁移等方面的全套解决方案,彻底解决数据库运维的烦恼。
前置知识
- 了解 MySQL 数据库相关的基础知识,能够阅读编写简单的 SQL 语句。
步骤一:创建资源
开始实验之前,您需要先创建相关实验资源:阿里云实时计算 Flink 版和云数据库 RDS。
步骤二:创建数据库表
在这个例子中,我们将创建三张数据表,分别作为源表、维表、汇表,演示 MySQL Connector 的不同功能。
- 进入云数据库 RDS 后台,并登录刚刚创建资源的后台页面。
- 点击左侧边栏的 + 加号按钮,创建一个测试用数据库,然后在右侧命令区输入以下建表指令并执行:
-- Source Table;
CREATE TABLE `source_table` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`good_id` int DEFAULT NULL,
`amount` int DEFAULT NULL,
`record_time` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`)
);
-- Dimension Table;
CREATE TABLE `dimension_table` (
`good_id` int unsigned NOT NULL,
`good_name` varchar(256) DEFAULT NULL,
`good_price` int DEFAULT NULL,
PRIMARY KEY (`good_id`)
);
-- Sink Table;
CREATE TABLE `sink_table` (
`record_timestamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`good_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`sell_amount` int DEFAULT NULL,
PRIMARY KEY (`record_timestamp`)
);
步骤三:创建 Flink 作业
1.进入实时计算 Flink 平台,点击左侧边栏中的「应用」—「作业开发」菜单,并点击顶部工具栏的「新建」按钮新建一个作业。作业名字任意,类型选择「流作业 / SQL」,其余设置保持默认。如下所示:

2.成功创建作业后,右侧编辑窗格应该显示新作业的内容:

3.接下来,我们在右侧编辑窗格中输入以下语句来创建一张临时表,并使用 MySQL CDC 连接器实时捕获 source_table的变化:
CREATE TEMPORARY TABLE source_table (
id INT NOT NULL PRIMARY KEY NOT ENFORCED,
record_time TIMESTAMP_LTZ(3),
good_id INT,
amount INT,
WATERMARK FOR record_time AS record_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '******************.mysql.rds.aliyuncs.com',
'port' = '3306',
'username' = '***********',
'password' = '***********',
'database-name' = '***********',
'table-name' = 'source_table'
);
需要将
hostname参数替换为早些时候创建资源的域名、将username和password参数替换为数据库登录用户名及密码、将database-name参数替换为之前在 RDS 后台中创建的数据库名称。
其中,'connector' = 'mysql-cdc'指定了使用 MySQL CDC 连接器来捕获变化数据。您需要使用准备步骤中申请的 RDS MySQL URL、用户名、密码,以及之前创建的数据库名替换对应部分。
任何时候您都可以点击顶部工具栏中的「验证」按钮,来确认作业 Flink SQL 语句中是否存在语法错误。
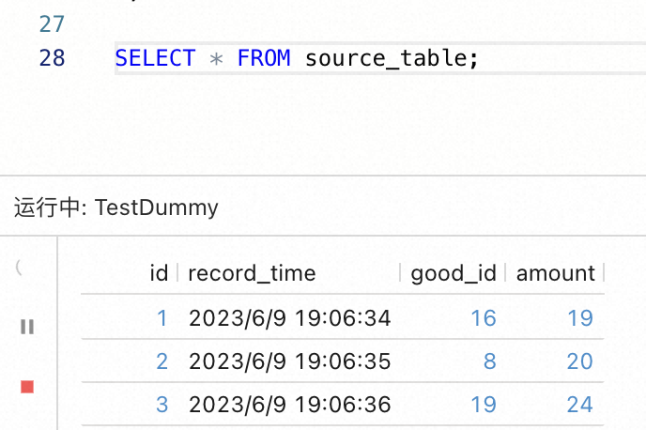
4.为了测试是否成功地捕获了源表数据,紧接着在下面写一行 SELECT * FROM source_table;语句,并点击工具栏中的「执行」按钮。接着,向 source_table表中插入一些数据。如果控制台中打印了相应的数据行,则说明捕获成功,如下图所示:
5.接下来,我们希望对原始数据按照时间窗口进行分组计算。我们使用 TUMBLE相关窗口函数结合 GROUP BY,将长度 15 秒内的订单数据按照商品 ID 进行归类,并使用 SUM计算其销售总额。我们在 Flink 作业编辑窗格中输入如下代码:
SELECT
good_id,
tumble_start(
record_time, interval '15' seconds
) AS record_timestamp,
sum(amount) AS total_amount
FROM
source_table
GROUP BY
tumble (
record_time, interval '15' seconds
),
good_id;
为了测试这一效果,需要向数据库中插入多条数据。你可以在 RDS 中执行附件中的「
示例数据.sql」来插入数据,或者使用「示例数据生成.py」脚本实时地插入数据。
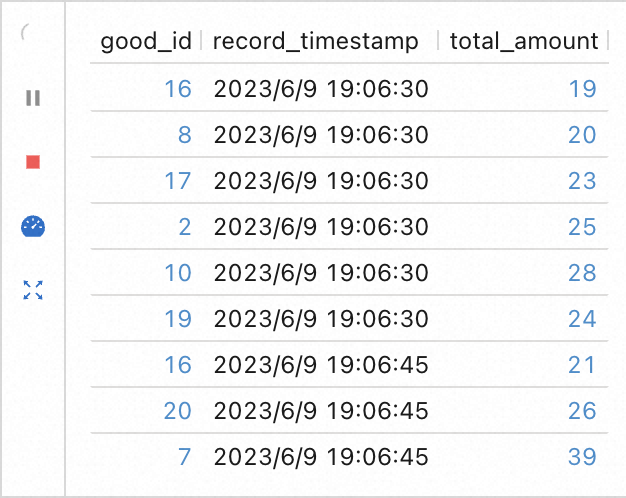
在保证源表中有数据的情况下,再次执行 Flink 作业,观察控制台的输出结果:
6.在这个业务场景中,购买商品信息使用 good_id记录,而商品 ID 到可读商品名字的映射表、每件商品的价格等信息则存储在另一张维度表(Dimension Table)中。我们同样可以使用 Flink SQL 连接维度表,只需在 Flink 作业中编写下面的语句:
CREATE TEMPORARY TABLE dimension_table (
good_id INT NOT NULL PRIMARY KEY NOT ENFORCED,
good_name VARCHAR(256),
good_price INT
) WITH (
'connector' = 'mysql',
'hostname' = '******************.mysql.rds.aliyuncs.com',
'port' = '3306',
'username' = '***********',
'password' = '***********',
'database-name' = '***********',
'table-name' = 'dimension_table'
);
这里,我们希望根据上一步中统计出的「每 15 秒商品销售量」信息,计算出每件商品的销售额。由于商品名称及商品价格数据存储在另一张维度表 dimension_table中,我们需要将结果视图和 dimension_table进行 JOIN 操作,并将「商品销售量」、「商品价格」相乘计算出「商品销售额」,并提取结果中的商品可读名称信息作为结果表。
需要确保
dimension_table中存在对应商品 ID 的条目。你可以在 RDS 中执行附件中的「示例数据.sql」来插入数据。
作业代码如下:
SELECT
record_timestamp,
good_name,
total_amount * good_price AS revenue
FROM
(
SELECT
good_id,
tumble_start(
record_time, interval '15' seconds
) AS record_timestamp,
sum(amount) AS total_amount
FROM
source_table
GROUP BY
tumble (
record_time, interval '15' seconds
),
good_id
) AS tumbled_table
LEFT JOIN dimension_table ON tumbled_table.good_id = dimension_table.good_id;
其中第 7 到 20 行和上一步骤的 SQL 语句一致。
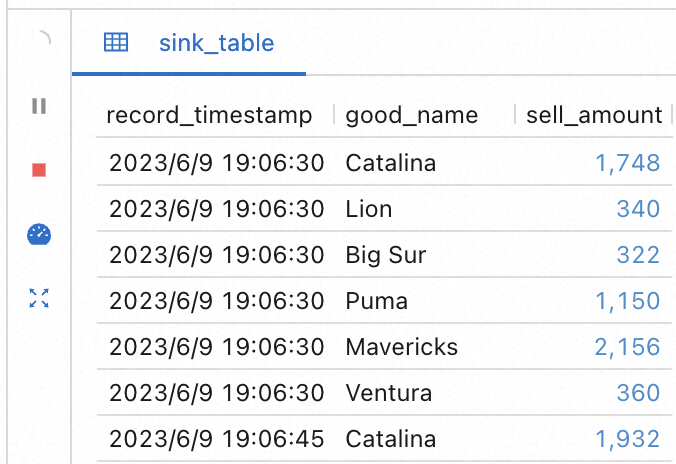
执行上面的语句,并观察控制台中的统计数据:
7.最后,我们将这些实时的统计数据写回数据库,Flink SQL 也可以简单地实现这一点。首先我们需要创建一张用于连接汇表的 Flink 临时表,如下所示:
CREATE TEMPORARY TABLE sink_table (
record_timestamp TIMESTAMP(3) NOT NULL PRIMARY KEY NOT ENFORCED,
good_name VARCHAR(128),
sell_amount INT
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://******************.mysql.rds.aliyuncs.com:3306/***********',
'table-name' = 'sink_table',
'username' = '***********',
'password' = '***********',
'scan.auto-commit' = 'true'
);
然后,只需要将上面的 SELECT 语句的输出结果 INSERT 到该表就可以了:
INSERT INTO sink_table
SELECT
record_timestamp,
-- ... 和上面的语句一样
现在,点击控制台上的「上线」按钮,即可将我们编写的 Flink SQL 作业部署上线执行。您可以使用数据库客户端等软件观察汇表中是否写入了正确的数据。
阿里云实时计算控制台在使用「执行」功能调试时,不会写入任何数据到下游中。因此为了测试使用 SQL Connector 写入汇表,您必须使用「上线」功能。
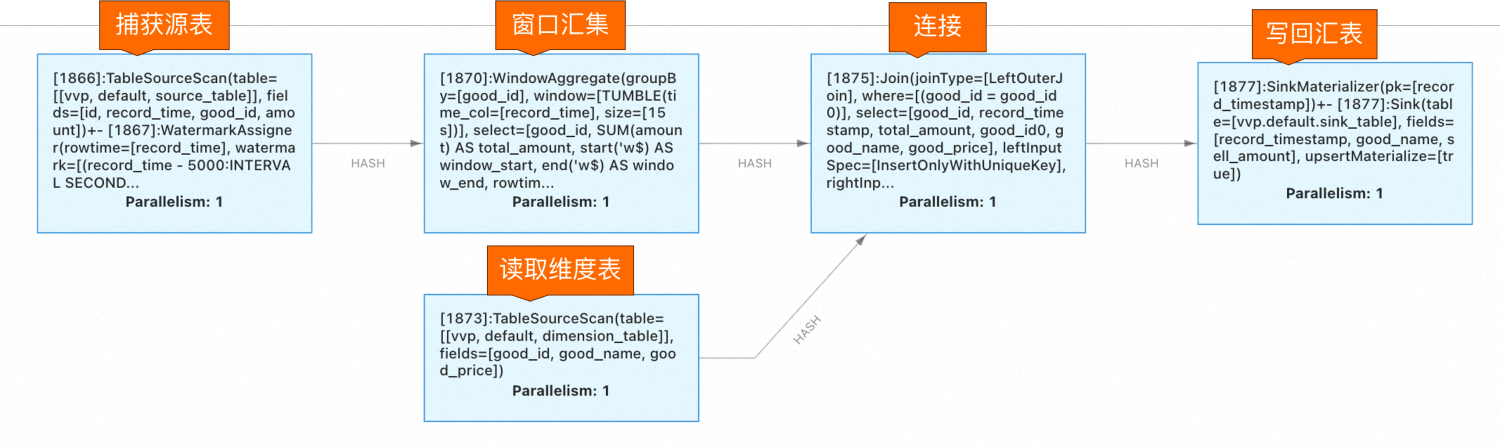
您也可以进入 Flink UI 控制台观察流数据处理图。在这个简单的示例中,首先进行的是源表数据的捕获与窗口聚合;接着和维度表进行 JOIN 操作得到运算结果;最后将处理数据存入汇表。
实验附件
以上就是本实验的全部步骤。完整的 Flink SQL 语句如下:
为了向云数据库 RDS 中填充示例数据,您可以在数据库后台执行下面的 SQL 语句:
或者,您也可以执行下面的 Python 脚本实时向数据库填充数据(需要安装 mysql-connector依赖):
实战营涉及的其他产品简介
可观测监控 Prometheus 版作为兼容可观测事实标准 – Prometheus 开源项
目的全托管服务。默认集成 Grafana 看板与智能告警功能。一键观测主流云
服务、自建组件/集群,覆盖业务监控/应用层监控/中间件监控/系统层监
控。全面优化探针性能与系统可用性,用户无需关注系统可用性与 Exporter
自研集成。帮助企业快速搭建一站式指标可观测体系。
负载均衡SLB是云原生时代应用高可用的基本要素,是阿里云官方云原生网关。SLB支持对4层、7层业务流量转发处理,通过将流量分发到不同的后端服务来扩展应用系统的服务吞吐能力,通过健康检查和故障自动隔离机制来消除单点故障并提升应用系统的可用性。SLB提供全托管式在线负载均衡服务,具有即开即用、超大容量、稳定可靠、弹性伸缩、按需付费等特点,适合大规模、高并发、高可用场景。
加入 Flink-Learning 实战营,动手体验真实有趣的实战场景。只需 2 小时,让您变身 Flink 实战派。实战营采取了 Flink 专家在线授课,专属社群答疑,助教全程陪伴的学习模式。
更多内容

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
0 元试用 实时计算 Flink 版(5000CU*小时,3 个月内)
了解活动详情:https://free.aliyun.com/?pipCode=sc

