7、连接 ZK 客户端【zkCli.sh】,观察它下面的目录节点,看 Controller 角色对应的是哪一台节点【get /kafka/controller】
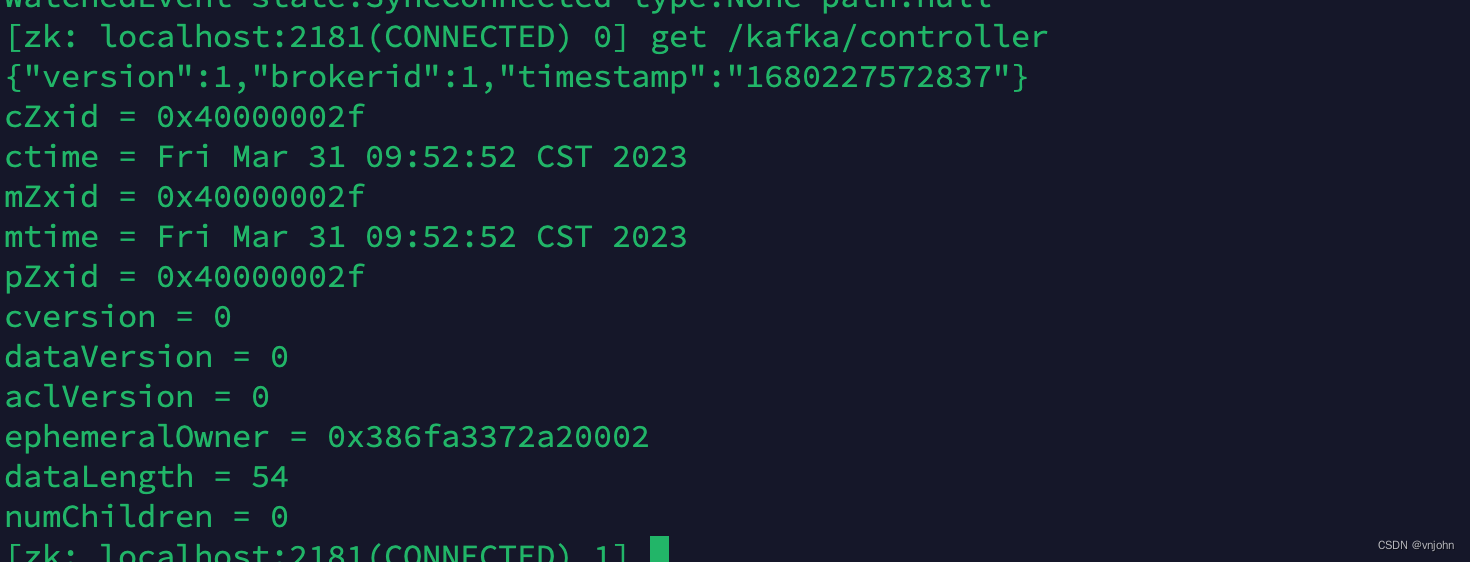
brokerid =1 ,controller 分配给到了 node2 节点!
使用
Kafka 集群搭建完毕,现在是如何通过命令方式操作它了
1、创建 Topic
执行创建 Topic 操作,示例:topic(order-score)下有两个分区,每个分区对应两个副本
[root@node1 bin]# kafka-topics.sh --zookeeper node1:2181/kafka --create --topic order-score --partitions 2 --replication-factor 2 Created topic "order-score".
2、查看所拥有的 Topic
[root@node1 bin]# kafka-topics.sh --zookeeper node1:2181/kafka --list order-score
3、查看指定 Topic 描述信息
[root@node1 bin]# kafka-topics.sh --zookeeper node1:2181/kafka --describe --topic order-score Topic:order-score PartitionCount:2 ReplicationFactor:2 Configs: Topic: order-score Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0 Topic: order-score Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Leader 值是我们配置的 broker.id 值
分区的数量再多,也只是为了增加数据的可靠性,R/W 操作仍然只会发生在主(Leader)分区上
4、创建 consumer
创建一个消费者连接 Kafka 集群,订阅 order-score Topic,并分到 vnjohn 这个 group 组中
kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic order-score --group vnjohn
该窗口会停顿在前台,一直是否有数据到来,比如,通过第五点 往这个 Topic 生产一些数据,它马上就会来响应到来!
5、创建 Producer
创建一个生产者连接 broker 节点拿到元数据信息,为 order-score 这个 topic 分发消息,接着会有输入框等待输入信息,输入/生产什么,上面的消费者就会消费什么
kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic order-score
6、结合第 4、5 点来看下效果
第一种:若只开启了一个消费者,所有的消息只会分发到那个消费者上

第二种:若开启了多个消费者并且在同一个组上,就会均匀分配消息(每一个消费者分配到了不同的分区上)

第三种:若开启了多个消费者但不是在同一个组上,消息是会被重复消费在不同的组中的

最后一种:如果在同一个组中,消费者多于分区的数量,那么多于分区数量的那些消费者是无法消费到数据的,因为 partition:consumer 1:N 是不成立的
前面我们在创建 order-score Topic 时,只为它分配了两个分区,这时我们开启四个消费者同时消费,看看是否有超过两个消费者在进行消费消息?

从图中可以看出,生产者产生的消息只有两个消费者一直在消费,而其他的两个消费者根本没有起作用,这证明了 partition:consumer 1:N 是不成立的 合理性
7、查看消费组 Group 信息
kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --list
[root@node1 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --list vnjohn01 vnjohn02 vnjohn
8、查看指定消费组 Group 信息
kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --describe --group vnjohn
kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --describe --group vnjohn01
kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --describe --group vnjohn02
[root@node1 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --describe --group vnjohn TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID order-score 0 8 8 0 consumer-1-4e2ad0fa-788e-48dd-8831-381f4bc06193 /172.16.249.10 consumer-1 order-score 1 9 9 0 consumer-1-8b056660-9d2f-450a-ac30-5480b72d6dfb /172.16.249.10 consumer-1 [root@node1 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --describe --group vnjohn01 Consumer group 'vnjohn01' has no active members. TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID order-score 1 4 9 5 - - - order-score 0 3 8 5 - - - [root@node1 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --describe --group vnjohn02 Consumer group 'vnjohn02' has no active members. TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID order-score 1 4 9 5 - - - order-score 0 3 8 5 - - -
从控制台输出的偏移量结果来看,group:vnjohn 将所有的消息都处理完了,group:vnjohn01、vnjohn02 两个组都各自还有 5 条数据未处理,因为刚刚产生了 10 条数据,按分区数量来分配,每个分区均匀分配,也就是各自 5 条
元数据
在【架构模型】上提及到了,服务端元数据【broker 节点元数据信息、Controller 信息(ids、broker metadata、topic、partition)】以及 Kafka 内部主题【_consumer_offsets】 ,接下来我们从 ZK 客户端上来对这些信息进行具体的查看!
1、查看 broker 节点信息:ls /kafka/brokers/ids
ls /kafka/brokers/ids [0, 1, 2]
2、查看指定 broker 节点的元数据信息:get /kafka/brokers/ids/0
get /kafka/brokers/ids/0 {"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://node1:9092"],"jmx_port":-1,"host":"node1","timestamp":"1680229446282","port":9092,"version":4}
在配置文件中配置的 listeners 值、端口、host 都存储在这里!
3、获取所有的 Topic:ls /kafka/brokers/topics
ls /kafka/brokers/topics [order-score, __consumer_offsets]
__consumer_offsets 不就出来了嘛!
4、获取 Topic:order-score 下分区信息: ls /kafka/brokers/topics/order-score/partitions
ls /kafka/brokers/topics/order-score/partitions [0, 1]
5、获取 Topic:order-score 下指定的分区信息:get /kafka/brokers/topics/order-score/partitions/0/state
获取 Topic order-score 下分区 0 的状态信息:主分区及活跃分区(isr)
get /kafka/brokers/topics/order-score/partitions/0/state {"controller_epoch":3,"leader":2,"version":1,"leader_epoch":2,"isr":[2,0]}
6、获取内部主题:_consumer_offsets 信息
get /kafka/brokers/topics/__consumer_offsets {"version":1,"partitions":{"45":[0],"34":[1],"12":[0],"8":[2],"19":[1],"23":[2],"4":[1],"40":[1],"15":[0],"11":[2],"9":[0],"44":[2],"33":[0],"22":[1],"26":[2],"37":[1],"13":[1],"46":[1],"24":[0],"35":[2],"16":[1],"5":[2],"10":[1],"48":[0],"21":[0],"43":[1],"32":[2],"49":[1],"6":[0],"36":[0],"1":[1],"39":[0],"17":[2],"25":[1],"14":[2],"47":[2],"31":[1],"42":[0],"0":[0],"20":[2],"27":[0],"2":[2],"38":[2],"18":[0],"30":[0],"7":[1],"29":[2],"41":[2],"3":[0],"28":[1]}}
旧版本中将读取数据的 offset 持久化到 ZK 中,新版本是 Kafka 集群内部通过 Topic 来持久化的
可以看出除了我们自己创建的 Topic 以外,Kafka 还自身创建了一个消费数据时的 Offset Topic,以此来确保读取数据的准确性

拓扑回顾图

- 创建 Topic 会先经过 ZK,再找到 Controller 角色的 Broker,由它来进行创建,
Topic 是横跨集群下所有 Kafka 节点的 - Topic 划分了不同的 Partition,可以为每个 Partition 分配副本数量,Partition 副本是为了保证数据的可靠性,并不会参加 R/W 操作
- Producer 生产的数据会均匀地分配到各个 Partition 中,每一个分区对应一个 Consumer,
可形成 1:1 或 N:1 关系 - 同一个消费组中,消费者是不能重复消费的;不同的消费组,消费者是可以重复消费的
总结
该博文作为专栏【Kafka】第一篇,为大家了整理了各大消息中间件之间的特性以及优劣势,结合 AKF 划分原则对 Kafka 集群、Topic、Partition 作了划分;通过自身理解的【架构模型】为大家提前梳理清楚一些概念以及问题,在 Kafka 中存在的角色作了一些概述;最后,以实践校验真理的唯一准则,搭建了 Kafka 集群以及通过控制台方式整理了一些常用命令以及对前面所描述的一些问题作了验证操作!
若此文有帮助到您,实属开心,博主喜欢用图+理论梳理每一个学习到的知识点,一起开启学习之旅,后续博主会在该专栏【Kafka】中持续更新 Kafka 核心知识、实践问题以及如何避免,最重要的是会包含从源码角度为大家认证此前所梳理的内容,达到融会贯通!
如果觉得博文不错,关注我 vnjohn,后续会有更多实战、源码、架构干货分享!
大家的「关注?? + 点赞? + 收藏?」就是我创作的最大动力!谢谢大家的支持,我们下文见!


