1 论文&代码
论文链接
https://arxiv.org/pdf/2210.15511.pdf
开源代码
https://github.com/jp-lan/ProContEXT
开源应用
https://modelscope.cn/models/damo/cv_vitb_video-single-object-tracking_procontext/summary
2背景介绍
视频目标跟踪(Video Object Tracking, VOT)任务以一段视频和第一帧中待跟踪目标的位置信息(矩形框)作为输入,在后续视频帧中预测该跟踪目标的精确位置。该任务对跟踪目标的类别没有限制,目的在于跟踪感兴趣的目标实例。该算法在学术界和工业界都是非常重要的一个研究课题,在自动驾驶、人机交互、视频监控领域都有广泛应用。
如图1所示,对于一个输入视频,待跟踪跟踪物体(红色虚线圆)会随着时间而产生剧烈变化,相比于初始帧中的目标外观,待跟踪帧中的目标外观会与中间帧的目标外观更相似,因此中间帧的目标外观形态是一个非常好的时域上下文信息。另外,对于跟踪过程中目标物体周围的空域上下文信息对算法鉴别相似物体和干扰背景有很大的帮助。
最近,一些基于Transformer网络的视频目标跟踪算法,比如OSTrack[1], MixFormer[2], STARK[3]等,展现了较高的算法精度,基于之前的研究工作,本文提出了ProContEXT(ProgressiveContextEncodingTransformerTracker),把时域上下文信息和空域上下文信息共同引入到Transformer网络中。
ProContEXT的整体结构如图2所示,该方法具有如下的特点:
SOTA对比首先,与目前SOTA方法的对比如下表所示,ProContEXT在TrackingNet数据集和在GOT-10K数据集均超过对比的算法,达到SOTA精度。
消融实验本文对静态模板数目进行了消融实验,结果如下表所示,当使用2个静态模板时,效果最佳。表中实验数据说明当使用更多静态模板数目时,会引入冗余信息,导致跟踪效果下降。
另外,对动态模板的数目和尺度也进行了消融实验,结果如下表所示,当加入动态模板时,跟踪算法精度均有提升,并且使用两个尺度的动态模板比只使用单个尺度算法精度有进一步提升。
最后,对于算法中使用到的令牌修剪模块中的超参也进行了探索,实验结果如下表所示,当参数为0.7时达到算法精度和效率的最加平衡。
由于输入视频的多样性,目标跟踪算法需要适应诸如尺度变化、形状变化、光照变化、遮挡等诸多挑战。特别是在待跟踪目标外观变化剧烈、周围存在相似物体干扰的情况下,跟踪算法的精度往往急剧下降,甚至出现跟踪失败的情况。

图1 上下文信息在跟踪过程中发挥着重要作用
3方法介绍

图2 ProContEXT的整体结构
ProContEXT是一种渐进式上下文感知的Transformer跟踪器,在Transfomer跟踪器中利用了动态的时域信息和多样的空域信息进行特征提取,从而能获得更加鲁邦的跟踪特征。
ProContEXT通过改进ViT主干网络,在输入中增加了多尺度静态模板(static templates)和多尺度动态模板(dynamic templates),并通过上下文感知的自注意力机制模块充分利用视频跟踪过程中目标的时域上下文和空域上下文信息。通过渐进式的模板优化和更新机制,跟踪器能快速适应目标的外观变化。
ProContEXT在多个公开数据集中(TrackingNet和GOT-10k)获得SOTA性能,并且运行效率完全达到实时要求,速度为54.3FPS.
4实验结果
本文基于TrackingNet和GOT-10k数据集进行算法实验,完全遵守各数据集的使用准则。
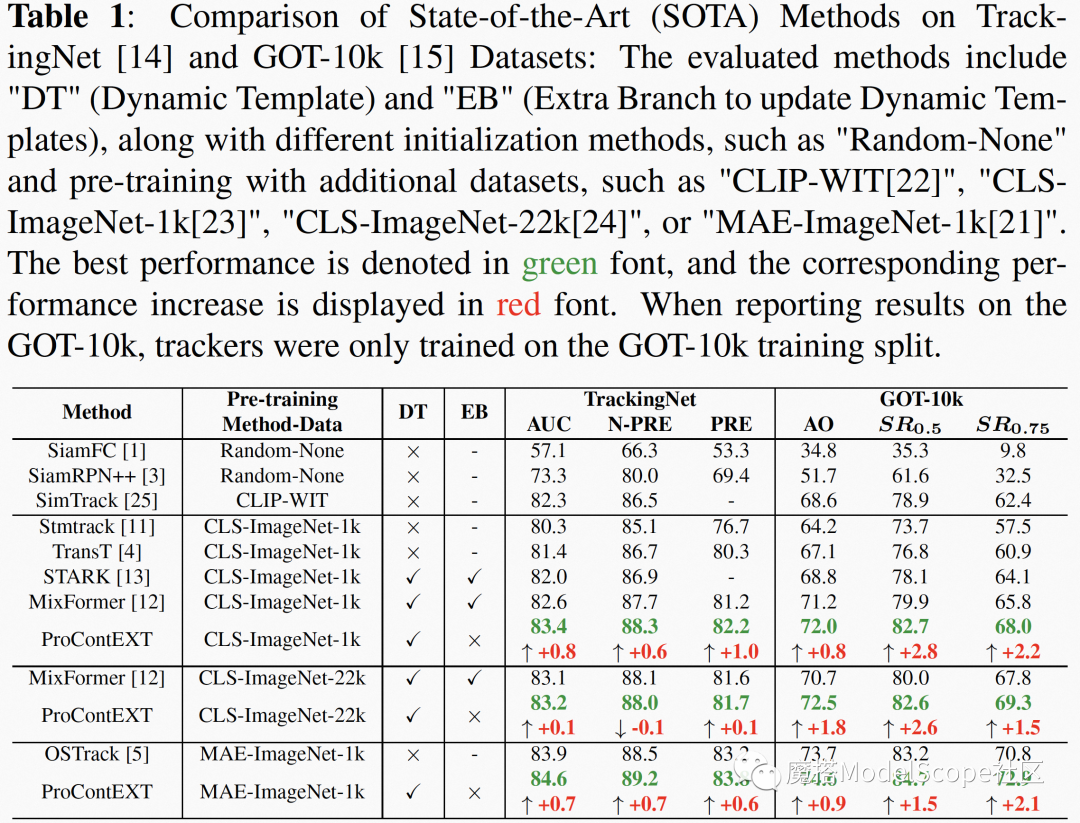
表1 与SOTA对比

表2 静态模板数目消融实验

表3 动态模板消融实验
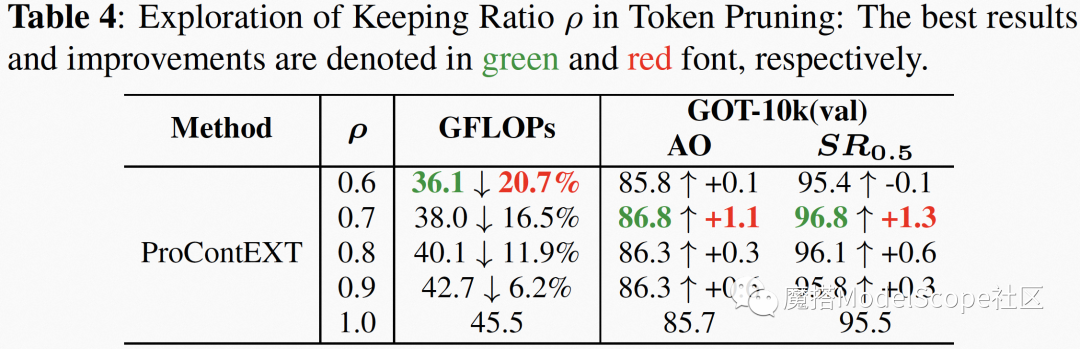
表4 令牌修剪模块消融实验
5模型传送门
视频跟踪模型视频单目标跟踪ProContEXT:https://modelscope.cn/models/damo/cv_vitb_video-single-object-tracking_procontext/summary
视频单目标跟踪OSTrack:https://modelscope.cn/models/damo/cv_vitb_video-single-object-tracking_ostrack/summary
视频多目标跟踪FairMOT:https://modelscope.cn/models/damo/cv_yolov5_video-multi-object-tracking_fairmot/summary
检测相关模型实时目标检测模型YOLOX:https://modelscope.cn/models/damo/cv_cspnet_image-object-detection_yolox/summary
高精度目标检测模型DINO:https://modelscope.cn/models/damo/cv_swinl_image-object-detection_dino/summary
实时目标检测模型DAMO-YOLO:https://modelscope.cn/models/damo/cv_tinynas_object-detection_damoyolo/summary
垂直行业目标检测模型:https://modelscope.cn/models?page=1&tasks=vision-detection-tracking%3Adomain-specific-object-detection&type=cv
关键点相关模型
2D人体关键点检测模型-HRNet:https://modelscope.cn/models/damo/cv_hrnetv2w32_body-2d-keypoints_image/summary
2D人脸关键点检测模型-MobileNet:https://modelscope.cn/models/damo/cv_mobilenet_face-2d-keypoints_alignment/summary
2D手部关键点检测模型-HRNet:https://modelscope.cn/models/damo/cv_hrnetw18_hand-pose-keypoints_coco-wholebody/summary
3D人体关键点检测模型-HDFormer:https://modelscope.cn/models/damo/cv_hdformer_body-3d-keypoints_video/summary
3D人体关键点检测模型-TPNet:https://modelscope.cn/models/damo/cv_canonical_body-3d-keypoints_video/summary
检测套件开发工具
ModelScope社区视觉检测开发套件https://github.com/modelscope/AdaDet
更多模型详见 ModelScope.cn
6参考文献
[1] Ye B, Chang H, Ma B, et al., "Joint feature learning and relation modeling for tracking: A one-stream framework", in ECCV 2022, pp. 341-357.
[2] Cui Y, Jiang C, Wang L, et al., "Mixformer: End-to-end tracking with iterative mixed attention", in CVPR 2022, pp. 13608-13618.[3] Yan B, Peng H, Fu J, et al., "Learning spatio-temporal transformer for visual tracking", in ICCV 2021, pp. 10448-10457.

