大家好,我是 同学小张,持续学习C++进阶知识和AI大模型应用实战案例,持续分享,欢迎大家点赞+关注,共同学习和进步。
本文来学习一下MetaGPT的一个实战案例 - 狼人杀游戏,该案例源码已经在 MetaGPT GitHub开源代码 中可以看到。
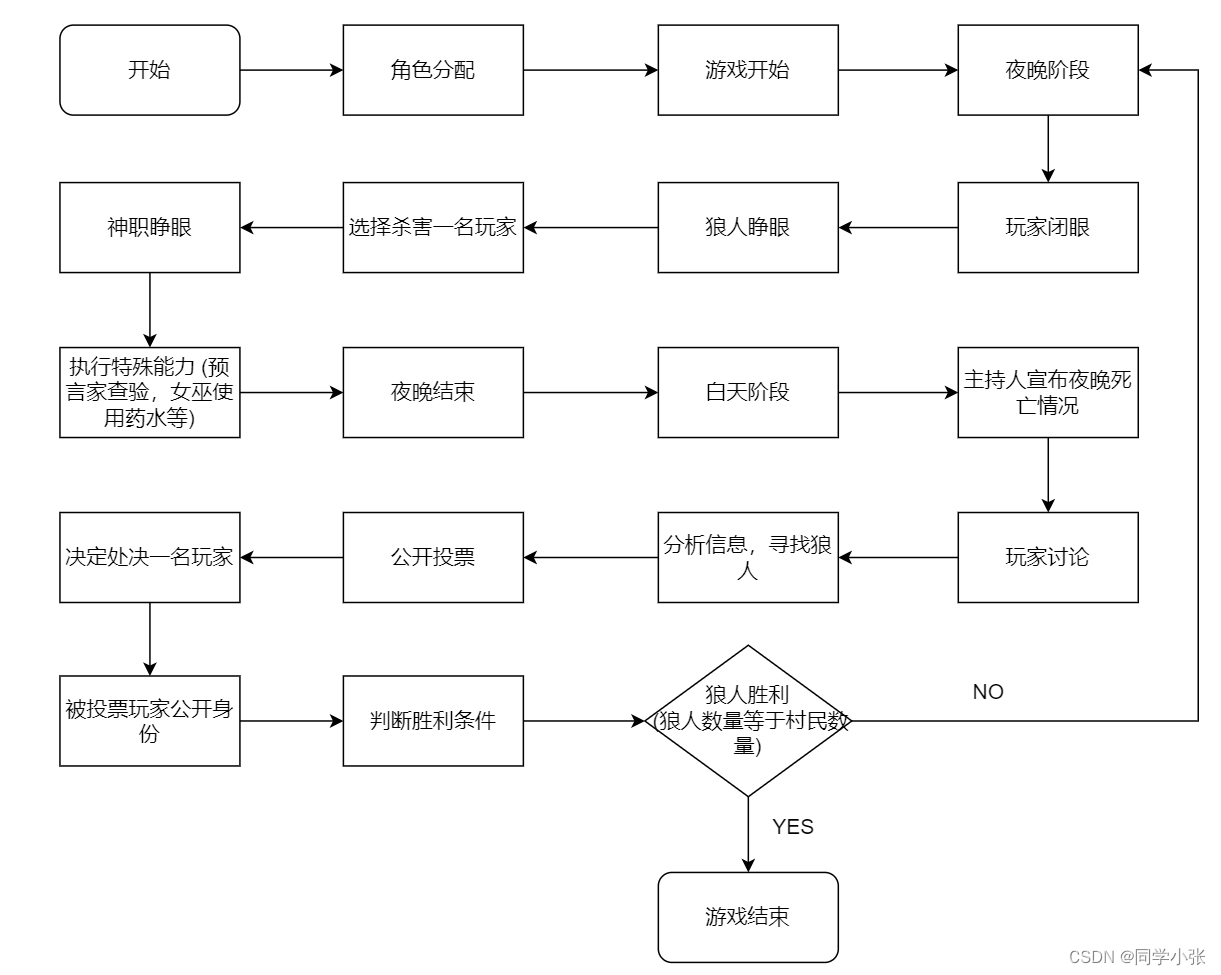
0. 狼人杀游戏规则
不了解的可以先看下下面狼人杀的游戏规则,以便更好地理解下文的内容。
狼人杀是一款多人参与的社交推理游戏,游戏中的角色分为狼人、村民和特殊角色三大类。
基本规则
- 角色分配:游戏开始前,每位玩家随机分配一个角色,包括狼人、普通村民和具有特殊能力的神职村民(如预言家、女巫、猎人等)。
- 游戏流程:游戏分为夜晚和白天两个阶段。夜晚,狼人睁眼并杀害一名玩家;白天,所有玩家讨论并投票处决一名玩家。这个过程会不断重复,直到满足某个胜利条件。
- 胜利条件:游戏的胜利条件分为狼人阵营胜利和村民阵营胜利。
- 狼人胜利:狼人数量等于村民数量时,狼人阵营获胜。
- 村民胜利:所有狼人被找出并处决,村民阵营获胜。
特殊角色介绍
- 预言家:每晚可以查验一名玩家的身份。
- 女巫:拥有一瓶解药,可以救人;拥有一瓶毒药,可以毒杀一名玩家。通常只能在第一晚使用解药。
- 猎人:被处决时可以开枪带走一名玩家。
- 守卫:每晚可以守护一名玩家,使其免受狼人杀害。
整体游戏流程可以用下面的流程图来表示:
1. 先跑起来看下效果
按我的步骤,第一步肯定是先将程序跑起来看看什么样。
直接在源代码里跑,运行 .\MetaGPT\examples\werewolf_game\start_game.py
1.1 运行起来的效果
(1)游戏开始,角色分配

(2)主持人走流程,黑夜,守卫说话
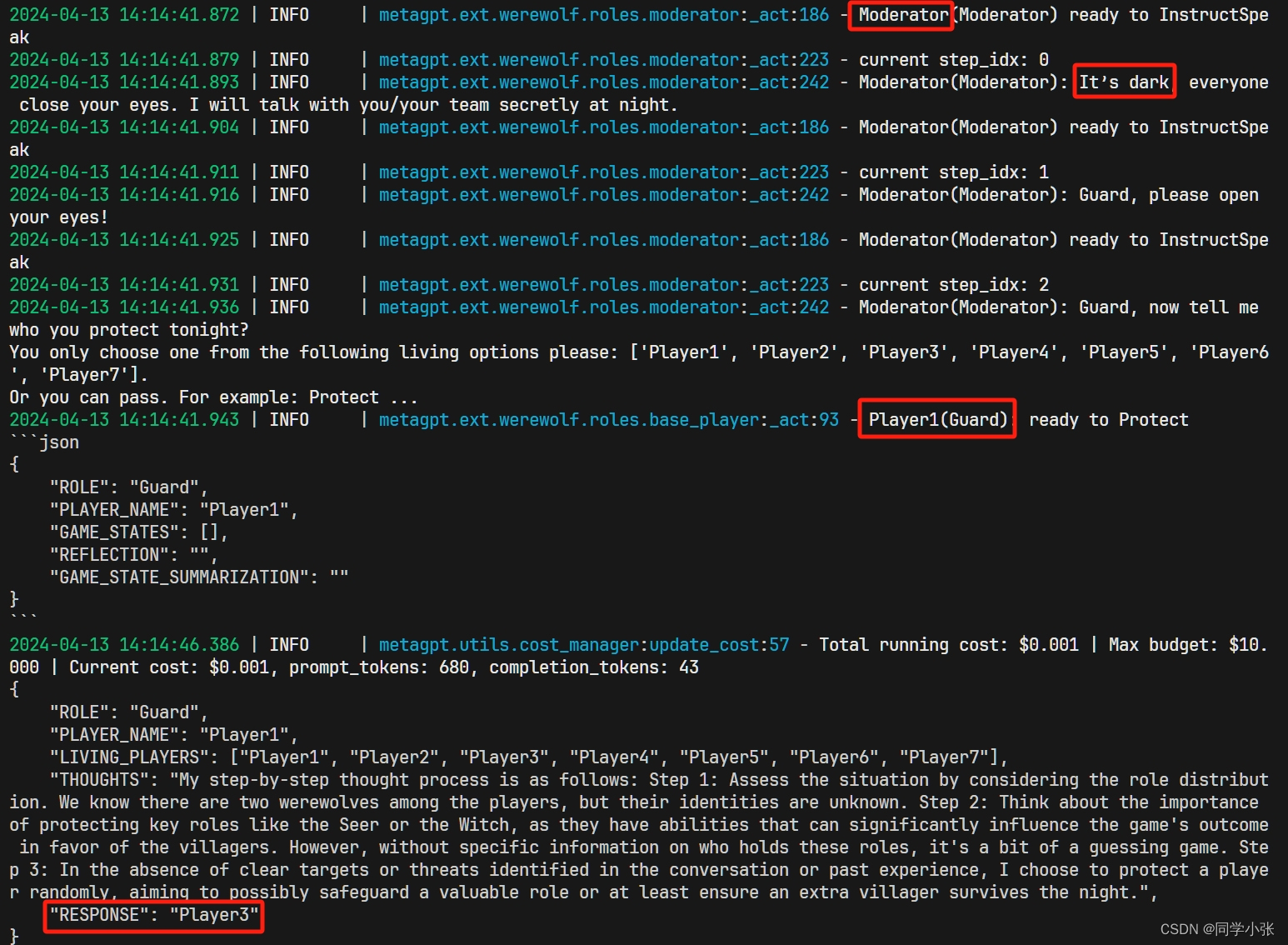
(3)狼人杀人
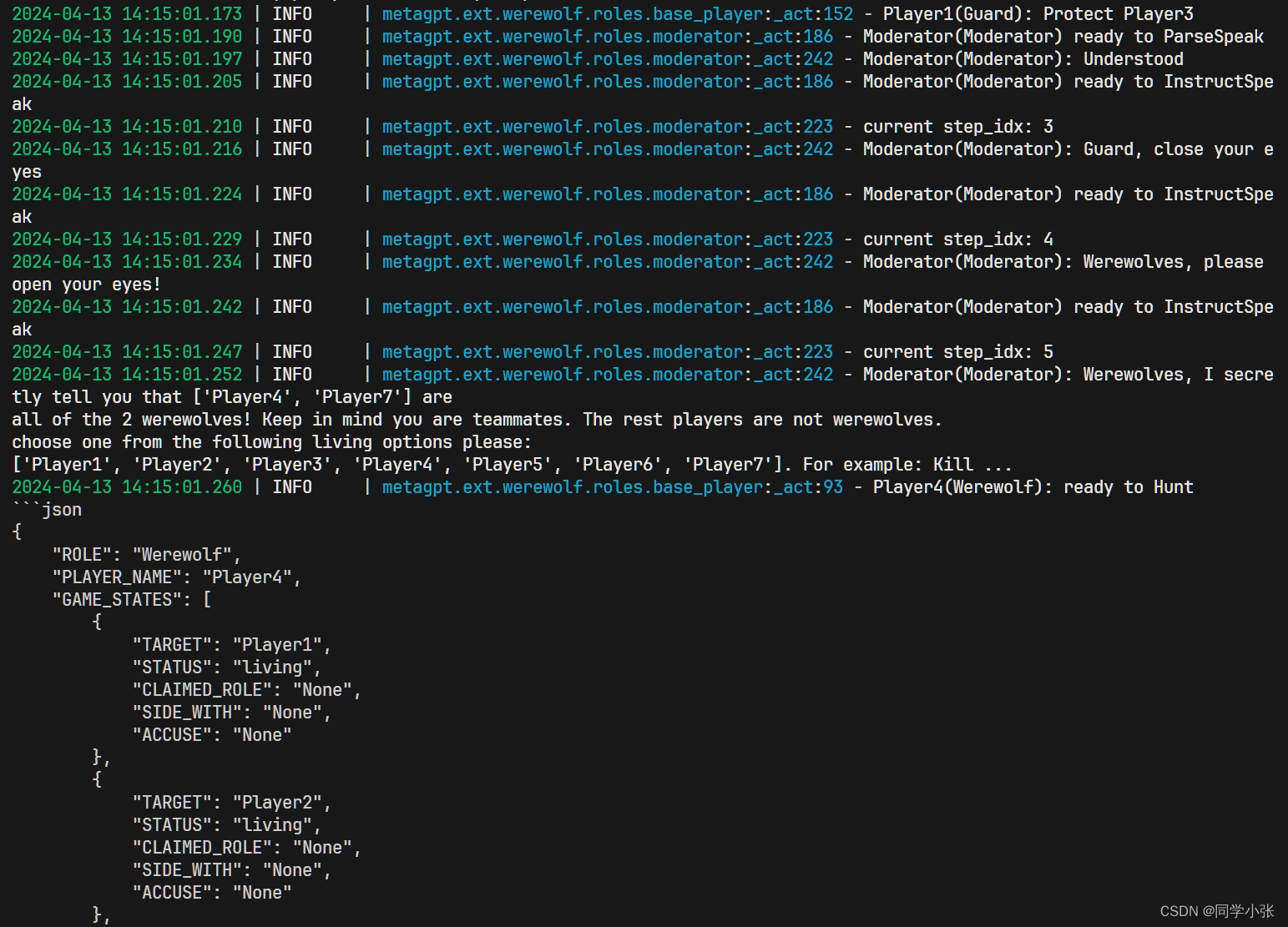

(4)类似这样的流程一直走,直到游戏结束。
特别提醒,在运行这个游戏前,请先将 main 函数中的 n_round 修改的小一点,否则你的钱包很容易不保!!!
def main( investment: float = 20.0, n_round: int = 16, // 修改这里! 修改这里 ! 修改这里 ! shuffle: bool = True, add_human: bool = False, use_reflection: bool = True, use_experience: bool = False, use_memory_selection: bool = False, new_experience_version: str = "", ):
1.2 运行过程中遇到的错
1.2.1 各种 No module named ‘llama_index.xxxxxx’
把各种缺的包安装以下,例如我缺以下包:
pip install llama-index-vector-stores-postgres -i https://pypi.tuna.tsinghua.edu.cn/simple pip install llama-index-vector-stores-chroma -i https://pypi.tuna.tsinghua.edu.cn/simple pip install llama-index-vector-stores-elasticsearch -i https://pypi.tuna.tsinghua.edu.cn/simple pip install llama-index-vector-stores-faiss -i https://pypi.tuna.tsinghua.edu.cn/simple pip install llama-index-retrievers-bm25 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install llama-index-embeddings-azure-openai -i https://pypi.tuna.tsinghua.edu.cn/simple pip install llama-index-embeddings-gemini -i https://pypi.tuna.tsinghua.edu.cn/simple pip install llama-index-embeddings-ollama -i https://pypi.tuna.tsinghua.edu.cn/simple
缺少的包如何安装,一是百度如何安装,二是可以从这里找 llama-index 相关的包怎么安装:https://llamahub.ai/?tab=retrievers
2. 案例拆解
这个案例相对来说比较复杂,代码较多,细节也很多,所以本文先从整体框架上进行拆解,更多代码和实现细节后面还会出专门的拆解文章。
对于以 MetaGPT 为框架的多智能体程序,程序中的核心一般就找里面的三个部分:Role、Action、Enviroment 。 找到这三个部分,大体框架应该就清晰了。
Role是智能体的角色,Action为该角色对应的动作,Environment来将各个Role的消息串起来,实现多智能体间的信息交互。
2.1 角色设定及对应的Action设定
2.1.0 需要的角色 与 角色的框架 - BasePlayer
2.1.0.1 需要的角色
首先来看角色设定。由狼人杀的游戏规则我们知道需要以下类型的角色:
- 主持人
- 守卫
- 村民
- 狼人
- 先知
- 巫师
于是,代码中首先规定了这几类角色:
class RoleType(Enum): VILLAGER = "Villager" # 村民 WEREWOLF = "Werewolf" # 狼人 GUARD = "Guard" # 守卫 SEER = "Seer" # 先知 WITCH = "Witch" # 巫师 MODERATOR = "Moderator" # 主持人
2.1.0.2 角色框架 - BasePlayer
代码中有一个BasePlayer类,该类封装了角色的基本行为和属性,所有的角色都继承自这个类,从这个类中派生。其基本属性和初始化如下:
class BasePlayer(Role): name: str = "PlayerXYZ" profile: str = "BasePlayer" special_action_names: list[str] = [] use_reflection: bool = True use_experience: bool = False use_memory_selection: bool = False new_experience_version: str = "" status: RoleState = RoleState.ALIVE special_actions: list[SerializeAsAny[Action]] = Field(default=[], validate_default=True) experiences: list[RoleExperience] = [] def __init__(self, **kwargs): super().__init__(**kwargs) # 技能和监听配置 self._watch([InstructSpeak]) # 监听Moderator的指令以做行动 special_actions = [ACTIONS[action_name] for action_name in self.special_action_names] capable_actions = [Speak] + special_actions self.set_actions(capable_actions) # 给角色赋予行动技能 self.special_actions = special_actions if not self.use_reflection and self.use_experience: logger.warning("You must enable use_reflection before using experience") self.use_experience = False
(1)首先角色都需要监听 InstructSpeak 动作产生的消息:self._watch([InstructSpeak])
(2)角色的行为设置:self.set_actions(capable_actions),包括设置进来的 special_actions 和 Speak Action。
(3)其它参数的含义后天再细看。这里你只需要知道每个角色的行为是怎么来的就可以了。
2.1.0.3 所有角色共同的Action - Speak
上面我们看到,BasePlayer中有个 Speak Action,所有派生自 BasePlayer的角色默认都拥有此行为。
其部分代码如下:核心就是各个角色根据自身信息组装Prompt,然后输入给大模型得到大模型的输出。

接下来,看看各个角色的设计。
2.1.1 主持人 - Moderator
.\MetaGPT\metagpt\ext\werewolf\roles\moderator.py
2.1.1.1 角色设定
主持人的角色设定如下:
class Moderator(BasePlayer): name: str = RoleType.MODERATOR.value profile: str = RoleType.MODERATOR.value def __init__(self, **kwargs): super().__init__(**kwargs) self._watch([UserRequirement, InstructSpeak, ParseSpeak]) self.set_actions([InstructSpeak, ParseSpeak, AnnounceGameResult])
- 其接收的Action:
UserRequirement用户输入、InstructSpeak、ParseSpeak - 其需要执行的Action:
InstructSpeak、ParseSpeak、AnnounceGameResult - 当然,它也继承了
BasePlayer,所以它也有SpeakAction需要执行
2.1.1.2 角色动作:InstructSpeak
代码如下:
class InstructSpeak(Action): name: str = "InstructSpeak" async def run(self, step_idx, living_players, werewolf_players, player_hunted, player_current_dead): instruction_info = STEP_INSTRUCTIONS.get( step_idx, {"content": "Unknown instruction.", "send_to": {}, "restricted_to": {}} ) content = instruction_info["content"] if "{living_players}" in content and "{werewolf_players}" in content: content = content.format( living_players=living_players, werewolf_players=werewolf_players, werewolf_num=len(werewolf_players) ) if "{living_players}" in content: content = content.format(living_players=living_players) if "{werewolf_players}" in content: content = content.format(werewolf_players=werewolf_players) if "{player_hunted}" in content: content = content.format(player_hunted=player_hunted) if "{player_current_dead}" in content: player_current_dead = "No one" if not player_current_dead else player_current_dead content = content.format(player_current_dead=player_current_dead) return content, instruction_info["send_to"], instruction_info["restricted_to"
该动作的目的是主持整个游戏的流程,传入的参数有一个 step_idx,这是游戏进行到哪一步了,根据这步骤,从预先设定好的流程中取出本步骤的信息。简单看下预设的流程步骤(太多,就不全部展示了,大体看下部分就知道这是个什么东西了):
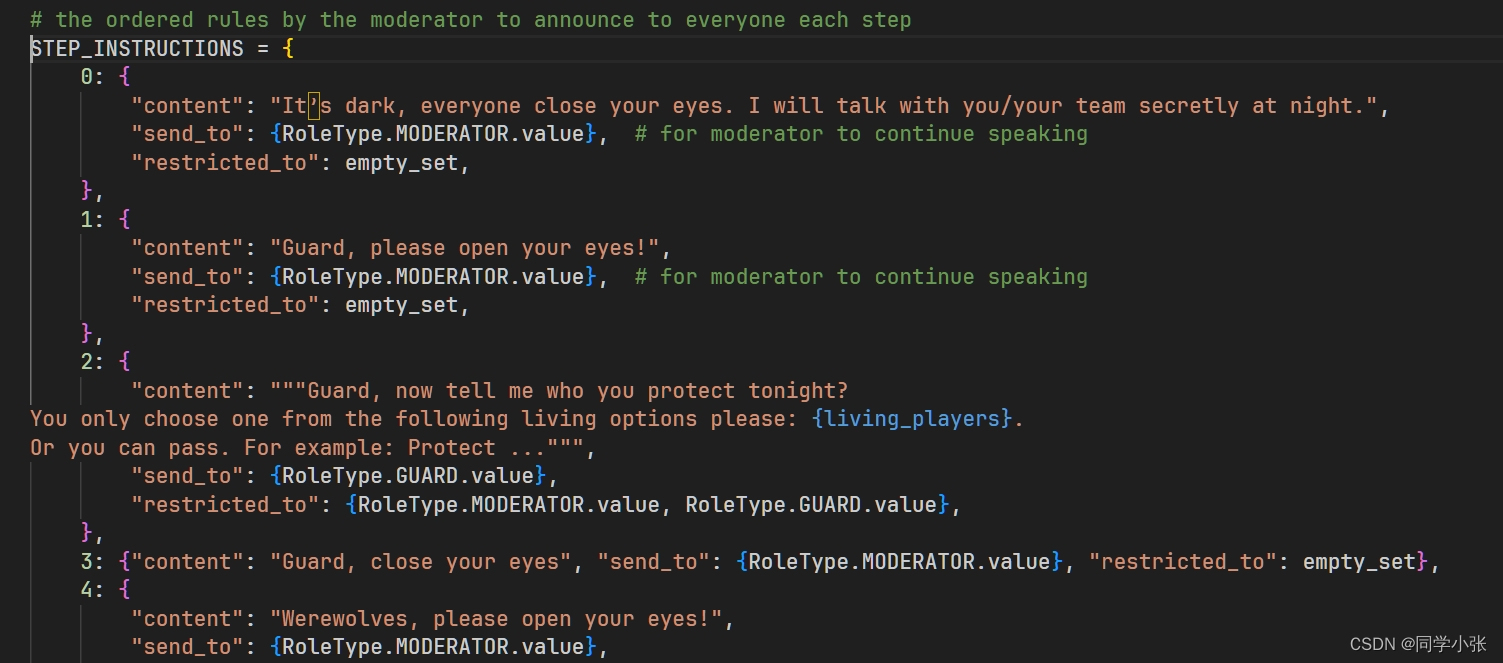
这些步骤就是按照文章开头的流程来预先设定一些Prompt和该消息该发给谁,下一个该谁发言等。
2.1.1.3 角色动作:ParseSpeak
该动作用来解析角色发言的信息。
2.1.1.4 角色动作:AnnounceGameResult
宣布游戏结束,游戏结果和游戏结束的原因。
class AnnounceGameResult(Action): async def run(self, winner: str, win_reason: str): return f"Game over! {win_reason}. The winner is the {winner}"
2.1.1.5 观察的动作:UserRequirement
用来开始游戏。
2.1.1.6 观察的动作:InstructSpeak
接收 InstructSpeak 的消息,如果 InstructSpeak 的消息需要主持人处理,则处理该消息。
例如第0轮到第1轮,主持人说完“天黑请闭眼”之后,下面还需要继续说话“请守卫睁开眼”。这时候第0轮InstructSpeak的消息就是发给主持人的。所以代码中这样写了:
"send_to": {RoleType.MODERATOR.value}, # for moderator to continue speaking
2.1.1.7 观察的动作:ParseSpeak
解析完角色发言后,主持人继续发言,主持流程。
2.1.1.8 总结
所以,主持人 Moderator 的主要职责是:开始游戏、主持流程、解析角色发言和宣布游戏结果。
2.1.2 村民 - Villager
class Villager(BasePlayer): name: str = RoleType.VILLAGER.value profile: str = RoleType.VILLAGER.value special_action_names: list[str] = []
村民继承自 BasePlayer,所以其拥有 Speak 行为,除此之外,无特殊能力,所以其也就只能 Speak。
2.1.3 狼人 - Werewolf
2.1.3.1 角色设定
class Werewolf(BasePlayer): name: str = RoleType.WEREWOLF.value profile: str = RoleType.WEREWOLF.value special_action_names: list[str] = ["Hunt"] async def _think(self): """狼人白天发言时需要伪装,与其他角色不同,因此需要重写_think""" await super()._think() if isinstance(self.rc.todo, Speak): self.rc.todo = Impersonate()
(1)狼人除了能 Speak (继承自 BasePlayer)外,拥有特殊技能 Hunt。
(2)狼人在白天时,要伪装成好人说话,所以,还有个额外的Action:Impersonate
狼人就两个动作:一个是夜晚干人,二是白天伪装成好人发言。
2.1.3.2 角色动作:Hunt
该动作是狼人在夜晚决定干掉谁。
class Hunt(NighttimeWhispers): name: str = "Hunt"
2.1.3.3 角色动作:Impersonate
继承自 Speak,主要用来伪装成好人来发言。
class Impersonate(Speak): """Action: werewolf impersonating a good guy in daytime speak""" STRATEGY: str = """ Try continuously impersonating a role, such as Seer, Guard, Villager, etc., in order to mislead other players, make them trust you, and thus hiding your werewolf identity. However, pay attention to what your werewolf partner said, DONT claim the same role as your werewolf partner. Remmber NOT to reveal your real identity as a werewolf! """ name: str = "Impersonate" ? 10
2.1.4 守卫 - Guard
2.1.4.1 角色设定
class Guard(BasePlayer): name: str = RoleType.GUARD.value profile: str = RoleType.GUARD.value special_action_names: list[str] = ["Protect"]
守卫的特殊技能:Protect,保护人。
2.1.4.2 角色动作:Protect
class Protect(NighttimeWhispers): name: str = "Protect"
2.1.5 先知 - Seer
2.1.5.1 角色设定
class Seer(BasePlayer): name: str = RoleType.SEER.value profile: str = RoleType.SEER.value special_action_names: list[str] = ["Verify"]
先知的特殊技能:Verify,验证其它角色的身份。
2.1.5.2 角色动作:Verify
class Verify(NighttimeWhispers): name: str = "Verify"
2.1.6 女巫 - Witch
2.1.6.1 角色设定
class Witch(BasePlayer): name: str = RoleType.WITCH.value profile: str = RoleType.WITCH.value special_action_names: list[str] = ["Save", "Poison"]
女巫有两个特殊技能:Save 和 Poison,救人和毒人。
2.1.6.2 角色动作:Save
class Save(NighttimeWhispers): name: str = "Save"
2.1.6.3 角色动作:Poison
class Poison(NighttimeWhispers): STRATEGY: str = """ Only poison a player if you are confident he/she is a werewolf. Don't poison a player randomly or at first night. If someone claims to be the witch, poison him/her, because you are the only witch, he/she can only be a werewolf. """ name: str = "Poison"
2.1.7 夜晚共同的Action - NighttimeWhispers
根据上面的Action代码你可能也发现了,大部分的Action都继承自一个 NighttimeWhispers 。这个 Action 的设定是在夜晚的时候进行悄悄地思考和发言。
2.2 环境 - WerewolfGame、WerewolfEnv
环境就是用来在各角色之间进行消息传递的。另外还有 round_cnt 来控制最大交互轮数。WerewolfExtEnv 也有更新游戏和各角色状态的作用。先大体看下环境的封装:
class WerewolfGame(Team): """Use the "software company paradigm" to hold a werewolf game""" env: Optional[WerewolfEnv] = None def __init__(self, context: Context = None, **data: Any): super(Team, self).__init__(**data) ctx = context or Context() if not self.env: self.env = WerewolfEnv(context=ctx) else: self.env.context = ctx # The `env` object is allocated by deserialization
class WerewolfEnv(WerewolfExtEnv, Environment): round_cnt: int = Field(default=0) class WerewolfExtEnv(ExtEnv): model_config = ConfigDict(arbitrary_types_allowed=True) players_state: dict[str, tuple[str, RoleState]] = Field( default_factory=dict, description="the player's role type and state by player_name" ) round_idx: int = Field(default=0) # the current round step_idx: int = Field(default=0) # the current step of current round eval_step_idx: list[int] = Field(default=[]) per_round_steps: int = Field(default=len(STEP_INSTRUCTIONS)) # game global states game_setup: str = Field(default="", description="game setup including role and its num") special_role_players: list[str] = Field(default=[]) winner: Optional[str] = Field(default=None) win_reason: Optional[str] = Field(default=None) witch_poison_left: int = Field(default=1, description="should be 1 or 0") witch_antidote_left: int = Field(default=1, description="should be 1 or 0") # game current round states, a round is from closing your eyes to the next time you close your eyes round_hunts: dict[str, str] = Field(default_factory=dict, description="nighttime wolf hunt result") round_votes: dict[str, str] = Field( default_factory=dict, description="daytime all players vote result, key=voter, value=voted one" ) player_hunted: Optional[str] = Field(default=None) player_protected: Optional[str] = Field(default=None) is_hunted_player_saved: bool = Field(default=False) player_poisoned: Optional[str] = Field(default=None) player_current_dead: list[str] = Field(default=[])
3. 总结
本文就先拆解到这,总结一下。
我们看了狼人杀的基本规则,从规则中知道了该游戏的基本流程和需要的角色,以及各角色应该有的的技能设定。
知道了基本流程,那 MetaGPT 组织智能体的最基本流程就有了(SOP),不过这里的SOP表现形式与之前见过的不同。之前的SOP我认为是隐式的,也就是说潜藏在各角色中,根据角色的 set_actions 和 watch 将整个SOP串联起来。而在该游戏中,除了这种隐式的SOP之外,还有一个显示的SOP流程,就是主持人角色在串流程,代码中 STEP_INSTRUCTIONS 也明确给出了完整的流程。这也是一种SOP思路,可以借鉴:当流程太多太复杂的时候,不防将SOP这样写出来,根据步骤序号去获取下一步该干什么。
有了SOP,MetaGPT的框架就是三要素:角色、动作和环境。角色和角色的动作我们通过游戏规则就知道了。环境主要是给角色之间提供交流的渠道,按照这个方向实现环境的封装就可以。
总之,本文我们学习的是该案例的整体框架,有了框架,剩下的就是里面各动作和交互的细节了,这部分是最难落地的。后面我们分开继续进行详细的拆解。
如果觉得本文对你有帮助,麻烦点个赞和关注呗 ~~~
- 大家好,我是 同学小张,持续学习C++进阶知识和AI大模型应用实战案例
- 欢迎 点赞 + 关注 ?,持续学习,持续干货输出。
- +v: jasper_8017 一起交流?,一起进步?。
- 微信公众号也可搜【同学小张】 ?
本站文章一览: