前言
数据结构是计算机存储、组织数据的方式。在工作中,我们通常会直接使用已经封装好的集合API,这样可以更高效地完成任务。但是作为一名程序员,掌握数据结构是非常重要的,因为它可以帮助我们更好地理解和设计算法,从而提高程序的效率和可靠性。本文将对常见的几种数据结构进行介绍,通过了解这些数据结构的特点和优势,可以更好地在不同场景下选择合适的数据结构。
数据结构介绍
常见的数据结构大体分为两种类型:线性和非线性。
线性数据结构见名思义,整体结构的图像是一条直线。包括数组、链表、栈、队列等。非线性数据结构包括,树、堆、图等。
数组
数组是由多个元素组成的一个集合,表现形式如下图

数组
在内存中存储数组的空间是连续的,每个元素占据一定的内存空间,这也是为什么在声明数组时要指定长度,不然不知道要占用多少空间。以 Java 语言为例,当声明一个数组后,数组变量会指向数组对象的起始地址,也就是第一个元素的位置,如下图

数组在内存的表现
以此看来,当查询数组中的某个元素时,通过下标就可以计算出这个元素的内存地址,比如想查找下标为2的元素,那么arr[2]的内存地址 = arr的内存地址 + 2 * 元素大小,也就可以直接通过内存地址访问元素,时间复杂度为O(1)。
但是,数组也会带来一个问题:由于数组长度是固定的,所以在添加或删除元素时会涉及到创建新的数组来替换原数组,导致复杂度较高。例如,下面的代码演示了如何在数组末尾添加一个元素:
int[] arr = {1, 2, 3, 4, 5}; arr[arr.length] = 6; // 将要添加的元素放到数组的最后一个位置 int[] newArr = new int[arr.length + 1]; // 创建一个新的数组,长度加1 for (int i = 0; i < newArr.length; i++) { newArr[i] = arr[i]; // 将原数组中的元素复制到新数组中 } arr = newArr; // 使用新数组替换原数组
示例代码在内存中的活动如下图

数组在内存的表现
在 Java 中有很多集合的底层实现都是基于数组,例如大家常用的 ArrayList、Vector、HashMap、ArrayBlockingQueue等等。
链表
链表由一系列节点组成,每个节点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个节点地址的指针域。以 Java 为例,一个节点的结构是这样表示的:
public class Node<T> { //存储数据元素的数据域 private T value; //下一个节点地址的指针域 private Node next; }
每个元素的指针指向下一个元素,从而形成链表,表现形式如下图。

链表
与数组不同,链表在内存中是非连续的空间,可以充分利用计算机内存空间,实现灵活的内存动态管理,解决了数组需要预先知道数据大小的缺点。其在内存中的存储如下图

链表在内存中的表现
相比于数组,链表的插入和删除操作可以达到O(1)的复杂度(只需要将链尾的指针指向下个节点或者指向null即可),但是查找一个节点或者访问特定编号的节点则需要O(n)的时间。
上面介绍的是单向链表,单向链表有个缺点:只能只能从头到尾遍历。如果要删除倒数第二个节点,只能从头遍历。为了更加灵活的操作和更高的效率,就有了双向链表,其结构表示如下图

双向链表结构
如果结构为双向链表,要删除倒数第二个节点,只用找到尾节点的前面一个节点并删除即可。Java 中的 LinkedList 就是一个双向链表的实现。
队列和栈
数组和链表的关注点主要聚焦于数据的存储结构和访问方式,而队列和栈关注的则是数据的处理顺序和逻辑,有自己的特点。
队列的特点是先进先出(FIFO):第一个进入队列的元素会第一个被访问或取出,或者说在添加元素时在队尾排队依次入队,在队头依次出队。其表现形式如下图

队列操作元素
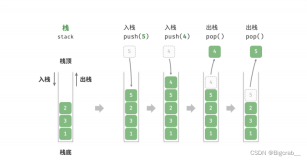
栈的特点是先进后出(FILO):第一个入栈的元素最后一个被访问或被取出,或者说最后一个入栈的元素会第一个被访问或被取出。栈只允许在栈顶进行插入和删除操作。
有一个很形象的描述就是:可以将栈想象成一个弹夹,最先装入的子弹会被压入底部,而射出时则是从顶部弹出。

栈操作元素
两者的底层实现可以根据具体需求和场景选择数组或链表作为底层数据结构。例如 Java 中的 ArrayBlockingQueue 是通过数组实现的阻塞队列,LinkedBlockingQueue 通过队列实现的非阻塞队列。
树
树是一种非线性结构,是由n个有限节点组成一个具有层次关系的集合。树也有很多类型,比如二叉树、平衡树、2-3-4树、红黑树、B树、B+树。
二叉树是每个节点最多有两个子树的树结构,通常用于实现二叉查找树,其特点为:左子节点的值小于根节点的值,右子节点的值大于根节点的值。以 Java 为例,一个二叉查找树的结构是这样表示的:
public class Node { //当前节点的值 private int value; //父节点、左子节点、右子节点 private Node parent,left,right; }
表现形式如下图

二叉树
其查询的时间复杂度为O(log n),相对于链表,查询效率大大提升。但是在最坏情况下可能会退化成O(n),比如下面这种情况

二叉树退化为链表
为了避免这种情况,诞生了AVL树。AVL树是一种自平衡的二叉查找树,在进行插入和删除操作时,会通过左旋或者右旋自动调整自身的结构,确保每个节点的左右子树的高度差不超过1,从而保持树的平衡,也保障了查询的时间复杂度为O(log n)。
以下图为例,当插入节点5时,节点7左右子树的高度差为2,这时候节点7就需要进行右旋保持树的平衡。

右旋就是:以某个节点为旋转点,其左子节点变为其父节点,左子节点的右子节点变为其左子节点,右子节点不变。同理,左旋就是:以某个节点为旋转点,其右子节点变为其父节点,右子节点的左子节点变为其右子节点,左子节点不变。
虽然AVL通过旋转保持树的平衡,但是在插入和删除频繁的场景中,频繁的旋转会导致性能下降,为解决此问题红黑树被提出。
红黑树大家应该都比较耳熟,面试的时候应该经常会被问到,但是理不理解是另一回事。
红黑树也是自平衡的二叉查找树,它是通过节点颜色来保证树的平衡的。相对AVL,红黑树较难被理解,第一疑惑就是:“不也是左旋右旋吗?还这么麻烦,节点颜色变来变去,迷惑谁呢?”。
红黑树后面专门写一篇文章介绍,这里先给结论:红黑树的旋转次数相对于AVL树来说较少,因此在插入、删除等操作较多的情况下,通常使用红黑树,比如大家都知道的HashMap。下图显示的是按顺序插入9, 7, 6, 10, 5, 8, 4, 2, 1, 0的AVL树和红黑树,可以看到两者在结构上存在一定的差异。

红黑树
上面说的几种树都是二叉树,即每个节点只有两个分支,并且都都是有序的。因为只有两个分支,所以这也是二叉树的通病,当数据越来越多的时候,树的高度也会越高,这种情况就不适合数据库和文件系统这种场景了。
上面提到的几种树结构都是二叉树,每个节点只有两个子节点,并且都是有序的。当数据量不断增加时,二叉树的高度也会逐渐增加,从而导致查询效率降低,并且在有磁盘I/O操作的场景下,树越高越不利于查询。
为了解决上述问题,采用多叉树结构,可以有效地降低树的高度,提高查询效率。
常见的多叉树有2-3-4树、B树和B+树,通常在数据库和文件系统中会使用到,其表现形式如下图。

B+树
B+树是B树的一种扩展,它更适合用于磁盘或其他存储设备中。在B+树中,非叶子节点不保存数据信息,只保存关键字和子节点指针,这样会存储更多有效数据,比如索引。同时,每个叶子节点都指向相邻叶子节点的指针,这样的话在数据库范围查询会变得非常高效。
堆
堆是一种特殊的树形数据结构,其特点为:每个节点都大于或等于(小于或等于)其每个子节点。
常见的堆有二叉堆、斐波那契堆等,二叉堆是一种完全二叉树,可以分为最大堆和最小堆,最大堆中的每个节点都大于或等于其子节点,最小堆中的每个节点都小于或等于其子节点。下图左为最大堆的表示,右不符合为一个完全二叉树(依次从左到右插入的节点为完全二叉树)。

堆
堆通常被用作优先队列,因为堆的根节点总是最大的或最小的。
总结
很多编程语言都提供了不同类型的集合类,以 Java 为例,我们常用的集合有List、Set、Queue、Map,其底层的实现就是数组、链表或树这几种数据结构。所以通过了解数据结构,我们可以更好地选择和使用这些集合,甚至可以自行设计更高效的数据结构来解决问题。