创建存储组
根据存储模型,我们可以设置相应的存储组。用于创建存储组的SQL语句如下:
IoTDB > set storage group to root.lnIoTDB > set storage group to root.sgcc
因此,我们可以使用上述两条SQL语句创建两个存储组。
值得注意的是,当路径本身或路径的父/子层已经被设置为存储组时,则不允许将路径设置为存储组。例如,设置是不可行的root.ln.wf01存在两个存储组时,作为一个存储组root.ln和root.sgcc。系统会给出相应的错误提示,如下所示:
IoTDB> set storage group to root.ln.wf01Msg: org.apache.iotdb.exception.MetadataErrorException: org.apache.iotdb.exception.PathErrorException: The prefix of root.ln.wf01 has been set to the storage group.
显示存储组
创建存储组后,我们可以使用显示存储组语句来查看所有存储组。SQL语句如下所示:
IoTDB> show storage group
结果如下:

创建时间序列
根据前面选择的存储模型,我们可以在两个存储组中分别创建相应的时间序列。用于创建时间序列的SQL语句如下:
IoTDB > create timeseries root.ln.wf01.wt01.status with datatype=BOOLEAN,encoding=PLAINIoTDB > create timeseries root.ln.wf01.wt01.temperature with datatype=FLOAT,encoding=RLEIoTDB > create timeseries root.ln.wf02.wt02.hardware with datatype=TEXT,encoding=PLAINIoTDB > create timeseries root.ln.wf02.wt02.status with datatype=BOOLEAN,encoding=PLAINIoTDB > create timeseries root.sgcc.wf03.wt01.status with datatype=BOOLEAN,encoding=PLAINIoTDB > create timeseries root.sgcc.wf03.wt01.temperature with datatype=FLOAT,encoding=RLE
值得注意的是,当CRATE TIMESERIES语句中的编码方式与数据类型冲突时,系统会给出相应的错误提示,如下所示:
IoTDB> create timeseries root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=TS_2DIFFerror: encoding TS_2DIFF does not support BOOLEAN
请参考编码用于数据类型和编码之间的对应。
标签和属性管理
我们还可以在创建一个时间序列时添加别名、额外的标记和属性信息。用于创建带有额外标记和属性信息的时间序列的SQL语句扩展如下:
create timeseries root.turbine.d1.s1(temprature) with datatype=FLOAT, encoding=RLE, compression=SNAPPY tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2)
这temprature括号中是传感器的别名s1。所以我们可以用temprature替换s1任何地方。
注意,额外的标记和属性信息的大小不应该超过
tag_attribute_total_size.
tag和attribute之间的唯一区别是我们将在tag上维护一个倒排索引,所以我们可以在show timeseries where子句中使用tag property,如下所示Show Timeseries部分。
更新标签操作
我们可以在创建标签信息后更新它,如下所示:
- 重命名标签/属性键
ALTER timeseries root.turbine.d1.s1 RENAME tag1 TO newTag1
- 重置标签/属性值
ALTER timeseries root.turbine.d1.s1 SET tag1=newV1, attr1=newV1
- 删除现有标签/属性
ALTER timeseries root.turbine.d1.s1 DROP tag1, tag2
- 添加新标签
ALTER timeseries root.turbine.d1.s1 ADD TAGS tag3=v3, tag4=v4
- 添加新属性
ALTER timeseries root.turbine.d1.s1 ADD ATTRIBUTES attr3=v3, attr4=v4
- 向上插入别名、标签和属性
如果别名或键值不存在,请添加别名或新的键值,否则,用新值更新旧值。
ALTER timeseries root.turbine.d1.s1 UPSERT ALIAS=newAlias TAGS(tag3=v3, tag4=v4) ATTRIBUTES(attr3=v3, attr4=v4)
显示时间序列
- 显示时间序列前缀路径?showWhereClause?limitClause?
在显示时间序列、返回时间序列信息后面可以添加三个可选子句
时间序列信息包括:时间序列路径、测量别名、所属存储组、数据类型、编码类型、压缩类型、标签和属性。
示例:
- 显示时间序列
以JSON形式显示所有时间序列信息 - 显示时间序列<
Path>
返回给定<Path>. <Path>必须是前缀路径或带星号的路径或时间序列路径。SQL语句如下:
IoTDB> show timeseries rootIoTDB> show timeseries root.ln
结果分别如下所示:


- 显示时间序列(<
PrefixPath>)?where子句
返回满足where条件并以前缀路径SQL语句开头的所有timeseries信息,如下所示:
show timeseries root.ln where unit=cshow timeseries root.ln where description contains 'test1'
结果分别如下所示:
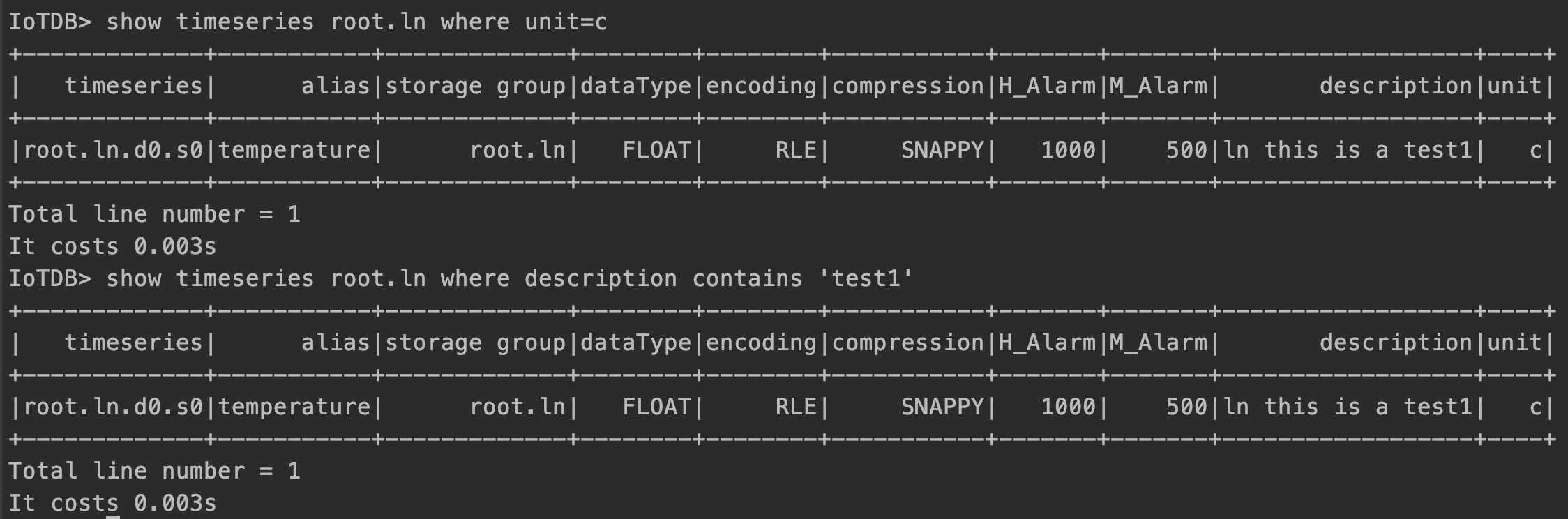
注意,我们只支持where子句中的一个条件。它要么是一个相等的过滤器,要么是一个
contains过滤器。在这两种情况下,where条件中的属性必须是标记。
- 显示时间序列限制整数偏移量整数
返回从偏移量开始的所有时间序列信息,并限制返回的序列数
值得注意的是,当查询的路径不存在时,系统不会返回任何时间序列。

