引言
在过去的一年中,大型语言模型(LLMs)以及像ChatGPT这样的产品已经吸引了全球的注意,并驱动了建立在它们之上的新功能浪潮。矢量和矢量搜索的概念是为了实现如推荐、问题回答、图像/视频搜索等功能的核心。
因此,我们在社区中看到了对矢量搜索兴趣的显著增加。具体来说,人们对何时需要专门的矢量数据库,何时不需要有比较感兴趣。
以这些模型为重点,我们借此机会重新审视矢量出现前的搜索,探讨矢量(和嵌入)是什么,了解矢量搜索,其应用,以及这个功能如何适应更广泛的数据景观。
对于那些已经熟悉基本的矢量搜索概念并想直接跳到ClickHouse中如何进行矢量搜索的读者,您可以跳到第二部分(下周在公众号发布)。
矢量出现之前的搜索
让我们简要介绍一下如何使用Elasticsearch和Solr这样的传统引擎进行搜索(注意:这些技术现在也提供了矢量搜索功能)。
这些引擎主要提供文本搜索功能,依赖于用户将内容划分为称为文档的离散文本单元,每个文档都有一个ID。这些文档可以包含从一本书或网页的所有文本到一个单独的句子的任何内容,具体取决于用户需要找到相关内容的粒度(长度也会影响搜索效果)。
然后,每个文档的文本都会通过一个称为分词的过程分割成其组成的词,产生一个词袋。在其最简单的形式中,分词将涉及按空白符分割、转为小写和删除标点的过程。这些也称为terms的词将用于建立一个类似于书籍背面的索引。这个索引将包含文本中的每个词的计数,它们出现的文档ID,称为postings,以及每个术语在文档中出现的次数。
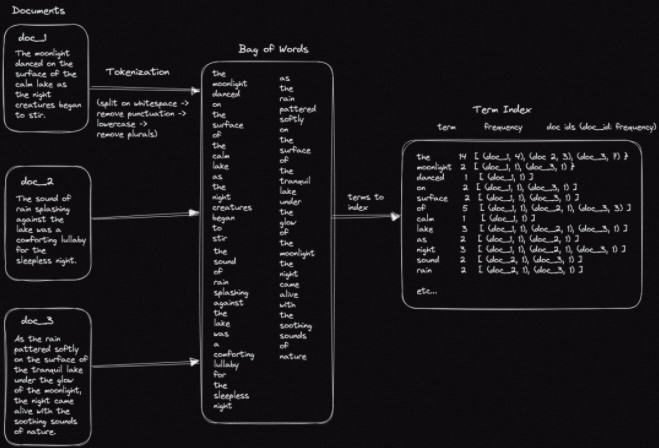
在搜索时,会访问索引,并确定匹配的文档。然后,会为每个文档执行一个计算,将搜索文本与文档术语进行比较,以便按相关性对其进行排序。这种“相关性计算”通常基于匹配术语在整个语料库和文档本身中出现的频率。
在整个语料库中很少见,但在匹配文档中很常见的词汇,会比如“和”这样的普通词汇对文档得分的贡献更大,这样的词汇几乎没有意义。这些频繁出现的词,被称为“停用词”(stop words),可以选择从索引中省略,因为它们对相关性的贡献很低,尽管损失了一些特性。这个简单的观察,在1970年代提出,形成了词频/逆文档频率(TF/IDF)公式的基础,尽管简单,但通常很有效。

这种方法的挑战在于它无法捕获单词本身的含义或上下文。如果搜索词汇接近,位置信息可以更高地权衡文档,但这仍然无法捕获它们之间的语义关系。例如,这种方法不能区分以下两者:
"猫通过窗户对鸟感兴趣地看着"和"鸟通过窗户对猫感兴趣地看着"。
此外,这种方法受到词汇不匹配问题的困扰。更具体地说,如果语料库的词汇与查询文本的词汇不同,用户会发现相关性很差。
虽然手动标记概念、同义词和使用分类法可以部分解决这些挑战,但这些方法不够灵活,难以维护,且很少能够扩展。重要的是,这种方法只适用于文本内容,不能(容易地)应用于其他数据媒介,如图像。
什么是矢量和嵌入?
在我们解释矢量如何解决捕捉单词之间语义关系的问题以及允许搜索更丰富的数据类型之前,让我们从基本原理开始,提醒自己什么是矢量。
在数学和物理学中,矢量被正式定义为一个具有大小和方向的对象。这通常采用空间中的线段或箭头的形式,可用于表示速度、力和加速度等数量。在计算机科学中,矢量是一个有限的数字序列。换句话说,它是一种用于存储数值的数据结构。
在机器学习中,矢量与我们在计算机科学中讨论的是相同的数据结构,但存储在其中的数值有特殊的意义。当我们取一个文本块或图像,并将其提取为它代表的关键概念时,这个过程被称为编码。结果输出是机器以数值形式表示的这些关键概念。这是一个嵌入,并存储在一个矢量中。换句话说,当这种上下文意义嵌入到一个矢量中时,我们可以称其为嵌入。
虽然所有的嵌入都是矢量,但并不是所有的矢量都是嵌入 - 矢量可以被认为是超类,可以用来表示任何数据,而嵌入是一种特定类型的矢量表示,是用来优化捕捉对象的语义或上下文语境。
这些嵌入矢量通常相当大,可以长达数百甚至数千个值。这个长度,也被称为维数,取决于如何产生矢量和他们打算代表的信息。对于大多数数据库,包括ClickHouse,一个矢量简单地是一个浮点数数组,即Array(Float32)。


在这里,我们将一个词表示为一个嵌入,但同样地,一个嵌入可以代表一个短语、句子或甚至一个文本段落。通常,对于特定维度的概念很难进行推理或附加标签,尤其是在更高的维度中,但当组合时允许词被概念性地理解。更重要的是,矢量也可以用来表示其他数据类型,如图像和音频。这为搜索历史上对于基于倒排索引方法的格式提供了可能性。
为什么矢量和嵌入有用?
将图像或文本编码为这些通用的表示,允许它们之间以及它们代表的信息进行比较,即使内容的原始形式是不同的。
要理解如何比较矢量嵌入,我们可以将嵌入想象为高维空间中的一个点。两个嵌入将是这个空间中的两个点。如果这两个嵌入代表的对象在概念上彼此相似,那么这些点在空间中的距离和角度将在几何上接近。
对于二维或三维,我们可以轻松地可视化和理解这个距离。下面,我们假设三个词“moonlight”、“flashlight”和“animal”的概念可以在3个维度中有效地表示:

不幸的是,三个维度不足以编码大量文本中的所有概念,更不用说图像了!幸运的是,用于计算两个矢量之间的角度或距离的数学(通常是余弦相似性或欧几里得距离)可以扩展到N维,即使我们作为人类不能在视觉上理解它。嵌入通常有一个维度小于1000 - 足以编码文本语料库中的大多数概念。当然,这假设我们可以很好地选择我们的概念并准确地将我们的嵌入编码到空间中。
估计高达80%到90%的所有数据都是非结构化的。因此,这种比较能力为神经网络和LLMs等算法提供了基础,这些算法用于处理历史上对于企业来说挑战性很大且成本很高的类,并从中提取洞察力和作出决策。
执行矢量搜索
目前,假设我们有一种使用算法产生这些嵌入的方法,并且已经为我们想要搜索的所有文本完成了这些嵌入。这样做为我们留下了一套嵌入,长度上可能达到数亿甚至数十亿。
当用户想要搜索这个文本仓库(对于我们现在有相应的嵌入)时,用户的搜索需要被转换成一个嵌入本身。然后,可以将用户的搜索嵌入与文本仓库的嵌入集合进行比较,以找到最接近的匹配。最接近的匹配嵌入,当然,代表了与用户搜索最接近的文本。
在最简单的形式中,用户可能只是简单地搜索最相关的文档或一组文档,通过距离排序,从而复制传统的搜索引擎。然而,这种能力在向查询找到概念上相似的上下文文档方面具有价值,包括ChatGPT。记住,嵌入是通过它们在矢量空间中的角度或距离进行比较的。

执行这种矢量比较过程通常需要一个可以持久化这些矢量,并且揭示查询语法的数据存储,其中可以传递一个矢量或潜在的原始查询输入(通常是文本)。这产生了像Pinecone和Weviate这样的矢量数据库的开发,它们不仅简单地存储矢量,还提供了将矢量生成过程集成到其数据加载管道和查询语法的方法——因此在数据加载和查询时自动执行嵌入编码过程。与此同时,像Solr和Elasticsearch这样的现有搜索引擎已经增加了对矢量搜索的支持,加入了新功能,允许用户加载和搜索嵌入。
此外,具有完整SQL支持的传统数据库,如Postgres和ClickHouse,已经增加了对矢量存储和检索的原生支持。在Postgres的情况下,这是通过pg_vector实现的。ClickHouse支持将矢量作为数组列类型(Array)进行存储,提供函数来计算搜索矢量和列值之间的距离。
精确结果与估计
当使用支持矢量搜索的数据存储时,用户有两种高级方法:
- 精确结果与线性搜索 - 输入矢量与数据库中的每个矢量的完全比较,按最近的距离排序结果并限制为K次命中。这种方法,通常称为K最近邻(K nearest neigbor),虽然提供了一个精确的结果,保证了最佳质量的匹配,但通常在没有显著并行匹配和/或使用GPU的情况下很难超过1亿。根据其定义,匹配时间与需要匹配的矢量数量成正比(假设所有其他变量是常数),即O(n)。

- 近似结果与近似最近邻 - 虽然有时需要确切的最近匹配,但近似通常就足够了,特别是在有许多高质量匹配的较大数据集上。近似最佳匹配的算法旨在通过为速度牺牲一些准确性来加快搜索过程,通过减少召回来降低准确性。ANN算法使用各种技术快速识别一小部分最有可能是查询矢量的最佳匹配的最近邻居。这可以显著减少搜索大型数据集所需的时间。虽然ANN算法不能总是返回确切的K个最近邻,但它们对于许多应用程序来说通常是足够准确的。ANN算法在数据集大且搜索需要快速进行的应用中非常有益。这里的例子包括分层可导航小世界(HNSW)和Annoy算法。

Annoy算法来源:Alexey Milovidov
上图显示了Annoy算法。这是通过在语料库上建立一个基于树的索引来工作的。这个树结构是通过根据使用的距离度量(通常是欧几里得距离)递归地将数据划分为较小的子空间来构建的。划分过程继续进行,直到子空间包含少量数据点或达到树的某个深度。当发出一个查询时,从根节点开始遍历树。在树的每一层,选择与查询点最近的节点,并评估其子节点。搜索继续进行,直到达到一个叶节点,该节点包含与查询点最近的数据点的子集。然后可以通过计算查询点与叶节点中的数据点之间的距离来找到最近的邻居。
生成嵌入向量
对于如何编码文本或更丰富的媒体内容(如图像)的详细过程,我们将在后续的博客文章中进一步讨论。简而言之,这依赖于利用机器学习算法来识别内容和意义,为语言或特定领域产生称为模型的数学表示。这些模型随后可用于将后续的文本(或其他资料)转化为向量。基于Transformer的模型是一种结构,已被证明在生成基于文本的内容的向量时特别有效。这一类的早期版本包括由Google开发的受欢迎的BERT模型。Transformers本身不仅仅是将文本转化为向量,它们还为最先进的语言翻译和最近受欢迎的聊天机器人ChatGPT提供了基础。
如前所述,向量不仅仅是概念性的嵌入。用户还可以选择为向量构造或添加其他特征。这些可以通过其他模型学习,或者由领域专家仔细选择,他们试图确保两个向量之间的近距离可以捕获业务问题的意义。请参阅下面的应用程序,了解一些示例。
最近几年,为图像生成嵌入的研究也引起了人们的极大关注,其中卷积神经网络架构在生成嵌入时在质量方面占据了主导地位。最近,视觉变换器(ViT)在图像分类和特征提取任务中表现出了令人鼓舞的结果,尤其是对于大规模的数据集。
多模型可以处理并编码多种数据类型,例如图像、文本和音频。例如,它们可以为图像和文本生成一个向量,有效地产生一个联合的嵌入空间,其中它们都可以进行比较。这可以用来允许用户使用单词进行搜索,并找到在概念上匹配的图像!OpenAI在2021年推出了一种名为CLIP(对比语言-图像预训练)的算法。这个特定的算法,我们将在未来的文章中使用它的嵌入,学习图像及其关联的文本字幕(在培训期间提供)的联合表示,以便相关图像和字幕的嵌入在空间中靠近。除了简单的搜索用例,这还允许进行诸如图像字幕和零镜头图像分类的任务。
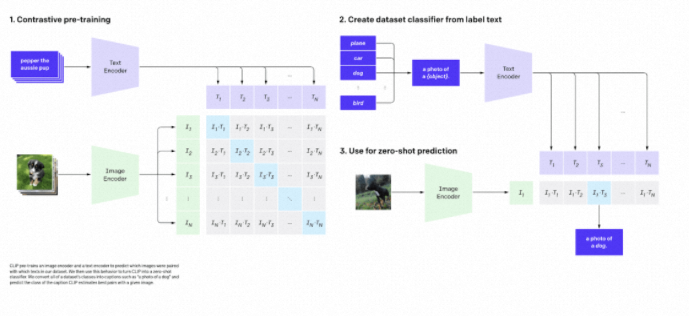
clip.png来源:CLIP - https://openai.com/research/clip
幸运的是,训练模型生成嵌入并不总是必要的,因为现在有开源的预训练模型可以用来生成这样的嵌入,可以从Hugging Face等资源下载。这些可以通过最少的额外培训进行“迁移学习”或“微调”来适应新领域。用户还可以下载数据集的生成嵌入进行实验。一旦用户生成或下载了一组嵌入,通常就需要一个存储媒体——这导致了向量数据库的采纳。
向量搜索的示例应用
这篇博客文章主要介绍了通过生成向量嵌入、其存储和检索来提供语义搜索的概念。这种能力在简单地增强现有的传统企业或应用搜索体验之外,还有许多应用。可能的用途包括,但不限于:
- 推荐 - 特别适用于电子商务网站,向量搜索可以用来找到相关产品。除了简单地将文本意义嵌入到向量中,页面浏览和过去的购买记录等特征也可以编码到向量中。
- 问答 - 问答系统历来都是一个挑战,因为用户很少使用与问题相同的术语。然而,可以将等效的含义编码为接近的向量,例如,X和Y。
- 图像和视频搜索 - 使用上述描述的多模态模型,用户可以基于文本搜索图像和视频 - 这对于音乐和电影推荐系统、产品推荐和新闻文章推荐等应用程序非常有用。
- 防欺诈 - 我们可以通过将用户的行为或登录模式编码成向量来找到相似或不相似的交易。这些可以是异常的行为,从而防止欺诈。
- 基因组分析 - 向量数据库可用于存储和检索基因组序列的嵌入,这对于基因表达分析、个性化医疗和药物发现等应用非常有用。
- 多语言搜索 - 而不是为语言建立索引(通常是一个昂贵的练习,并且与语言的数量成线性增长的成本),多语言模型可以允许使用两种语言编码为同一向量的同一概念进行跨语言搜索。
- 提供上下文 - 最近,向量数据库被用于为由APIs(如ChatGPT)驱动的聊天应用程序提供上下文内容。例如,内容可以转化为向量并存储在一个向量数据库中。当最终用户提出一个问题时,查询数据库,并识别相关的文档。它们可以用来为ChatGPT提供更多的上下文,以产生一个更为稳健的答案。我们的朋友Supabase最近实施了这样的架构,为他们的文档提供了一个聊天机器人。
结论
在这篇文章中,我们为向量嵌入和向量数据库提供了一个高层次的介绍。我们介绍了它们的价值以及它们如何与更传统的搜索方法相关,以及如何在大规模上匹配向量的一般方法 - 无论是精确的,还是通过近似。
云数据库 ClickHouse 版是阿里云提供的全托管 ClickHouse服务,是国内唯一和 ClickHouse 原厂达成战略合作并一方提供企业版内核服务的云产品。 企业版较社区版 ClickHouse 增强支持实时update&delete,云原生存算分离及Serverless 能力,整体成本可降低50%以上,现已开启邀测,欢迎申请体验(链接:https://www.aliyun.com/product/apsaradb/clickhouse)
产品介绍(https://www.aliyun.com/product/apsaradb/clickhouse)
技术交流群:

ClickHouse官方公众号: