2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
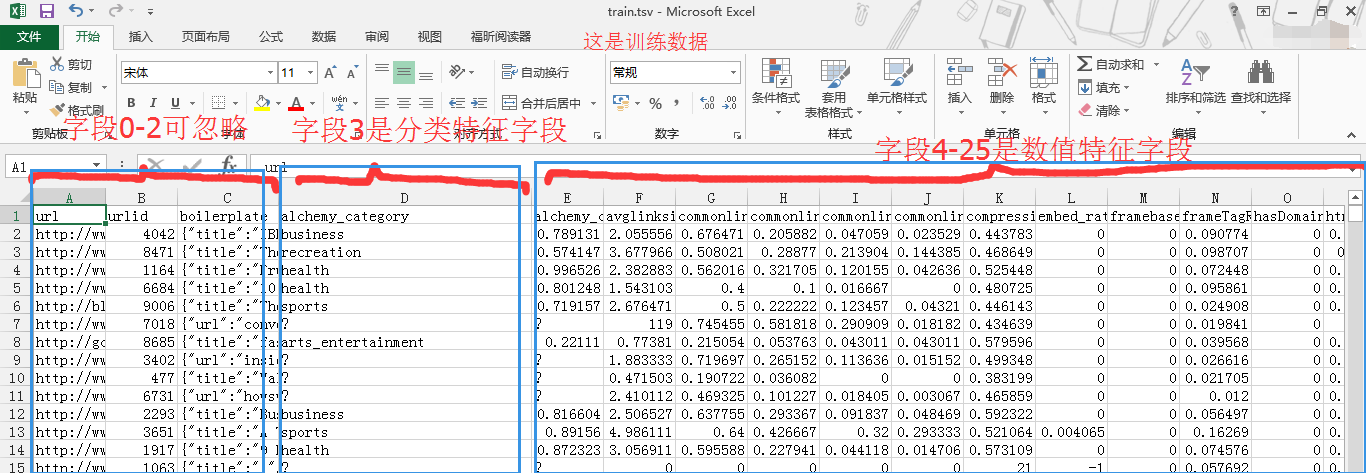
字段3 是分类特征字段,但是呢,在分类算法里不能直接用。所以,必须要转换为数值字段才能够被分类算法使用。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/7450754.html,如需转载请自行联系原作者
2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
字段3 是分类特征字段,但是呢,在分类算法里不能直接用。所以,必须要转换为数值字段才能够被分类算法使用。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/7450754.html,如需转载请自行联系原作者
