【Redis技术进阶之路】「底层源码解析」揭秘高效存储模型与数据结构底层实现(字典)(一)/article/1471152
dictEntry模型
Redis的dictEntry 结构体不仅包含了指向键和值的指针,还巧妙地设计了一个指向下一个哈希项的指针next。这个指针 next 的存在,使得当多个键的哈希值发生冲突时,Redis 能够将这些键以链表的形式连接在一起,从而有效地解决了哈希冲突问题。
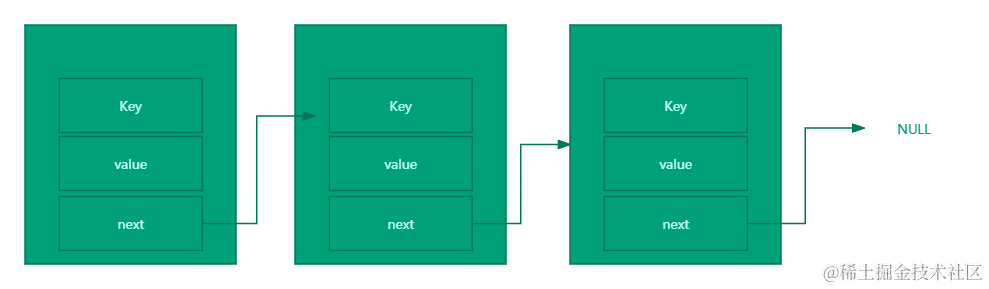
- key:用于存储键值对中键的部分
- value:承载着键值对中对应的值。既可以是一个指向其他数据结构的指针,也可以是一个uint64_t类型的无符号64位整数,或是一个int64_t类型的有符号64位整数。
- next:扮演着链接哈希表节点的角色,它是一个指向另一个哈希表节点的指针。当多个键值对的哈希值相同时,即发生了所谓的键冲突,这些具有相同哈希值的键值对会通过next指针串联起来,形成一个链表结构。
通过设计哈希函数和链表的维护策略,哈希表能够在平均情况下实现近乎O(1)的查找、插入和删除操作。
dictEntry的结构体源码
dictEntry结构体表示字典中的一个键值对,源码如下所示:
c
复制代码
struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; /* Next entry in the same hash bucket. */ struct dictEntry *next; }; typedef struct { void *key; dictEntry *next; } dictEntryNoValue;
dictEntry **ht_table[2]
dictEntry **ht_table[2]:一个包含两个项的数组,其中每个项都代表一个dict哈希表结构。

在正常情况下,我们主要使用ht[0]这个哈希表进行数据存储和检索操作。而ht[1]哈希表的存在,主要是为了在需要对ht[0]进行rehash操作时提供一个临时的存储空间。
两个哈希表支持rehashing
在 Redis 中,当哈希表的大小需要调整时(例如,因为哈希表已满或空闲空间太多),它不会一次性重新分配整个哈希表,而是会同时使用两个哈希表:一个旧的和一个新的,类似于COW模式进行处理,Copy And Write机制。
随着键值对的插入和删除,旧的哈希表中的数据会逐渐迁移到新的哈希表中,直到旧的哈希表为空,然后旧的哈希表会被释放,新的哈希表成为主哈希表。接下来我们要开始分析和研究hash的机制和原理、最后到了对应的rehashing能力。
哈希算法
我们先来看一下哈希算法,当需要将一个新的键值对添加至字典时,程序会首先根据该键值对的键进行哈希计算,得出相应的哈希值。随后,利用这个哈希值,进一步计算出在哈希表数组中的具体索引位置。
计算哈希值和索引值
使用字典设置的哈希函数,计算键key的哈希值,使用哈希表的mask值和size值,计算出素引值,根据情况不同,ht[x]可以是ht[0]或者ht[1]。
c
复制代码
#define DICTHT_SIZE(exp) ((exp) == -1 ? 0 : (unsigned long)1<<(exp)) #define DICTHT_SIZE_MASK(exp) ((exp) == -1 ? 0 : (DICTHT_SIZE(exp))-1)
上面定义的C语言的两个宏通常一起使用。
c
复制代码
#define dictHashKey(d, key) ((d)->type->hashFunction(key)) #define dictBuckets(d) (DICTHT_SIZE((d)->ht_size_exp[0])+DICTHT_SIZE((d)->ht_size_exp[1])) #define dictSize(d) ((d)->ht_used[0]+(d)->ht_used[1])
当想要计算一个键值对的哈希值对应的哈希表索引时,会先使用哈希函数计算出一个原始的哈希值,然后使用 DICTHT_SIZE_MASK(exp) 宏将这个哈希值限制在哈希表大小的范围内。这样,就可以确保计算出的索引不会超出哈希表的边界。最终,将包含新键值对的哈希表节点精准地放置在哈希表数组指定索引的位置上。
案例分析
举个例子,对于下图所示的字典来说,如果我们要将一个键值对w添加到字典里面:

那么程序会先使用语句:#define dictHashKey(d, key) ((d)->type->hashFunction(key)),计算键w的哈希值。假设计算得出的哈希值为100,那么程序会继续使用语句:#define dictBuckets(d) (DICTHT_SIZE((d)->ht_size_exp[0])+DICTHT_SIZE((d)->ht_size_exp[1])),计算出键w的索引值6,这表示包含键值对w的节点应该被放置到哈希表数组的索引6位置上。
解决键冲突
当多个键被哈希函数映射到哈希表数组的同一索引位置时,这种现象被称为键冲突。
链地址法
在Redis的哈希表实现中,采用了链地址法来有效处理这种冲突。每个哈希表节点都包含一个next指针,使得多个哈希表节点能够通过next指针串联成一个单向链表。因此,当多个键被分配到相同的索引位置时,这些节点可以通过这个单向链表相互连接,从而巧妙地解决了键冲突问题。

以图示为例,假设我们拥有一个哈希表,并且程序需要将键值对w插入其中。经过哈希函数的计算,我们得知w的索引值为4。然而,在这个特定的索引位置,已存在其他键(如c和d),这就引发了键冲突问题。
Rehash操作和处理执行
为了确保哈希表的负载因子维持在一个适宜的水平,程序会根据哈希表当前的键值对数量来灵活调整其大小,这种动态调整的策略有助于确保哈希表始终保持在高效运行的状态。
扩展和收缩
扩展和收缩哈希表的工作可通过执行rehash(重新散列)操作得以实现。在此过程中,字典巧妙地利用ht[0]和ht[1]这两个哈希表来共同存储键值对,确保了操作的顺畅进行。当满足以下任一条件时,程序将自动触发哈希表的扩展操作:
- 【键值对数量过多】导致负载因子偏高时,程序会执行扩展操作,增大哈希表容量,以提高查询效率并避免过多的冲突。
- 【键值对数量过少】负载因子偏低,程序则会进行收缩操作,减小哈希表的大小,以节省内存资源。
负载因子
负载因子 = 即键值对数量/哈希表大小。
c
复制代码
load_factor = ht[0/1].used / ht[0/1].size
案例分析
- 哈希表的大小为6,包含6个键值对的哈希表来说,这个哈希表的负载因子为:
6/6 =1,结果为1。 - 哈希表的大小为100,包含200个键值对的哈希表来说,这个哈希表的负载因子为:
200 / 100=2。 - 哈希表的大小为100,包含50个键值对的哈希表来说,这个哈希表的负载因子为:
50 / 100=0.5。
RDB和AOF与Rehash的关系
Redis在执行BGSAVE或BGREWRITEAOF命令时,会根据子进程的存在与否调整哈希表扩展操作的负载因子阈值。这主要是为了避免在子进程运行时进行不必要的哈希表扩展,进而减少内存写入,提高内存利用效率。
- 未执行BGSAVE或BGREWRITEAOF命令,并且哈希表的负载因子达到或超过1时,程序会自动启动哈希表的扩展操作。
- 正在执行BGSAVE或BGREWRITEAOF命令,且哈希表的负载因子不低于5,程序将自动触发哈希表的扩展流程。
哈希表执行rehash的步骤
- 分配h1的哈希表空间:当哈希表需要扩容时,为ht[1]分配新的存储空间,其大小是经过精确计算的,确保至少是当前ht[0]中键值对数量(即ht[0].used的值)的两倍,并且是一个2的n次方幂。
- Rehash重新散列,这一过程涉及到将ht[0]中所有的键值对,按照新的哈希算法计算出的哈希值和索引值,精确无误地迁移至ht[1]中。
- 数据键值转移:所有键值对成功从ht[0]转移至ht[1]
- 释放原有哈希表空间:立即释放ht[0]占用的内存空间,以优化内存使用。
最后,将ht[1]提升为新的ht[0],并初始化一个新的空白哈希表作为新的ht[1],以备将来可能再次触发的重新散列操作。

执行rehash的时候业务操作
在进行rehash操作时,字典的删除、查找和更新等操作都需要在这两个哈希表上进行,注意没有新增哦!具体来说,当我们需要在字典中查找一个键时,程序会首先在ht[0]中进行搜索。如果未能在ht[0]中找到相应的键,程序则会继续转向ht[1]进行查找,以确保不会遗漏任何可能的键值对。

注意,在rehash操作进行的过程中,所有新添加的键值对都会被统一存储于ht[1]哈希表中,而ht[0]则不再承担新键值对的添加任务。
最后总结
字典是Redis实现多样化功能的核心组件,尤其在数据库和哈希键的构造中发挥着至关重要的作用。Redis精心设计了其字典结构,以哈希表作为基石,确保高效且稳健的数据存取。
- 双哈希表:每个Redis字典都巧妙地配备了两个哈希表,一个负责日常运作,而另一个则专门用于rehash操作,这种双表机制显著提升了字典在数据变动时的性能表现。
- 解决冲突:在哈希表中,为了解决这一冲突,Redis巧妙地运用了
next指针机制。它将新键值对w对应的节点通过next指针链接到已存在的d节点之前,从而构建了一个链表结构。通过这种方式,Redis不仅有效地解决了键冲突问题,还保证了哈希表在数据插入时的灵活性和高效性。 - Rehash控制:当哈希表需要进行扩展或收缩以适应数据量的变化时,Redis并非一蹴而就地完成整个rehash过程。相反,它采取了渐进式的策略,逐步将旧哈希表中的键值对迁移到新表中,从而确保了rehash操作对系统性能的影响最小化。