前文中,我们给出了组成polardbx-sql的三个部分,并从目录入手介绍了重要模块/目录,最后不加解释的列出了一些关键接口作为调试代码的切入点。本文将从SQL执行角度出发,介绍polardbx-sql(CN)代码中与SQL解析执行相关的关键代码。
一、概述
“SQL的一生”特指从客户端创建连接发送SQL开始,到客户端收到返回结果结束,期间CN代码中发生的故事。与人的一生类似,从不同角度观测“SQL的一生”,有不同的结论,比如:
1)如果把CN看成是一个支持MySQL协议的网络程序,“SQL的一生”代表:接收用户连接请求,建立上下文,接收包含SQL的数据包,内部处理后按照MySQL协议组装数据包返回给客户端。
2) 如果把CN看成是一个SQL解释器,“SQL的一生”代表:接收SQL文本,经过词法解析、语法解析、语义解析得到逻辑计划,优化逻辑计划得到物理计划,执行物理计划得到最终结果。
3)如果把CN看成是一个任务执行引擎,“SQL的一生”代表:接收用户请求,转换为执行计划,确定调度策略,执行任务,返回结果。
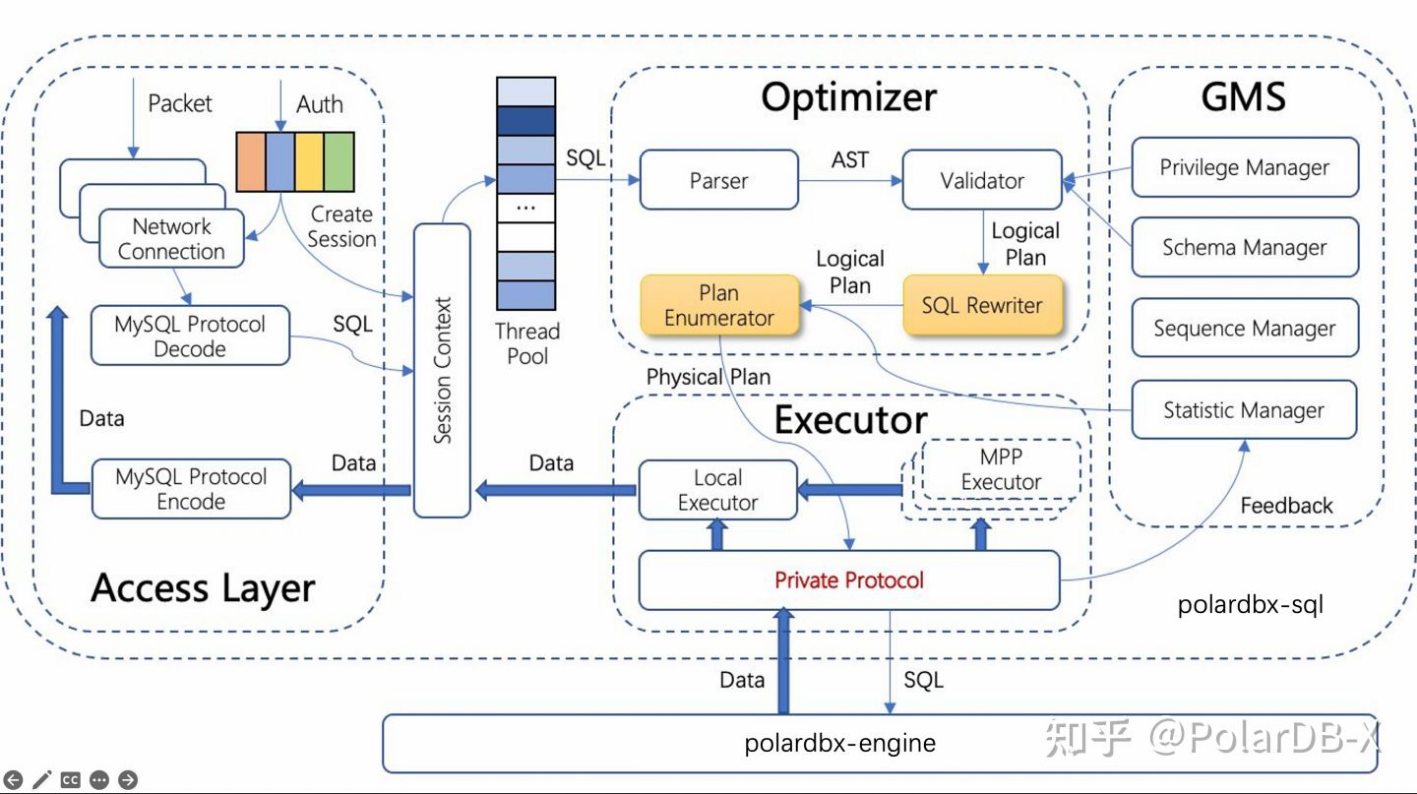
如上图所示,从整体上看,CN可以分为协议层、优化器、执行器三部分。“SQL的一生”从协议层开始,协议层负责接受用户连接请求,建立连接上下文,将用户发来的数据包转换为SQL语句,交给优化器生成物理执行计划。物理执行计划中包含本地执行的算子和下发给DN的物理SQL,执行器首先下发物理SQL到DN,然后汇总DN返回的结果交给本地执行的算子处理,最后将处理结果返回给协议层,按照MySQL协议封装成数据包后发送给用户。
下文中,会展开介绍协议层、优化器、执行器三部分在SQL解析执行过程的实现细节。
*由于篇幅关系,本文仅包含polardbx-sql(CN)相关内容,polardbx-engine(DN)相关内容留在后续文章中介绍。
二、 协议层
协议层首先要完成的工作是监听网络端口,等待用户建立连接,CN启动流程中介绍过,这部分逻辑在NIOAcceptor的构造函数中,每个CN进程只启动一个NIOAcceptor用于监听网络端口。

收到客户端发起的TCP连接请求后,协议层在NIOAcceptor#accept中将TCP连接绑定到一个NIOProcessor上,每个NIOProcessor会启动两个线程,分别用于读/写TCP数据包,读/写线程的实现封装在NIOReactor中。
同时,NIOAcceptor#accept中还将NIOProcessor和一个FrontendConnection对象绑定在一起。FrontendConnection中封装了MySQL协议处理逻辑和Session Context相关信息,有ServerConnection和ManagerConnection两个具体实现,ServerConnection用于处理客户端发送的SQL,ManagerConnection用于处理一些内部管理命令。
ServerConnection中解析MySQL协议数据包的逻辑封装NIOHandler中,有FrontendAuthorityAuthenticator和FrontendCommandHandler两个实现,分别用于鉴权和命令执行。
具体过程是,NIORreactor调用AbstractConnection#read完成ssl解析、大包重组等操作,得到具体要处理的数据包,然后调用FrontendConnection#handleData从线程池中获取一个新的线程,最后调用FrontendConnection#handler#handle接口完成鉴权和数据包解析。
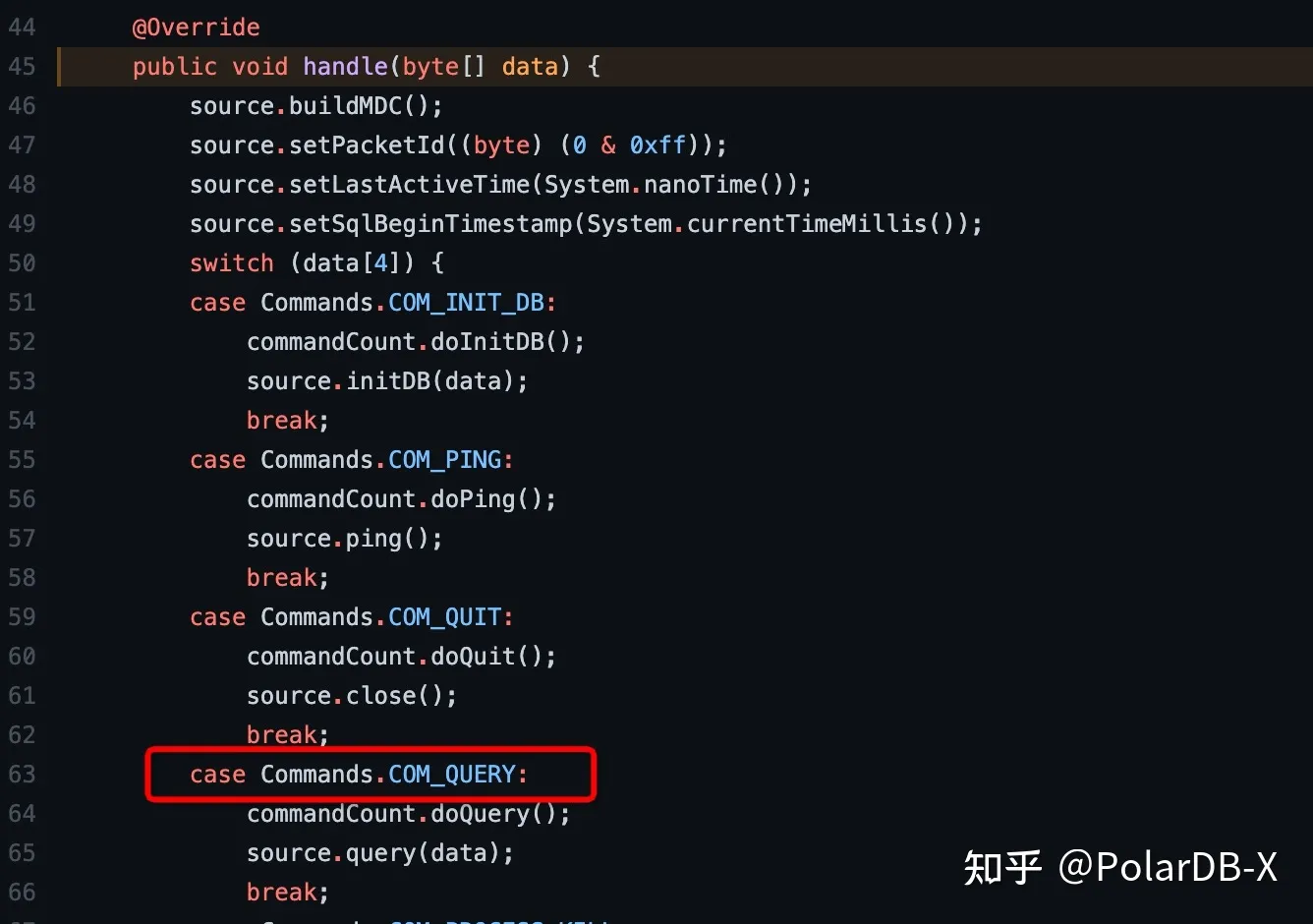
如上图所示,FrontendCommandHandler#handle中根据Command类型,调用不同的处理函数,最常用的Command是COM_QUERY,所有DML/DDL语句,只要没有通过PreparedStatement执行,Command都是COM_QUERY,对应的处理函数是FrontendConnection#query。
FrontendConnection#query方法继续解析数据包,得到SQL文本,传入ServerQueryHandler#queryRaw根据SQL种类分类执行,如果客户端发送的是MySQL Multi-Statement那么这里会将按照语法将多语句切开,分别下发执行。另外这里有个细节是ServerQueryHandler#executeStatement方法会为每个SQL语句生成一个唯一的traceId,traceId最终会出现在各种日志文件和实际下发的物理SQL的HINT中(从DN的binlog中可以获取到),用来排查问题十分方便。
常见的DML/DDL语句的处理逻辑封装在ServerConnection#innerExecute方法中,处理过程可以分为优化执行和返回数据包两部分。TConnection#executeQuery中封装了优化执行部分的逻辑,其中Planner#plan为优化器入口,PlanExecutor#execute为执行器入口。
执行结果包装成ResultCursor对象,在ServerConnection#sendSelectResult中读取结果,组装成COM_QUERY Response数据包返回给客户端。
执行过程中,ExecutionContext作为Session Context记录了执行计划属性/SQL参数/HINT等上下文信息,在三个模块之间传递。
三、优化器
和所有数据库一样,优化器模块的主干流程中包含Parser/Validator/SQL Rewriter(RBO)/Plan Enumerator(CBO)四个基础步骤,在此之上polardbx-sql结合自身特点增加了三个步骤:
Plan Management:包含Plan Cache和执行计划演进,用于消除执行计划生成带来的额外开销,和通过灰度演进避免CBO版本升级导致查询性能回退。
Mpp Planner:在Plan Enumerator之后增加一个阶段,针对MPP模式的执行计划,基于数据分区情况,减少shuffle。
Post Planner:结合参数进行分区裁剪,根据计划中每张表的裁剪结果继续执行下推,用于处理因为参数化无法进一步优化下推的场景。
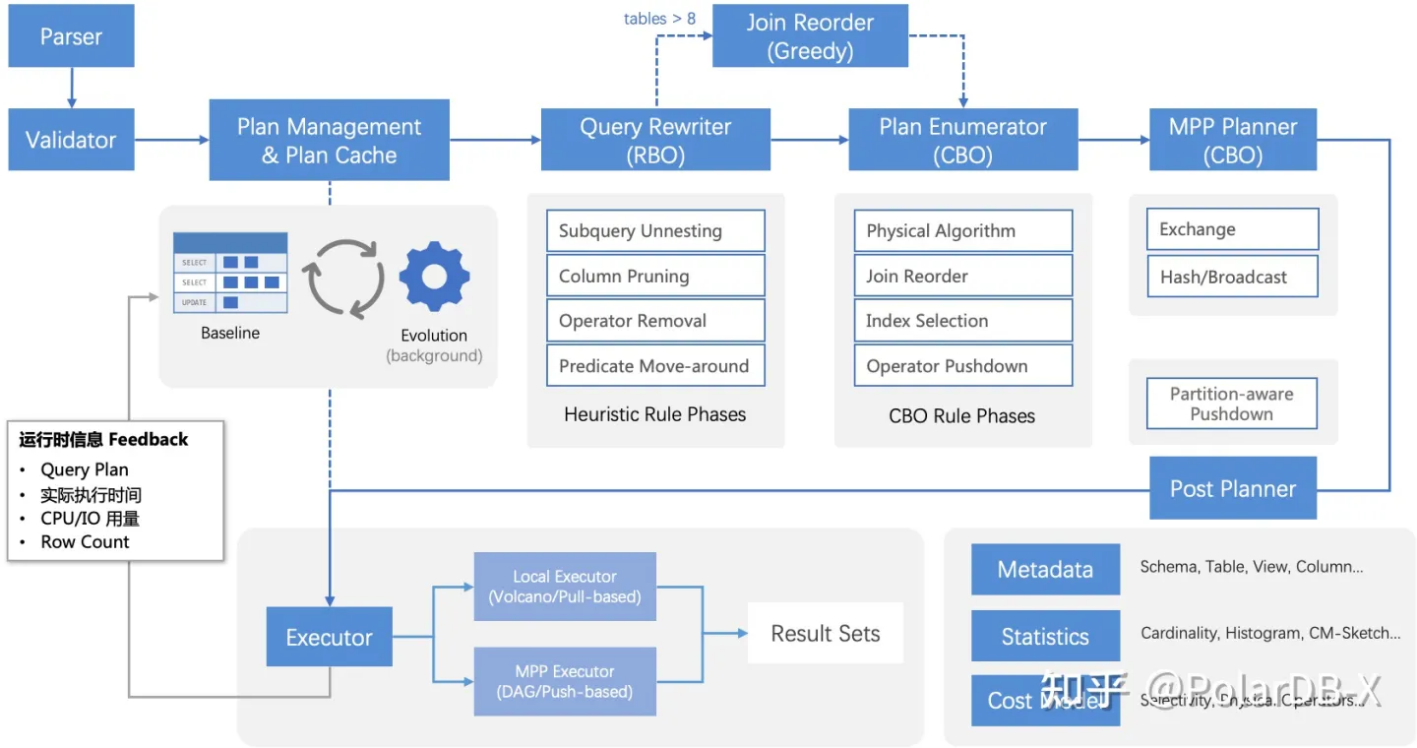
SQL在优化器中需要经过Parser--> Plan Management-->Validator-->SQL Rewriter(RBO)-->Plan Enumerator(CBO)-->Mpp Planner-->Post Planner七步处理,入口为Planner#plan,以下将展开介绍各个步骤中的关键接口。
四、Parser
Parser实现基于阿里巴巴开源的连接池管理软件Druid中的Parser组件,是一个手工编写的解析器,用于将SQL文本转换为抽象语法树(AST)。Parser本身包含用于词法解析的MySqlLexer和语法解析的MySqlStatementParser,为何这样划分超出了本文的范围,通过一个例子简单说明下。与我们阅读一句话类似,解析SQL时首先需要SQL文本切分为多个“单词”(Token),比如一条简单的查询语句。
SELECT * FROM t1 WHERE id > 1;
会被切分为如下Token
SELECT (keyword), * (identifier), FROM (keyword), t1 (identifier), WHERE (keword), id (identifier), > (gt), 1 (literal_int), ; (semicolon)
这个切分“单词”的过程就是词法解析。接下来,语法解析会按顺序读取所有Token,判断是否满足某个SQL子句语法的同时,生成AST,SELECT语句结果解析生成的对象是SqlSelect,如下图所示:
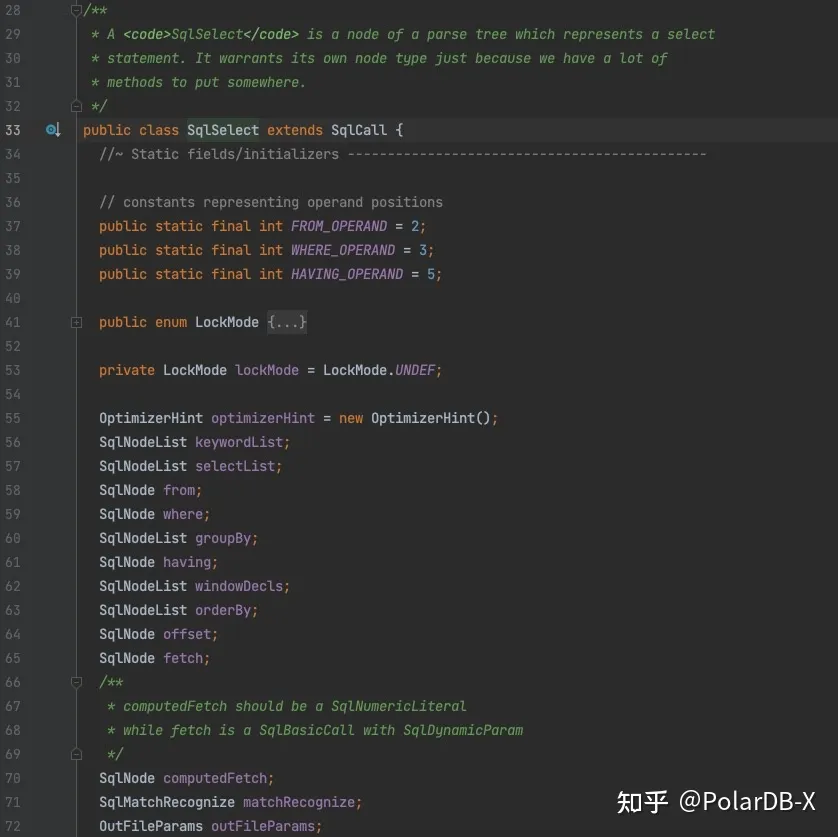
细心的同学可能注意到了,SqlSelect本身和其中成员变量的类型SqlNode都在polardbx-calcite包而不是polardbx-parser包中,原因是polardbx-sql使用了Apache Calcite作为优化器框架,整个框架与AST数据结构强绑定,因此SQL解析过程首先得到Druid的AST对象,然后通过一个visitor转换为SqlNode。代码在FastSqlToCalciteNodeVisitor,其中也包含了一些语法改写和权限校验。
另外,为了更好的支持Plan Cache,所有SQL需要首先进行参数化,也就是使用占位符替换SQL文本中的常量参数,将SQL文本转换为参数化SQL+参数列表,比如,SELECT*FROM t1 WHERE id>1会被转换为SELECT*FROM t1 WHERE id>?和一个参数1,这样做的好处是相同模版不同参数的SQL可以命中同一条Plan Cache,效率更高。当然也有缺点,当参数不同时整个查询的代价也不同,可能需要使用不同的计划,这个问题在Plan Management中得到了解决。参数化相关代码位于DrdsParameterizeSqlVisitor,实现上依然是一个visitor,返回结果封装在SqlParameterized对象中。
五、Plan Management & Plan Cache
从数据结构上讲,Plan Cache可以认为是一个以SQL模版、参数信息、元数据版本等信息为key,执行计划为value的一个map。用途是减少重复优化相同SQL模版带来的性能开销,以及结合执行计划演进消除可能由于版本升级带来的性能回退。关于Plan Management的详细介绍可以参考PolarDB-X优化器核心技术~执行计划管理。
调用Plan Cache和Plan Management的逻辑封装在Planner#doPlan中,Plan Cache的实现代码在PlanCache#get,Plan Management的实现代码在PlanManager#choosePlan。
实际上,Plan Cache的实现类似Java中的Map.computIfAbsent():如果map中存在已经生成好的执行计划,则直接返回执行计划;如果不存在则生成一个执行计划保存在map中然后返回这个执行计划。也就是说经过Plan Management&Plan Cache之后一定会拿到一个执行计划,Validator/SQL Rewriter/Plan Enumerator /Mpp Planner四个步骤其实是在Plan Cache内部被调用的,Post Planner由于依赖具体参数,不能Cache,需要拿到执行计划之后调用。
六、 Validator
早期的数据库实现经常在AST上直接进行查询优化,但由于AST缺少关系代数算子的层次结构,难以写出相互正交的优化规则,会导致所有优化逻辑堆叠在一起,维护困难。现代数据库实现通常都会在validating或者binding过程中将AST转换为关系代数算子组成的算子树作为逻辑计划,polardbx-sql也不例外。关于实现了哪些算子可以参考执行计划介绍。
AST到逻辑计划的转换分为两步,入口在Planner#getPlan,首先在SqlConverter#validate中进行语义检查,包括名字空间校验,类型校验等步骤,比较特别的一个点是SqlValidatorImpl#performUnconditionalRewrites中包含了一些对AST改写的内容,主要用于屏蔽相同语义的不同语法结构。然后SqlConverter#toRel中包含了将用SqlNode对象保存的AST转换为使用RelNode对象保存的逻辑计划,转换过程比较复杂这里不做展开。
七、SQL Rewriter
SQL Rewriter是polardbx-sql的RBO组件,工作内容是使用固定规则组对逻辑计划进行优化。polardbx-sql中RBO优化可以分为两个部分,一个是执行传统的关系代数优化(比如谓词推导、LEFT JOIN转INNER JOIN等),另一个是完成部计算下推工作(更多内容参考PolarDB-X优化器核心技术~计算下推)。
调用RBO的代码封装在Planner#optimizeBySqlWriter,RBO框架基于HepPlanner,实现了大量优化规则,规则分组信息保存在RuleToUse中,规则组执行的先后顺序记录在SQL_REWRITE_RULE_PHASE中。
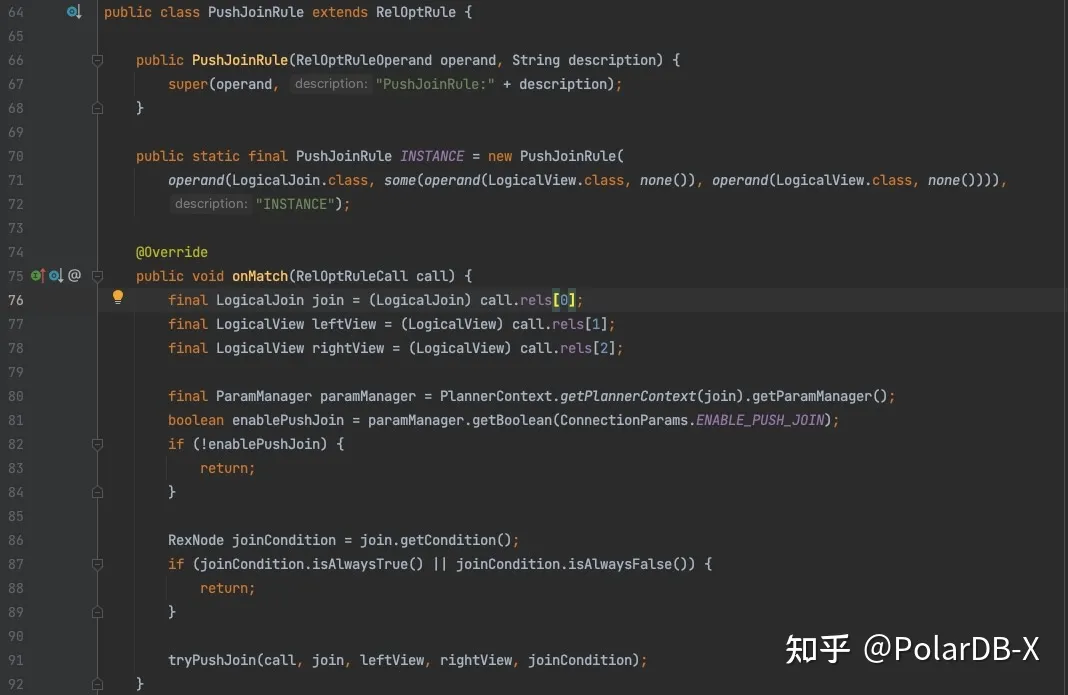
RBO规则要实现三个固定内容,匹配的子树结构、优化逻辑、返回变换后的计划。上图展示的是用于下推JOIN的规则,70-72行在构造函数中指明这个规则匹配的是LogicalJoin下挂两个LogicalView的算子树,当RBO框架匹配到这种子树时会调用规则的onMatch接口,规则完成优化后,调用RelOptRuleCall.transformTo返回变换后的计划。
RBO框架按照组内乱序执行,组间串行执行的方式执行SQL_REWRITE_RULE_PHASE列出的所有规则,每条规则都会反复匹配,直到某一轮匹配后,一组内的规则全都没有命中,则认为该组执行结束。
八、Plan Enumerator
Plan Enumerator是polardbx-sql的CBO组件,工作是生成/枚举物理执行计划,并根据代价选出最合适的物理执行计划,具体包括Join Reorder、索引选择、物理执行计划选择等,详细介绍参考PolarDB-X CBO优化器技术内幕。
调用CBO的代码封装在Planner#optimizeByPlanEnumerator中,CBO框架基于VolcanoPlanner框架,与RBO不同,CBO规则无需提前分组,所有用到的规则都保存在RuleToUse#CBO_BASE_RULE中。与RBO规则相同,CBO规则的执行流程也是匹配一颗子树然后返回变换后的计划,区别在于CBO不会直接用新生成的计划替换原来的子树,而是将生成的新的执行计划保存在RelSubset中,后续从RelSubset中选出代价最低的一个计划,代码入口在VolcanoPlanner#findBestExp。
九、Mpp Planner
Mpp Planner是polardbx-sql针对MPP执行计划增加的优化阶段,负责根据数据分布生成exchange算子,减少冗余的数据shuffle。代码入口在Planner#optimizeByMppPlan,生成MppExchange算子的代码在MppExpandConversionRule#enforce。
十、Post Planner
Post Planner主要用于带入实际参数进行分区裁剪后,根据下发的分片情况二次下推执行计划。假设表r和表t在一个table group中,拆分字段都是id,考虑下面的SQL。
SELECT*FROMr JOIN t ON r.name = t.name WHERE r.id = 0 AND t.id = 1;
RBO / CBO 中看到的是参数化之后的计划,类似
SELECT * FROM r JOIN t ON r.name = t.name WHERE r.id = ? AND t.id = ?;
由于没有分区键上的相等条件,无法确定所需的数据是否落在相同的partition group上,但是结合参数进行分区裁剪之后,就会发现其实数据都落在0号分片上,是一条单分片Join语句,可以直接下发。
PostPlanner在Planner中被调用,实现代码在PostPlanner#optimize中。
十一、执行器

PolarDB-X执行器支持两种执行模型,传统的Volcano迭代模型和支持Pipeline向量化的push模型,两种模型各有优劣详细介绍参考PolarDB-X面向HTAP的混合执行器。执行计划进入执行器后存在三条可选的执行链路:Cursor、Local、Mpp。Cursor链路用于执行DML/DDL/DAL语句,Local、Mpp链路用于执行DQL语句。Cursor 链路仅支持Volcano迭代模型,Local链路同时支持两种模型,Mpp链路在Local链路的基础上增加了多机任务调度。
执行器入口代码在PlanExecutor#execByExecPlanNodeByOne,之后在ExecutorHelper#execute中根据优化器确定的执行模式选择执行链路。以下以Cursor链路为例介绍计划执行的整体流程。
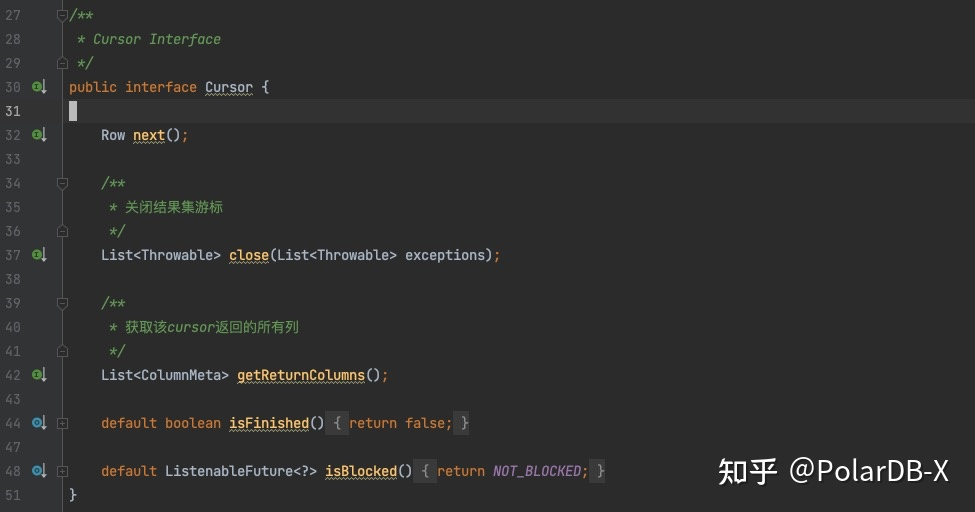
Cursor链路中,首先根据执行计中的算子找到对应的handler,代码位置在CommandHandlerFactoryMyImp#getCommandHandler,handler负责将当前算子转换为一个Cursor接口的具体实现,并且嵌套的调用CommandHandlerFactoryMyImp#getCommandHandler接口将整个执行计划转换为一颗Cursor树。ResultSetUtil#resultSetToPacket中调用Cursor.next接口获取全部执行结果返回给用户。


Local链路的执行入口在SqlQueryLocalExecution#start,首先在LocalExecutionPlanner#plan中将执行计划切分为多个Pipeline,切分的具体逻辑在LocalExecutionPlanner#visit,然后为每个Pipeline生成一个包含具体执行逻辑的Driver放入调度队列,执行逻辑封装在Executor或者ConsumerExecutor中,分别代表迭代模型和push模型。执行结果封装在SmpResultCursor中,与Cursor相同,ResultSetUtil#resultSetToPacket中调用Cursor.next接口获取全部执行结果返回给用户。
Mpp链路的执行入口在SqlQueryExecution#start,首先在PlanFragmenter#buildRootFragment中根据MppPlanner插入的Exchange算子将执行计划切分成多个Fragment,之后在SqlQueryScheduler#schedule中调用StageScheduler生成和下发并行计算任务,任务信息封装在HttpRemoteTask对象中,并行计算任务下发到执行节点后的执行链路与Local链路相同。关于Mpp链路的更多原理介绍请参考PolarDB-X并行计算框架。
十二、小结
本文从SQL执行的角度出发,介绍了协议层、优化器、执行器的关键代码。协议层负责网络连接管理、数据包到SQL和执行结果到数据包的转换,第一小节介绍协议层的执行流程,并给出了基于NIO的网络连接管理、SSL协议解析、鉴权、协议解析、大包重组等内容的代码入口。优化器负责SQL到执行计划的转换,转换过程包含七个阶段Parser-->Plan Management-->Validator-->SQL Rewriter(RBO)-->Plan Enumerator(CBO)-->Mpp Planner-->Post Planner,第二小节简单介绍了每个阶段的工作内容并给出了代码入口。执行器负责根据执行计划获得最终执行结果,支持迭代模型和Pipeline向量化模型,分为Cursor、Local和MPP三条执行链路,第三小节介绍了各个链路的基本流程和关键入口。


![[版本更新] PolarDB-X V2.4 列存引擎开源正式发布](https://ucc.alicdn.com/pic/developer-ecology/nmwxanvmfezte_85c4d30b1404479b982cc86614e8edfb.png?x-oss-process=image/resize,h_160,m_lfit)