进程地址空间
你大概率在C/C++学习过程中,见过如下内存分布图:

简单来说,就是从低地址往高地址,内存分区分别是:
- 代码段:存储
可执行代码和只读常量 - 数据段:存储
全局变量和静态数据 - 堆区:用于
动态内存管理,堆区内存往高处增长 - 栈区:大部分
局部变量,栈区内存往低处增长 - 内核空间:
命令行参数argv和环境变量env等
我可以用一段代码来证明这张图片的正确性:
#include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <sys/types.h> int g_unval; int g_val = 100; int main(int argc, char* argv[], char* env[]) { printf("正文代码: %p\n", main); printf("初始化数据: %p\n", &g_val); printf("未初始化数据: %p\n", &g_unval); int* heap1 = (int*)malloc(sizeof(int) * 1); int* heap2 = (int*)malloc(sizeof(int) * 1); int* heap3 = (int*)malloc(sizeof(int) * 1); printf("堆区地址 heap1: %p\n", heap1); printf("堆区地址 heap2: %p\n", heap2); printf("堆区地址 heap3: %p\n", heap3); printf("栈区地址 &heap1: %p\n", &heap1); printf("栈区地址 &heap2: %p\n", &heap2); printf("栈区地址 &heap3: %p\n", &heap3); printf("命令行参数地址 &argv[0]: %p\n", &argv[0]); printf("环境变量地址 &env[0]: %p\n", &env[0]); return 0; }
我们首先输出了main函数的地址,此处有一个小知识点:函数名的本质就是地址,所以main和&main是一样的。函数存储在代码段,所以此处也代表代码段的地址。
其中变量g_val是一个全局变量,存储在数据段,g_unval也是一个全局变量,存储在数据段,不过两者一个初始化了,一个没初始化。它们两个代表常量区的地址。
随后我们malloc了三个地址出来,分别赋值给三个指针,然后输出了三条堆区地址,之所以要输出三条,是为了展示堆区的内存增长方向。
然后再输出了&heap1,&heap2,&heap3,虽然三个指针指向堆区内存,可指针变量本身是存储在栈区的,所以这三个语句代表了栈区的地址。
最后分别输出了一个环境变量&env[0]和命令行参数&argv[0],它们代表Linux内核数据。
输出结果:

可以看到,不同分区地址是越来越大的,也就是:
代码段<数据段<堆区<栈区<OS内核
其中还有三个区域内部的小问题:
- 同为
数据段的内存,初始化过的g_val地址比未初始化的g_unval地址更低,也就是数据段中初始化过的数据会存在更低的地址 - 同为
堆区的内存,先开辟的heap1出现在最低的地址,后开辟的heap3出现在最高的地址,也就是堆区中越后开辟的内存,地址越高,地址是向高处增长的 - 同为
栈区的内存,先开辟的&heap1出现在最高的地址,后开辟的&heap3出现在最低的地址,也就是栈区中越后开辟的内存,地址越低,地址是向低处增长的
这样一套体系,叫做进程地址空间,那么这是真实的内存空间吗?
为了解决这个问题,那就要先说说什么是虚拟地址了。
虚拟地址
先看到以下案例:
#include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <sys/types.h> int main() { int val = 3; pid_t id = fork(); if(id == 0) { printf("child: val = %d, &val = %p\n", val, &val); val = 5; sleep(1); printf("child: val = %d, &val = %p\n", val, &val); return 0; } printf("parent:val = %d, &val = %p\n", val, &val); sleep(2); printf("parent:val = %d, &val = %p\n", val, &val); return 0; }
以上代码中,先定义了一个变量val = 3,然后通过fork创建了子进程。对于子进程,先输出val的值和val的地址,然后再修改val的值为5,再输出一次val的值和val的地址;对于父进程,也输出两次val的值和val的地址,由于父进程sleep两秒,子进程sleep一秒,所以父进程第二次输出,子进程已经修改过val了。
输出结果:

以上输出结果中,父进程的val一直为3,这是毫无疑问的,因为进程具有独立性,父子进程的数据互不影响。子进程刚被创建时,和父进程共用数据和代码,因此父子进程第一次输出val的值的时候,不论值和地址都是一样的。
但是问题就出在子进程修改了val的值之后,为什么父子进程的val明明不同了,&val还是一样的?
那么有可能一个地址存储两个不同的值吗?显然是不可能的,这已经不是语法问题了,而是计算机组成原理的问题,一块内存毫无疑问同时只能存储一个值。那为什么此处父子进程的val值不同,但是地址相同?那就只有一个可能:这个地址不是物理地址,而是假的地址!
在语言层面接触到的地址,都不是物理地址,而是虚拟地址
也就是说,不论是C/C++,以及任何语言,所使用的地址都是虚拟地址,而不是在内存中真正的地址!
进程地址空间的管理
那么我们再回到一开始的进程地址空间,既然我们拿到的不是真实的地址,但是我们又要去物理地址中存储数据怎么办?
实际中,操作系统中有一个叫做页表的东西,其会维护虚拟地址与物理地址之间的映射关系,当进程通过虚拟地址在进程地址空间中查找数据,其实本质上是拿着虚拟地址到页表中查找映射关系,进而找到真实的物理地址,再对数据进行访问。

那么我们再看看当时讲虚拟地址的时候遇到的问题:为什么父子进程会让同一个虚拟地址存储不同的数据?
子进程被创建的时候,会继承父进程的大量数据,其中页表也会被继承:

当子进程继承到父进程的页表时,大部分内容都不会改动,而是直接拷贝,包括虚拟地址与物理地址的映射关系在内!!!
也就是说,子进程继承到的页表,其虚拟地址和父进程是一样的,比如上图中,两进程对val的虚拟地址是一样的,因为子进程继承到了父进程中val的虚拟地址。
当子进程对val进行修改的时候,此时发送写时拷贝:

子进程会把原先与父进程共用的val拷贝一份到别的地方,然后修改val = 5。这个过程中,对于子进程来说,val的物理地址改变了,于是对页表的映射关系进行修改,此时val的虚拟地址不变,但是虚拟地址对应的物理地址改变了!因此这个过程只修改物理地址,不修改虚拟地址。
所以我们在修改了子进程中的val之后,观察到父子进程的val的地址一样,这是因为父子进程对val的虚拟地址是一样的,但是这个时候由于父子进程的页表不同,映射关系不同,最后访问到的物理地址其实是不一样的。因此我们输出的时候看到了一个地址两个值的情况。
接下来我们看看Linux是如何管理这个进程地址空间的:
系统层面管理
在系统层面,也就是Linux系统中,进程地址空间被存储在PCB中,作为进程的一项属性。而进程地址空间本身被一个叫做mm_struct结构体管理,
我们一开始就给出了进程地址空间的视图:

那么毫无疑问mm_struct的第一大要务,就是给进程地址空间进行分区操作。在mm_struct内部,会存储每一个分区的开始和结束的地址,然后根据这个地址的范围,来判断该地址属于哪一个区域。
比如以下代码是Linux 2.6内核中mm_struct的一部分源码:
unsigned long total_vm, locked_vm, shared_vm, exec_vm; unsigned long stackvm, reserved_vm, def_flags, nr_ptes; unsigned long start_code, end_code, start_data, end_data; unsigned long start_brk, brk, start_stack; unsigned long arg_start, arg_end, env_start, env_end;
比如其中start_code表示代码段的开始,end_code表示代码段的结束,start_data表示数据段的开始,end_data表示数据段的结束。
mm_struct大致视图如下:

从左往右task_struct就是进程PCB,mm_struct就是进程地址空间,page table就是页表,physical memory就是物理内存,这一套体系我们已经在本博客前面都讲过了。
硬件层面管理
虚拟地址是不具备存储数据的能力的,而我们在语言中得到的地址都是虚拟地址,那么CPU是如何通过页表把虚拟地址转物理地址的呢?
在CPU中,存在一个叫做MMU的单元,Memory Management Unit - 内存管理单元,其可以把虚拟地址转换为物理地址:
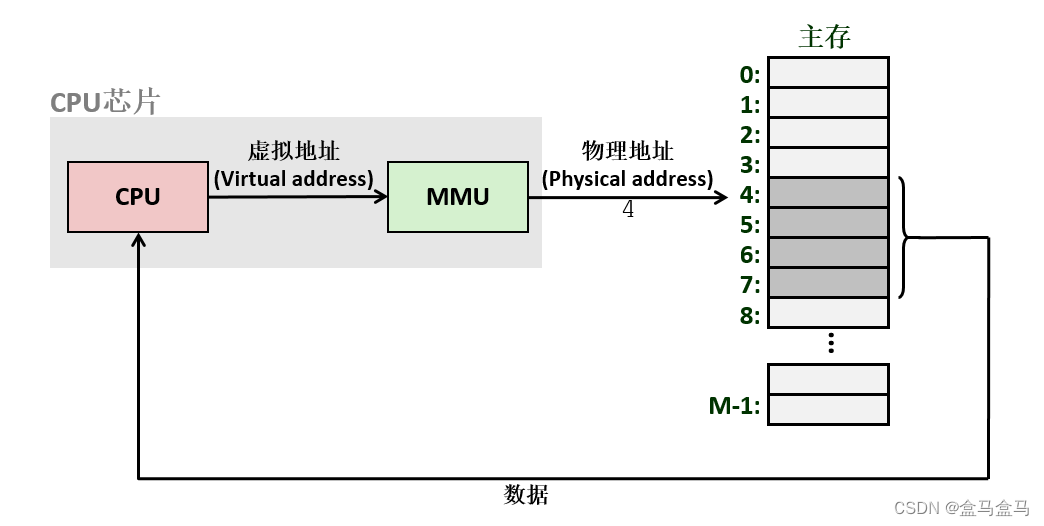
当CPU拿到要执行的代码时,拿到的是虚拟地址,然后通过MMU将虚拟地址转化为物理地址,最后到内存中去访问物理地址。
那么MMU又是怎么把虚拟地址转化为物理地址的?在MMU中,有一个叫做CR3的寄存器,CR3中存储了页表,因此MMU可以通过CR3访问页表,进而到页表中查询映射关系,找到物理地址。
进程地址空间意义
- 由于页表的存在,无序的地址变为了有序的地址
在为进程分配内存的时候,分配的内存是比较散乱的,此时就会导致地址非常杂乱无章可循。当通过页表映射,把指向相同功能的内存地址放到一起,此时我们就有的栈区,堆区,静态区等等区域,更好地统一管理地址了。
- 将进程管理和内存管理解耦
由于页表的存在,此时进程管理和内存管理就是互不影响的。进程只需要去读取内存,申请内存等,无需考虑硬件层面的内存是如何管理的。对于磁盘,只需要做好加载数据到内存的工作,加载完数据后,无需考虑进程是如何读取地址,如何获取数据的。
- 保护了内存安全
当用于向内存发出非法访问时,进程地址空间就可以检测出来,比如访问越界的内存等等。此时内存中的数据不会受到任何影响,因为该错误已经被进程地址空间检测并处理了。
比如我们通过指针向非法的内存进行写入,那么进程地址空间就可以检测出来该地址是超出了某个范围的,在操作系统层面就直接报错,而不会真的等到对内存写入了数据之后,才发现该访问非法。
- 确保了进程的独立性
进程 = 内核数据结构 + 进程自己的代码和数据。通过进程地址空间的映射,每个进程都有自己的内核数据结构,自己的代码,自己的数据,相互之间完全独立互不影响。
比如下图:

左右侧是不同的两个进程,它们的页表,PCB等等内核数据结构都是独立的,互相之间不会影响。
动态内存管理底层机制
在C/C++中,有着动态内存管理机制,给了用户足够高的自由度去自定义内存。比如C通过函数malloc/free,以及C++通过操作符new/delete来完成。
当用户向内存申请空间,但是用户很有可能还没有这么快就使用这块内存,那么如果操作系统直接把这一块内存分配给该进程,就会导致内存的浪费。
操作系统要为效率和资源利用率负责,因此当用户进行内存申请的时候,操作系统不会直接分配内存。操作系统会先给用户一个虚拟地址,比如malloc和new都会返回指针,这个指针就是虚拟地址。但是虽然有了虚拟地址,但是页表中没有该虚拟地址的映射关系。
直到用户尝试对这个内存进行访问,只要访问合法,就会去页表中查找该虚拟地址的物理地址。当发现该虚拟地址不存在页表中,此时就会向操作系统报错,这个过程叫做缺页中断。
一旦发生缺页中断,操作系统就会进行分析,发现是用户想要访问之前动态开辟的内存,于是操作系统此时才真正开辟内存,并且在页表中建立映射关系。
因此:动态内存管理的本质,是在虚拟地址中申请内存。
这么做有两个好处:
- 保证了内存的使用率,直到用户对内存写入,才真正开辟内存
- 提升了
malloc,new等动态内存管理的速度,因为没有真的申请内存

