
使用是按照ModelScope模型介绍的示例的方式,怎么处理?
"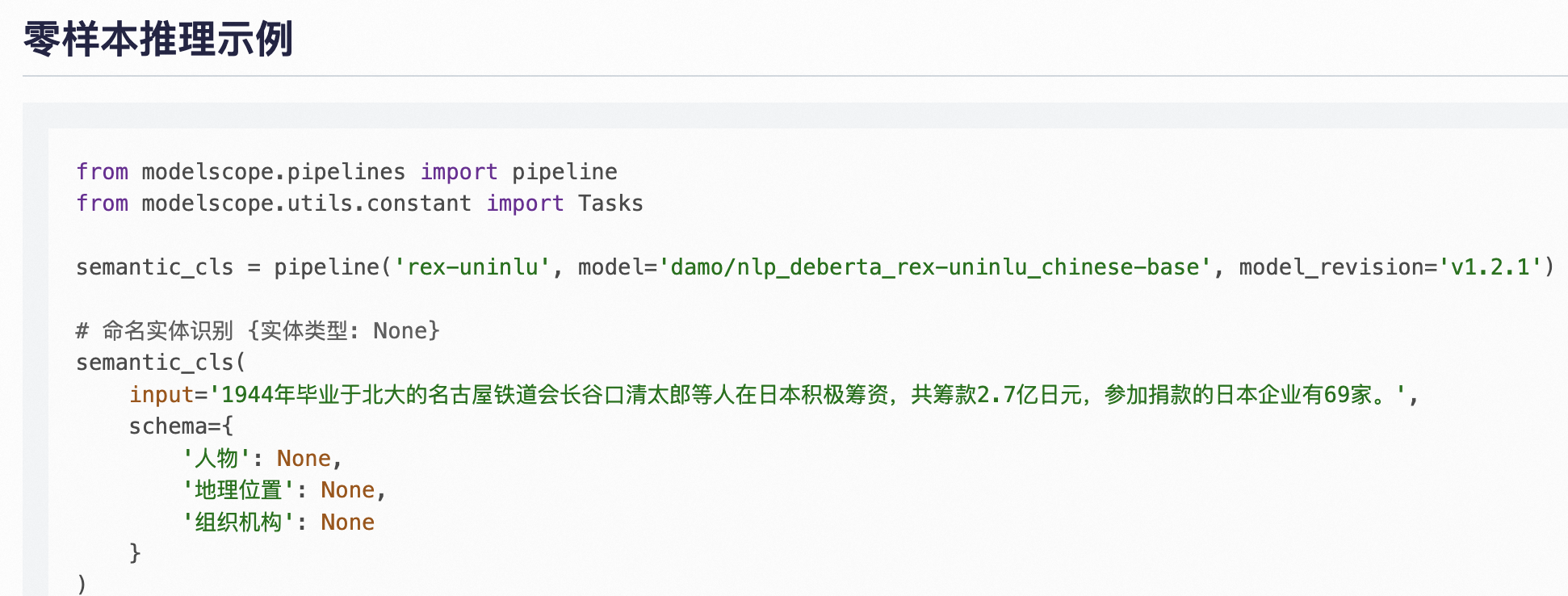
使用是按照ModelScope模型介绍的示例的方式,怎么处理?"
展开
收起
1
条回答
 写回答
写回答
-

2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
在使用ModelScope模型时,通常会遵循以下步骤来处理问题:
- 选择模型: 首先,你需要在ModelScope平台上找到适合你任务的模型。你可以通过搜索关键词、查看分类或浏览推荐来找到合适的模型。
- 阅读模型文档: 一旦选定模型,务必详细阅读模型的文档。文档通常会包含模型的介绍、适用场景、性能指标、使用示例以及依赖库等重要信息。
- 安装和导入: 根据文档的指示,安装必要的Python库(如
modelscope或huggingface等),然后在代码中导入模型。例如,如果使用Hugging Face的Transformers库,你可能会看到类似以下的代码:
python from transformers import AutoModel, AutoTokenizer model = AutoModel.from_pretrained("model_name") tokenizer = AutoTokenizer.from_pretrained("model_name")- 预处理数据: 使用模型的tokenizer对输入数据进行预处理,将其转换为模型可以接受的格式。例如:
python input_ids = tokenizer.encode("your text here", return_tensors="pt")- 模型推理: 调用模型进行预测或推理。这可能包括编码、解码、分类等操作,具体取决于模型的用途:
python outputs = model(input_ids)- 后处理结果: 对模型的输出进行后处理,得到最终的结果。例如,对于生成任务,可能需要解码输出的tokens;对于分类任务,可能需要提取logits并转换为类别:
python decoded_text = tokenizer.decode(outputs[0])- 运行示例代码: 根据模型文档中的示例代码,将你的输入数据替换到代码中,运行并查看输出。确保你的环境设置正确,所有依赖都已安装。
- 调整参数: 根据需要,可能需要调整模型的超参数,以优化模型在你的特定任务上的性能。
- 保存和加载模型: 为了以后使用或部署,你可以保存模型的权重,以便在需要时快速加载:
python model.save_pretrained("path/to/save") # 加载模型 model = AutoModel.from_pretrained("path/to/save")- 持续学习和优化: 根据模型的表现和需求,你可能需要进一步训练模型,或者寻找其他模型进行对比。
确保在整个过程中,你密切关注任何错误消息,以便及时解决可能出现的问题。如果遇到困难,ModelScope的文档、官方论坛或开发者社区通常会提供帮助。
2024-05-01 18:57:23赞同 展开评论 打赏

相关问答
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352
热门讨论
热门文章
com/action/joingroup?code=v1是什么意思
3030
ModelScope中,模型下载默认路径在哪个路径?
2281
ModelScope的Qwen1.5-14B-Chat需要多少大显存?
1497
如何训练属于自己的“通义千问”呢?
4815
ModelScope qwen7b、14b、72b lora微调分别需要的显存和cpu内存是多少?
638
我希望通过damo-YOLO训练1500*1500的图片
6790
请问ModelScope中,怎么修改本地运行,模型自动下载到 c 盘下?
2841
服务器上onnxruntime-gpu 调用结束,如何释放显存
3101
Modelscope魔塔的创空间的文件怎么下载到本地呀?
3067
ModelScope 使用14B模型推理时报这个错误?
739
展开全部
阿里云通义千问向全社会开放!
18234
Llama 3开源!魔搭社区手把手带你推理,部署,微调和评估
3136
阿里云助力开发者创新:探索云原生技术的新境界
275
ModelScope--人像卡通化、人像美肤
51916
千亿大模型来了!通义千问110B模型开源,魔搭社区推理、微调最佳实践
667
Qwen1.5开源!魔搭最佳实践来啦!
2611
ChatGPT中文版杀疯了,已登录AI模型市场
11879
新一代端侧模型,面壁 MiniCPM 2.0开源,魔搭社区最佳实践
320
LLM大模型实战 —— DB-GPT阿里云部署指南
7086
Llama3 中文通用Agent微调模型来啦!(附手把手微调实战教程)
577
展开全部




