一、NoSQL数据库概述
NoSQL泛指非关系型数据库,相对于传统关系型数据库,NoSQL有着更复杂的分类,包括KV数据库,文档数据库,列式数据库以及图数据库等等,这些类型的数据库能够更好的适应复杂类型的海量数据存储
一个NoSQL数据库提供了一种存储和检索数据的方法,该方法不同于传统的关系型数据库那种表格形式 目前NoSQL在大数据领域的应用非常广泛,应用于实时Web应用
促进NoSQL发展的因素如下
1:简单设计原则,可以更简单的水平扩展到多机器集群
2:更细粒度的控制有效性
一种NoSQL数据库的有效性取决于该类型NoSQL所能解决的问题,大多是NoSQL数据库系统都降低了系统的一致性,以利于有效性,分区容忍性和操作速度,当前制约NoSQL发展的很大部分原因是因为NoSQL的低级别查询语言、缺乏标准接口以及当前在关系型数据的投入
二、KV数据库
KV 数据库是最常见的 NoSQL 数据库形式
优势是处理速度非常快,缺点是只能通过键的完全一致查询来获取数据
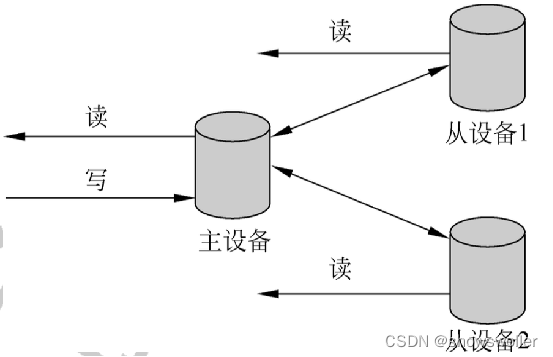
Redis 是著名的内存K V数据库,在工业界得到了广泛的使用
Redis采用异步的主从复制方式
右图是Redis 的副本维护策略
三、列式数据库
列式数据库基于列式存储的文件存储格局,兼具NoSQL和传统数据库的一些优点,具有很强的水平扩展能力,极强的容错性以及极高的数据承载能力,同时也有接近于传统关系型数据库的数据模型,在数据表达能力上强于简单的KV数据库 下面以BigTable和HBase为例介绍列式数据库的功能和应用
BigTable 的数据模型本质上是一个 三维映射表,其最基础的存储单元由行主键、列主键、时间构成的三维主键唯一确定
HBase 是一个开源的非关系型分布式数据库 ,它参考了Google 的BigTable模型
HBase以表的形式存放数据。表由行和列组成,每个列属于某个列簇,由行和列确 定的存储单元称为元素
四、图数据库
在图的领域并没有一套被广泛接受的术语,存在着很多不同类型的图模型,但是有人致力于创建一种属性图形模型以期望统一大多数不同的图实现,按照该模型,属性图里信息的建模使用下面三种构造单元
属性图形模型(PropertyGraph Model)
节点(即顶点)
关系(即边),具有方向和类型(标记和标向)
节点和关系上面的属性(即特性)
右图是一个被标记的小型属性图

五、文档数据库
文档数据库中的文档是一个数据记录,这个记录能够对包含的数据类型和内容进行“自我描述 ”,如XML文档 、HTML 文档和JSON 文档
文档数据库中的模型采用的是模型视图控制器(MVC)中的模型层,每个JSON 文档 的ID 就是它唯一的键
创作不易 觉得有帮助请点赞关注收藏~~~
