HDFS常用shell命令
一、实验目标
- 掌握hadoop操作指令及HDFS命令行接口
- 掌握HDFS原理
二、实验要求
- 给出每个实验操作步骤成功的效果截图,。
- 对本次实验工作进行全面的总结。
- 完成实验内容后,实验报告文件重命名为:学号姓名实验二。
三、实验内容
1.列出某个目录下的文件
2.递归列出某目录及文件
3.创建目录,目录名自拟,查看创建的目录及文件
4.创建级联目录,递归查看
5.在本地新建一个文件,文件名和文件内容自拟,然后分别使用-put命令和-copyFromLocal 命令将该文件上传到HDFS
6.分别使用命令-get和-copyToLoca从HDFS上传下载某个文件,
7.删除HDFS上某个文件
8.递归删除某个文件夹下所有文件和目录
9.查看HDFS上某个文件内容
10.统计HDFS上某个文件的大小
四、实验步骤
- 列出某个目录下的文件
hadoop fs -ls /

- 递归列出某目录及文件
hadoop fs -ls -R /
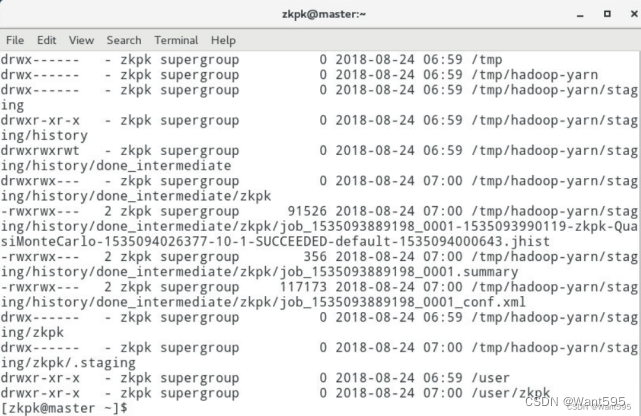
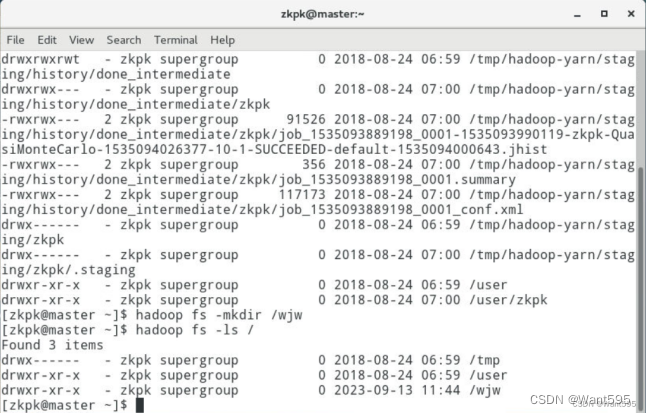
- 创建目录,目录名自拟,查看创建的目录及文件
hadoop fs -mkdir /wjw
- 创建级联目录,递归查看
hadoop fs -mkdir -p /wjw01/wjw02
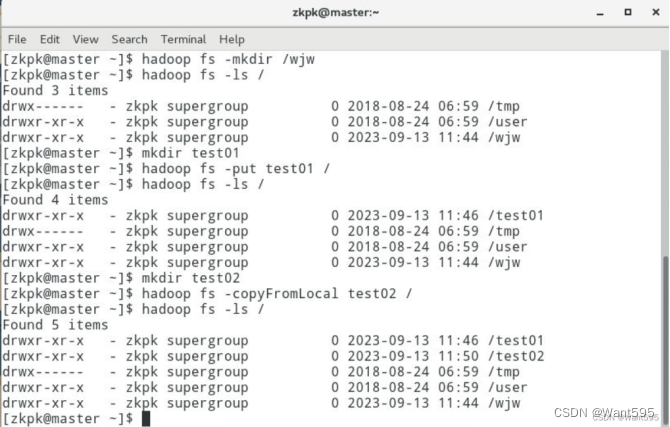
- 在本地新建一个文件,文件名和文件内容自拟,然后分别使用-put命令和-copyFromLocal 命令将该文件上传到HDFS
hadoop fs -put test01 / hadoop fs -copyFromLocal test02 /
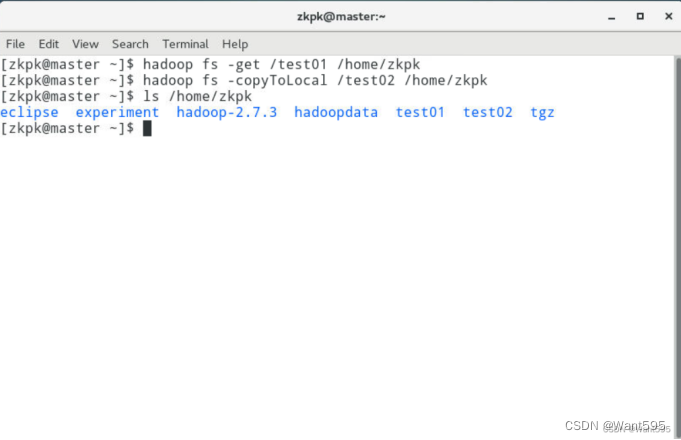
- 分别使用命令-get和-copyToLoca从HDFS上传下载某个文件,
hadoop fs -get /test01 /home/zkpk hadoop fs -copyToLocal /test02/home/zkpk
- 删除HDFS上某个文件
hadoop fs -rm /wjw.txt
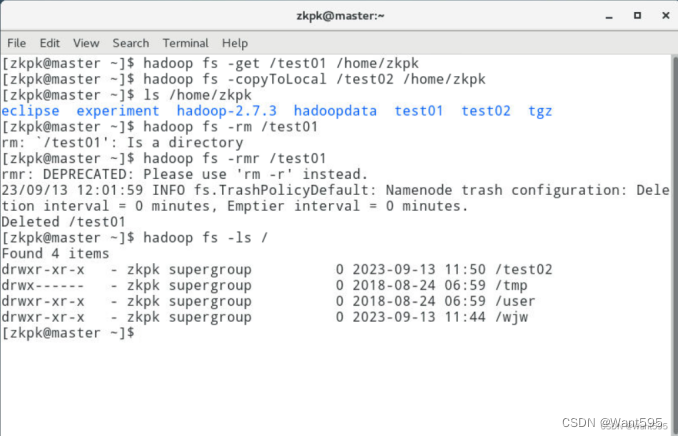
- 递归删除某个文件夹下所有文件和目录
hadoop fs -rmr /wjw01/wjw02
- 查看HDFS上某个文件内容
hadoop fs -cat wjw.txt
- 统计HDFS上某个文件的大小
hadoop fs -du wjw.txt