一、完整代码
稍后补充
二、论文解读
2.1 当前存在的两种word2vec模型
word2vec的两个主要处理方法:
1) Matrix Factorization Methods,如潜在语义分析(LSA)
2) Shallow Window-Based Methods,如CBOW和Skip-gram
目前,这两个模型方法都存在明显的缺陷。虽然像LSA这样的方法很有效地利用了统计信息,但它们在单词类比任务上做得相对较差,这表明了一个次优的向量空间结构。像skip-gram这样的方法可能在类比任务上做得更好,但它们很少利用语料库的统计数据,因为它们训练的是单独的局部上下文窗口,而不是全局共现计数。
而GloVe能结合两种优点,通过只训练词共现矩阵中的非零元素,而不是训练整个稀疏矩阵或大型语料库中的单个上下文窗口,有效地利用了统计信息。产生了一个具有有意义的子结构的向量空间;
2.2 GloVe的原理
2.2.1 构建词共现矩阵
与LSA利用word和top构建词共现矩阵不同的是,GloVe利用的是word和word构建的词共现矩阵,实现原理很简单,利用Shallow Window-Based Methods 即n-gram构建词共现矩阵,接下来我们开始下一步的推导;
2.2.2 定义和推导
首先我们定义词共现矩阵为 X,其  表示为
表示为  中出现的次数;定义
中出现的次数;定义  即所有词包含
即所有词包含  出现的次数之和;最后定义
出现的次数之和;最后定义  ,表示
,表示  出现在包含
出现在包含  的上下文出现次数的可能性;
的上下文出现次数的可能性;

从图中我们可以看出,虽然k在ice和steam出现的概率不高,但是两者的概率的比值根据k值都有一定的变化,再根据k为solid或者gas的结果中我们可以看出,solid大于1对应分子,gas小于1对应分母;再从water和fashion两个与solid和gas几乎无相关的词的值在1附近可以看出,该比率能更好地区分相关单词和不相关单词;
在这里我们定义  和
和  这两个词的词向量为
这两个词的词向量为  ,随便定义一个映射函数,包含
,随便定义一个映射函数,包含  ,不需要在意是怎么映射的;
,不需要在意是怎么映射的;

然后由于向量空间本质上是线性结构,所以最自然的方法是利用向量差。即可以把  转化为
转化为  ,即
,即

再可以看到减数和被减数分别代表着分子和分母,然而分子和分母之间又有一个k与他们联系起来,这里我们可以再进行转化一下,把  ,即
,即  在这里就结束了吗?不!我们还给这个函数添加一个新的功能
在这里就结束了吗?不!我们还给这个函数添加一个新的功能

得到

由于需要满足这个新功能的函数只有指数函数则定义  ,则有
,则有
 从自由度的角度来解释由于公式
从自由度的角度来解释由于公式  其中
其中  的值是否固定不影响
的值是否固定不影响  的关系,我们可以把其看作一个常数,通过对称性,我们可以把其值表示为
的关系,我们可以把其看作一个常数,通过对称性,我们可以把其值表示为

同时要注意到词共现矩阵肯定会出现0元素,所以我们需要进行一下优化,有

到这一步其实还有一个缺陷:会出现一些无意义的词共现程度非常大,所以我们需要加强一下出现词少的权重,减弱一下出现词多的权重;定义函数如下

在这里我们需要定义两个参数  和
和  ;
;
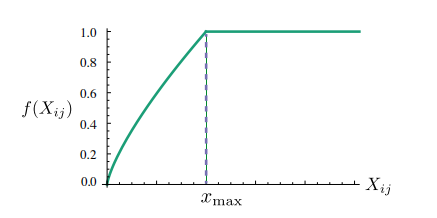
最后我们定义损失函数如下:

一般来说我们把  分别固定为100和0.75;
分别固定为100和0.75;
2.2.3 与其他模型的关系
其他模型一般是使用softmax进行分类,即要求
 (
(
达到最大;这样我们就可以定义其损失函数为

不懂可以考虑一下:  ,在这里又可以通过
,在这里又可以通过 
 转化为
转化为

其中  表示
表示  出现在包含
出现在包含  的上下文出现次数的可能性;
的上下文出现次数的可能性;  可以写为
可以写为  ,不同的模型主要差别显示在了这里,
,不同的模型主要差别显示在了这里,  都有
都有  出现在包含
出现在包含  的上下文出现次数的可能性的意思,则应该输出一个平方项,于此同时
的上下文出现次数的可能性的意思,则应该输出一个平方项,于此同时  j ) 是负数,可以把负号给去掉,则应该使其平方和尽可能的小,则可以表示为
j ) 是负数,可以把负号给去掉,则应该使其平方和尽可能的小,则可以表示为
 为了简化计算有
为了简化计算有  再根据优化,减弱出现次数多的权重,加强出现次数少的权重,最后我们可以得到
再根据优化,减弱出现次数多的权重,加强出现次数少的权重,最后我们可以得到

三、过程实现
稍后补充
四、整体总结
GloVe是一种新的全局对数双线性回归模型的无监督学习,在单词类比、单词相似度和命名实体识别任务上优于其他模型(2014年之前)。