问题一:云数据仓库ADB我用本地客户端不能链接adb,白名单设置过了,请问还有啥原因?
云数据仓库ADB我用本地客户端不能链接adb,白名单设置过了,请问还有啥原因?
参考答案:
ADB实例无法连接常见的原因有两个:
- 实例集群的域名地址和端口设置不正确
- IP白名单设置有问题
详细文档:https://help.aliyun.com/document_detail/470129.html
IP白名单功能限制客户端的访问,需要正确设置IP白名单才能正常连接ADB实例。
正确设置IP白名单,需要先获取正确的客户端出口IP,再在控制台上设置白名单。
详细文档:https://help.aliyun.com/zh/analyticdb-for-mysql/support/connections#section-zn0-ry7-7m3
关于本问题的更多回答可点击进行查看:
问题二:云数据库ADS使用Mybatis时报错unsupport packet
具体报错信息:
[9001, 2023112116070817201618010203453304732] unsupport packet=>050000001A01000000, packet_name=mysql_stmt_reset
报错截图:
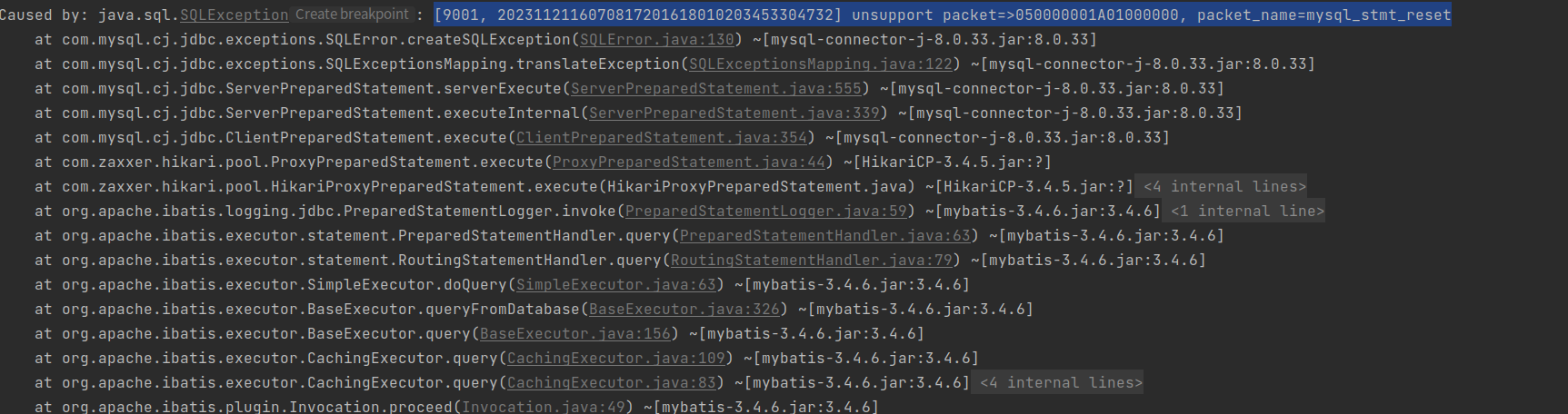
没有太好的解决方案,看起来是不支持mysql的这个函数吗?
参考答案:
出现 "[9001, 2023112116070817201618010203453304732] unsupport packet" 这类错误,通常是因为 MyBatis 不支持所使用的 SQL 语句类型,如 PreparedStatement 或 CallableStatement。
您可以按照以下步骤解决这个问题:
- 检查 SQL 语句类型:确保您正在使用的 SQL 语句类型是 MyBatis 支持的类型。
- 更改数据库驱动:您可以更换另一个支持所用 SQL 语句类型的数据库驱动,如 MySQL Connector/J。
- 修改 MyBatis 的设置:可以修改 MyBatis 的参数设置,使其支持所需的 SQL 语句类型。
关于本问题的更多回答可点击进行查看:
问题三:存在分区倾斜,是什么意思?
存在分区倾斜,是什么意思?
参考答案:
分区倾斜是指数据分布不均匀的情况。在数据库中,分区是指将表中的数据分成若干个区段,数据分布不均匀指的是每个区段中数据量大小相差过大,进而导致查询效率降低的情况。通常使用 Partition、Bucketing 等技术来缓解分区倾斜问题。
关于本问题的更多回答可点击进行查看:
问题四:出现分区倾斜,如何处理和解决?
出现分区倾斜,如何处理和解决?
参考答案:
分区倾斜是指在分布式计算系统中,某些分区的任务比其他分区的任务更大,使得系统在运行过程中产生不平衡的现象。为了解决分区倾斜问题,可以采取如下几种方法:
- 对数据进行再分发:将大的数据集分成较小的数据集,以保证每个分区的任务大小大致相同,减少数据倾斜的可能性。
- 调整哈希函数:如果哈希函数有偏差,可能会影响数据分布,调整哈希函数可以解决这个问题。
- 提高系统资源利用率:增加机器数量或者增加单个机器的资源,使系统更加平衡。
- 数据采样:如果某一组数据过大,可以将其随机抽样,将其分解成小数据集,减小数据倾斜的影响。
- 动态调度:系统可以根据实际任务的负载,动态调整分区之间的任务分配,以达到平衡。
关于本问题的更多回答可点击进行查看:
