文/Lindorm AI团队
引言
日前,在加拿大温哥华召开的数据库领域顶会 VLDB 2023 上,来自阿里云瑶池数据库团队的论文《Lindorm TSDB: A Cloud-native Time-series Database for Large-scale Monitoring Systems》,成功入选VLDB Industrial Track(工业赛道)。
论文背景
论文主要针对大规模监控场景下海量时序数据的存储、访问、分析和管理带来的挑战,描述了阿里云多模数据库 Lindorm 带来的一站式解决方案。其中,阿里云数据库团队在架构上大胆探索了数据库集成 AI 引擎的方式,让用户通过低门槛的 SQL 语句就可以对数据库内的时序数据进行训练和推理,并通过结合数据库成熟的对大规模数据的存储、访问和管理的技术,实现了分布式并行、批量和靠近数据的训练和推理优化。
在监控场景中,针对时序数据的智能分析如异常检测、时序预测等是一个普遍需求,现有做法通常需要在外部构建一个数据处理平台,将数据从数据库中拉出来后进行训练,然后将模型进行部署后对外提供时序分析服务。这种做法存在几个问题:
- 开发人员需要熟悉时序数据智能分析的相关算法和模型,编写代码实现模型训练和推理,具备较高的开发成本;
- 需要搭建一个复杂的数据处理平台,包括从数据库中拉取数据的组件、一个能高效处理大规模时序数据的机器学习平台以及对模型进行管理的组件,具备较高的运维成本;
- 从数据库中拉取数据进行模型训练和推理需要耗费大量带宽,并且随着时间推移,当时序数据发生特征变化时,需要频繁重新拉取数据进行模型更新,模型应用的时效性较差。
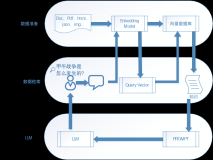
为了解决上述问题,我们在 Lindorm 数据库中集成了 Lindorm ML 组件,负责对时序数据进行 In-DB 的训练和推理。如下图所示,用户可以通过一个 CREATE MODEL 的 SQL 在数据库中创建(训练)一个机器学习模型,然后通过另外一个 SQL 函数使用模型对指定数据进行推理。

由于时序数据的智能分析具有时间线间独立的特点,Lindorm ML 组件利用了 Lindorm TSDB 对时序数据按照时间线维度进行存储的特性以及分布式的组织和管理方式将对应的机器学习模型也进行了分区(对用户透明),从而能够实现时间线维度的计算及分布式并行训练和推理优化。进一步的,在单机节点上,时序分析所需要的预处理和训练、推理等相关的算法被设计实现成 TSDB 流式执行引擎的算子,在时序数据从存储引擎中被扫描出来后就进行计算,再结合查询下推等特性,实现了靠近数据的计算优化,大大减少了数据在数据库内节点间的传输带宽消耗。

由于减少了从数据库中进行数据拉取的开销,通过和外部进行时序分析的实验对比,Lindorm ML 在训练和推理性能上有 2 倍以上的提升。更重要的是,Lindorm ML 内置了一些成熟的时序分析算法,用户直接通过几个 SQL 就能使用这些机器学习算法对自己的数据进行分析,门槛得到极大的下降。

架构再升级!Lindorm AI引擎支持大模型应用构建
随着 ChatGPT 带来的 AI 热潮及对模型即服务(Model as a Service)趋势的拥抱,Lindorm 团队将 Lindorm ML 组件升级成了 AI 引擎,除了对时序数据进行建模分析之外,还支持了预训练 AI 模型在数据库内的灵活导入,用于对数据库内存储的多模数据进行分析、理解和处理,从而对用户提供一站式 AI 数据服务。
结合大语言模型(LLM)的能力在企业内部知识库场景进行检索和问答是目前比较火热的 AI 应用,在这其中,除了 LLM 之外,还有两个比较关键的组件,其一是向量数据库,负责通过向量检索技术实现相似文本检索,为 LLM 补充上下文。还有一个则是对知识库文档进行加工和处理的服务,包括对文档进行预处理、切片及向量化(Embedding)。现有解决方案往往需要开发者基于一些流行框架如 LangChain 等来实现,尽管这些框架已经提供了基础的功能及对一些可选组件或服务的对接封装,仍然不是开箱即用的,直接基于它们来搭建一个知识问答应用是比较难真正落地的。一来这些框架具备一定的上手门槛,开发者首先需要学习框架的使用,并对其提供的功能进行深入对比(比如多种文本切片方法)和调优,这些预置的方法在效果上往往达不到生产落地的要求。此外,开发者还需要解决这个复杂架构中如向量数据库、Embedding服务的部署和运维的问题,以及知识库文档的更新等问题。针对这个场景, Lindorm AI 引擎提供了一站式的解决方案。用户只需要在数据库中存入知识库文档,由数据库自动完成文档的预处理、切片、向量化等过程,通过一个 SQL 函数就能实现针对文档的语义检索,及结合 LLM 进行问答。利用数据库成熟的数据处理能力,在用户看来,只是针对知识库文档建了一个特殊的 AI 驱动的语义索引,索引建好之后就可以进行语义检索及问答,文档的新增、更新、删除这些过程对用户来说都是透明的。作为一个云服务, Lindorm AI 引擎提供的这个解决方案已经在云上业务中落地。
除了私域数据知识问答场景之外,Lindorm AI 引擎还支持一站式多模态检索解决方案,包括通过文本检索图片,以及以图搜图等。和知识问答场景类似,用户不再需要和难以理解的向量以及多个服务打交道,只需要将图片本身(或图片的地址)存储于数据库中,数据库会自动利用 AI 模型的能力对图片进行一站式向量化、存储以及检索,大大简化业务的整体架构,提升开发和运维效率。
结语
从上述知识问答和多模态检索解决方案中可以看到,结合 AI 的能力,从某种意义上,使得数据库对于文本、图像等这类非结构化数据,实现了从简单的“存储和处理”到“理解和应用”的跃迁。在未来,除了数据本身之外,利用 AI 对数据资产进行理解和管理也会是我们继续探索的一个重要方向。正如Lindorm数据库的宗旨是“让数据存得起、看得见、算得好”,我们希望能让更多用户可以更好的用好数据,使得数据价值不断放大。
阿里云Lindorm数据库推出智能问答体验版试用活动啦!
? 秒级开通,仅60元/月。支持用户直接上传知识库文件,便捷构建具备私域知识+LLM的智能问答系统,快来试用吧!
点击链接即刻开启试用~