2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
本次实验中,我们将使用API调用GitHub上星级最高的Python项目信息,并使用Plotly生成交互式的可视化图表。这些数据是实时更新的,因此可以提高数据的可用性和准确性。
通过这种方式,我们可以更加深入地了解Python编程社区,探索最受欢迎的Python项目,并了解开发者们正在关注和使用的技术。这有助于我们更好地理解Python编程生态系统,并为未来的研究和开发提供有价值的参考。
import requests#导入request模块
# 调用API并储存返回的响应
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
headers = {
'Accept': 'application/vnd.github.v3+json'}#因为版本往往不一样,我们指定使用这个我们指定的API
r = requests.get(url, headers=headers)#用函数调用API
print(f"Status code: {r.status_code}")
#将响应赋给response_dict
response_dict= r.json()
#API返回的Json信息储存在response_dict
print (response_dict.keys())
#打印出来看看
https://api.github.com/search/repositories
关于这个地址,开头的https://api.github.com/是把请求发送到GitHub网站,接下里search是搜索,对象是所有的仓库repositories,q表示查询,=表示开始指定查询language:python是值要获取语言为python的信息,最后&sort=stars指定将项目按星排序
打印出来后是这样子的:状态码为200,响应字典只有三个键:['total_count', 'incomplete_results', 'items']
Status code: 200
dict_keys(['total_count', 'incomplete_results', 'items'])
import requests
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
headers = {
'Accept': 'application/vnd.github.v3+json'}
r = requests.get(url, headers=headers)
print(f"Status code: {r.status_code}")
response_dict= r.json()
print(f"Total repositories: {response_dict['total_count']}")
# 探索全部仓库的信息
repo_dicts = response_dict['items']#打印与total_count相关的值,它指出了GitHub共有多少个仓库
print(f"Repositories returned: {len(repo_dicts)}")#将字典储存在repo_dicts
#我们可以来看下第一个仓库
repo_dict=repo_dicts[0]
print(f"\nKeys:{len(repo_dict)}")
for key in sorted(repo_dict.keys()):
print(key)
#我们来提取一些repo_dict中于一些键相关联的值
这段代码使用了requests库来发送GET请求获取GitHub上星级最高的Python项目信息。通过指定URL和请求头部信息,我们可以向GitHub的API发送请求并获取响应。
首先,定义了API的URL地址为https://api.github.com/search/repositories?q=language:python&sort=stars,并设置了Accept请求头部为application/vnd.github.v3+json,以便获取适合的响应格式。
使用requests.get()方法发送GET请求,并将返回的响应对象赋值给变量r。
通过r.status_code可以打印出响应状态码,用于检查请求是否成功。
接下来使用r.json()方法将响应转换为JSON格式,并将其存储在response_dict字典中。
通过访问response_dict['total_count']可以获取到GitHub上Python仓库的总数量,并将其打印出来。
然后通过response_dict['items']获取到所有仓库的详细信息,并将其存储在repo_dicts列表中。
通过访问repo_dicts[0]可以获取第一个仓库的详细信息,并将其存储在repo_dict字典中。
最后,使用循环遍历repo_dict字典的键,并将其按照字母顺序排序后打印出来,以便查看仓库信息的键值对。
通过这段代码,我们可以获取到GitHub上星级最高的Python项目的信息,并进一步探索这些项目的详细信息。
这个是打印出来的值,我们可以从这里了解到实际出来的数据
Status code: 200
Total repositories: 6622696
Repositories returned: 30
Keys:74
archive_url
archived
assignees_url
太多了,跳过一部分
watchers
watchers_count
现在我们来提取一些repo_dict中于一些键相关联的值
import requests
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
headers = {
'Accept': 'application/vnd.github.v3+json'}
r = requests.get(url, headers=headers)
print(f"Status code: {r.status_code}")
response_dict= r.json()
print(f"Total repositories: {response_dict['total_count']}")
repo_dicts = response_dict['items']
print(f"Repositories returned: {len(repo_dicts)}")
repo_dict=repo_dicts[0]
#我们来提取一些repo_dict中于一些键相关联的值
print("\nSelected information about each repository:")
print(f"Name: {repo_dict['name']}")#人名
print(f"Owner: {repo_dict['owner']['login']}")
print(f"Stars: {repo_dict['stargazers_count']}")#获得了多少个星
print(f"Repository: {repo_dict['html_url']}")
print(f"Created: {repo_dict['created_at']}")#项目创建的时间
print(f"Updated: {repo_dict['updated_at']}")#最后一次更新的时间
print(f"Description: {repo_dict['description']}")
这段代码对获取的每个仓库的信息进行了进一步提取和打印。
首先,从repo_dicts中选择第一个仓库,并将其详细信息存储在repo_dict字典中。
然后,通过访问repo_dict字典的特定键,如name、owner、stargazers_count、html_url、created_at、updated_at和description,分别提取并打印了仓库的名称、所有者、星标数量、仓库链接、创建时间、最后更新时间和描述信息。
这样我们就可以逐个提取每个仓库的相关信息,并进行打印输出,以便进一步了解GitHub上星级最高的Python项目的详细情况。
结果就就是下面这样子:
Status code: 200
Total repositories: 6618376
Repositories returned: 30
Selected information about each repository:
Name: system-design-primer
Owner: donnemartin
Stars: 119890
Repository: https://github.com/donnemartin/system-design-primer
Created: 2017-02-26T16:15:28Z
Updated: 2021-01-31T02:19:49Z
Description: Learn how to design large-scale systems. Prep for the system design interview. Includes Anki flashcards.
Process finished with exit code 0
理清了数据后,那么我们就可以总体开始了
import requests
from plotly.graph_objs import Bar#导入bar类
from plotly import offline#导入offline模块
# Make an API call and store the response.
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
headers = {
'Accept': 'application/vnd.github.v3+json'}
r = requests.get(url, headers=headers)
print(f"Status code: {r.status_code}")
# 处理结果.
response_dict = r.json()
repo_dicts = response_dict['items']
repo_links, stars, labels = [], [], []#创建三个空列表用来存储我们要用的数据
for repo_dict in repo_dicts:#遍历repo_dicts中的所有的字典,打印项目的名称、所有者、星级等信息。
repo_name = repo_dict['name']
repo_url = repo_dict['html_url']
repo_link = f"<a href='{repo_url}'>{repo_name}</a>"
repo_links.append(repo_link)
stars.append(repo_dict['stargazers_count'])
owner = repo_dict['owner']['login']
description = repo_dict['description']
label = f"{owner}<br />{description}"
labels.append(label)
#开始可视化,定义列表data
data = [{
'type': 'bar',
'x': repo_links,
'y': stars,
'hovertext': labels,
'marker': {
'color': 'rgb(60, 100, 150)',
'line': {
'width': 1.5, 'color': 'rgb(25, 25, 25)'}
},
'opacity': 0.6,
}]
#使用字典定义表格的布局
my_layout = {
'title': 'Most-Starred Python Projects on GitHub',
'titlefont': {
'size': 28},
'xaxis': {
'title': 'Repository',
'titlefont': {
'size': 24},
'tickfont': {
'size': 14},
},
'yaxis': {
'title': 'Stars',
'titlefont': {
'size': 24},
'tickfont': {
'size': 14},
},
}
fig = {
'data': data, 'layout': my_layout}
offline.plot(fig, filename='python_repos.html')
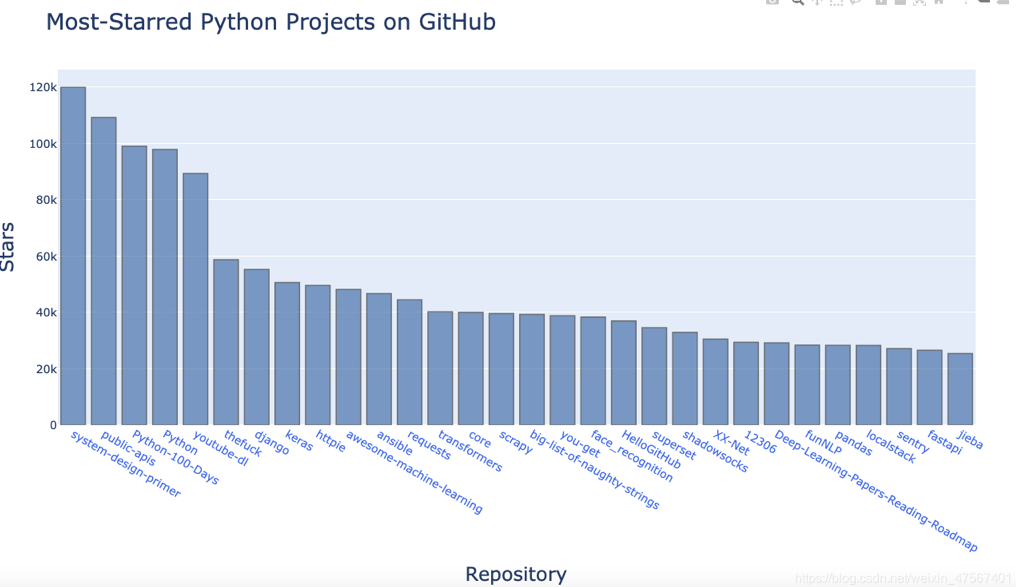
这段代码使用了Plotly库来创建一个条形图,展示GitHub上最受欢迎的Python项目的星级情况。
首先,通过发送API请求获取GitHub上的Python项目信息,并将结果存储在response_dict中。
然后,从每个项目的字典中提取项目名称、项目链接、星级数量、所有者和描述信息,并分别存储在repo_links、stars和labels列表中。
接下来,定义了一个字典data,其中包含了条形图的相关信息,如x轴数据为项目链接,y轴数据为星级数量,hovertext为项目所有者和描述信息。同时,设置了条形图的颜色、透明度和线宽等属性。
然后,定义了一个布局字典my_layout,其中包含了条形图的标题、x轴和y轴的标题和字体大小等设置。
最后,将数据和布局传递给fig字典,并使用offline.plot()函数将图表保存为HTML文件。
运行代码后,将生成一个名为python_repos.html的文件,可以在浏览器中打开该文件,查看GitHub上最受欢迎的Python项目的星级情况条形图。
最后我们可以生成一个可视化的html文件在浏览器打开