前言
什么是 Kafka?是做什么的,官网定义如下:
Kafka is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
翻译过来,大概意思就是:这是一个实时数据处理系统,可以横向扩展以及高可靠!
实时数据处理,从名字上看,很好理解,就是将数据进行实时处理,在现在流行的微服务开发当中,最常用的实时数据处理平台包括了:RocketMQ、RabbitMQ 等消息中间件.
从网上整理资料加上自身理解,对 Kafka、RocketMQ、RabbitMQ 这三种中间件做一下对比,如下:
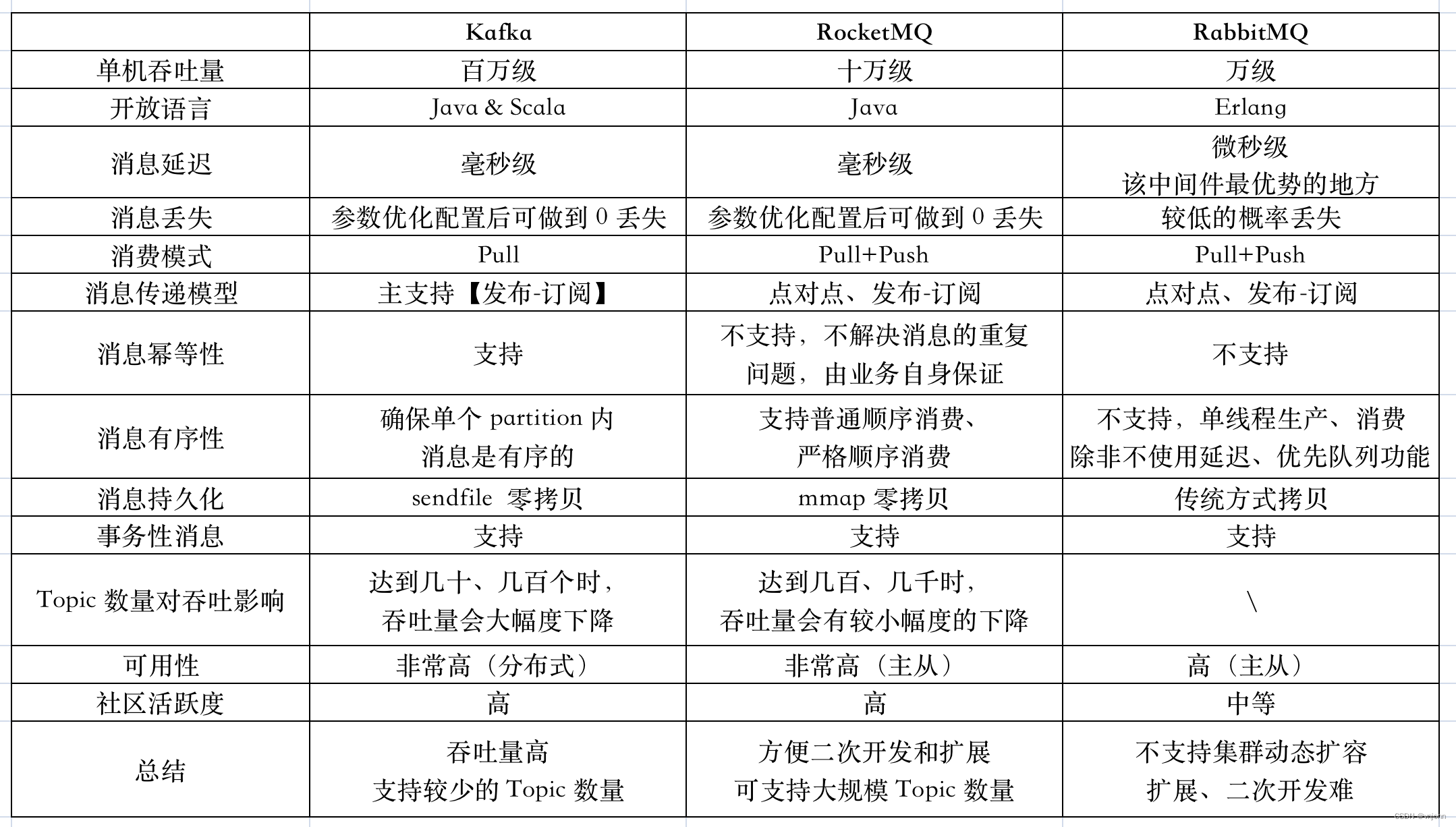
这些中间件,最大的特点主要有两个:
- 服务/业务解耦,中间件与程序无强关联
- 流量削峰,将服务的一部分流量交给中间件去作处理
AKF 划分原则
通过 AKF 划分原则来认识 Kafka
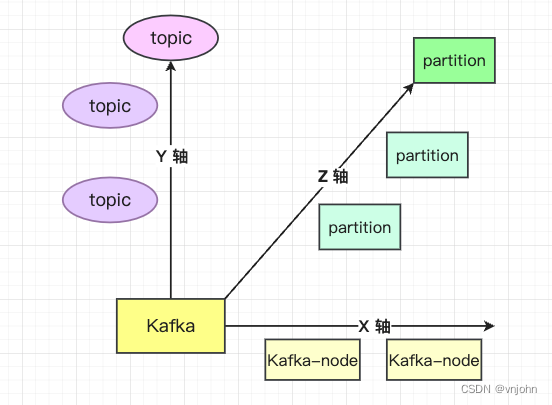
- X 轴:处理的服务节点的单点问题,支持横向扩展、全量镜像
- Y 轴:在 Kafka 服务节点基础上根据业务来划分出不同的 Topic
- Z 轴:基于 Topic 分配出不同的 partition 分区,每个 partition 分散到不同的服务节点上
架构模型
一个好的中间件设计,必然要关注它的架构模型;对于大数据处理下,一个重要、必然的概念:分而治之
- 无关联的数据将其分散到不同的分区上,以追求并发并行的目标,分区外部是无序的
- 有关联的数据,保证按顺序发送到同一个分区上,通过
offset 偏移量来保证分区内部是有序执行的
如下关注它的架构模型图
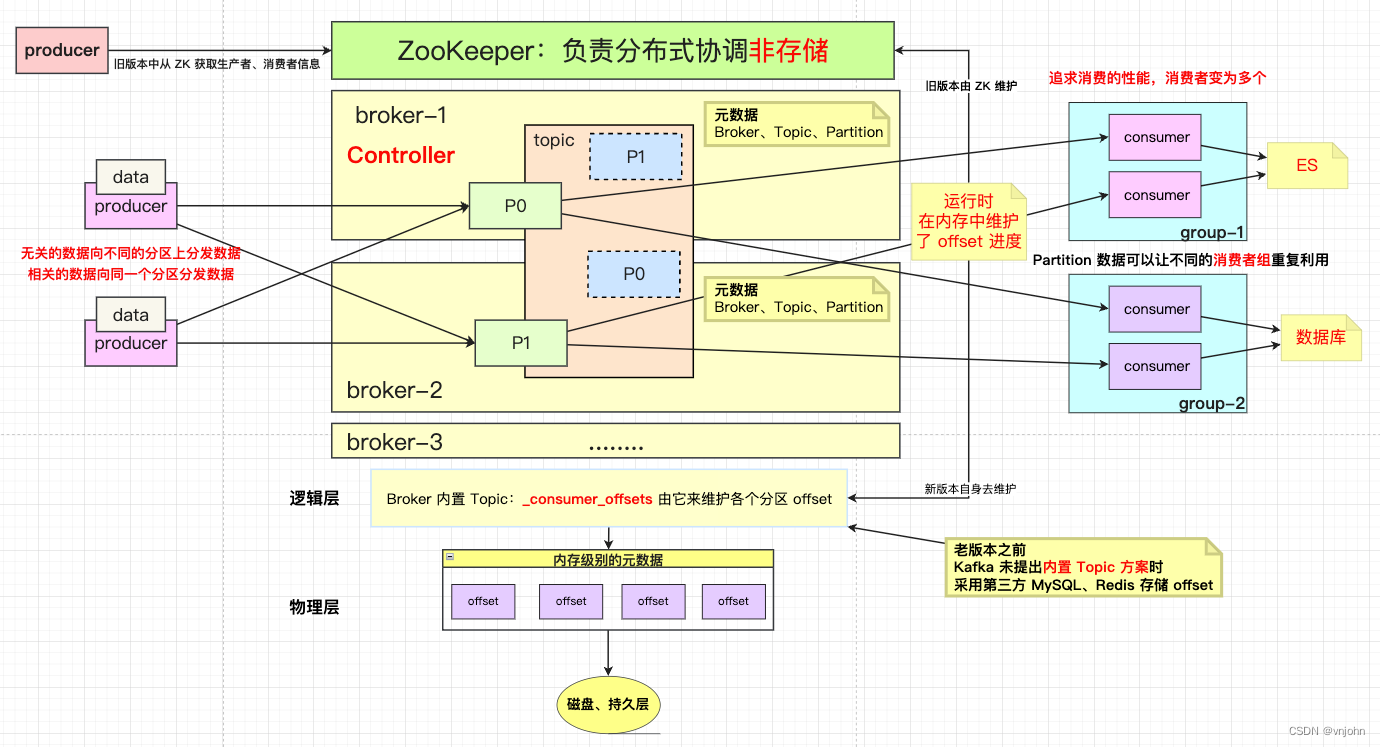
架构模型图简述:
- 在
Kafka 0.9 版本之前,由 ZK 来获取所有的客户端元数据信息(生产者、消费者、偏移量)信息;在Kafka 0.9 版本之后,新版本会把这些信息保存在一个 Kafka 内部主题【_consumer_offsets】内,通过集群中一个名为Coordinator组件进行管理 - 服务端元数据【broker 节点元数据信息、Controller 信息(
ids、broker metadata、topic、partitio)】 仍然是从 ZK 中获取,Controller 会从 ZK 中获取最新的元数据信息缓存在服务节点的内存中;这些信息后面通过使用 Kafka 操作时再来观察是否如此! - 在生产者产生数据时,在并发场景下需要保证一致性(数据从 partition -> Kafka 入地)时,需要 Producer 在锁粒度范围内将数据发送到 broker 中
- Partition、Consumer 关系只有
1:1 或 N:1,而绝不能是1:N关系,主要是一个分区内的数据必须保证顺序的在一个消费者中执行完毕
在实际应用中,建议消费者 consumer 数量与 partition 数量保持一致,若消费者数量多于分区数量的情况下,会出现消费者处于闲置的情况;若分区数量多于消费者数量的话,会出现消费性能不均衡的情况
- 在运行时,内存需要维护 partition 读取数据的 offset,在旧版本中,由 ZK 来负担这一块的业务需求,在新版本未出现自身来确保 Topic 维护 offset 时,而不得已要采用第三方处理的方式来进行过渡【Redis、MySQL等】
- 数据重复利用:Kafka -> Broker -> Partition,保存了来自 Producer 发送的数据,重点是 “数据” 怎么可以重复利用,在使用场景下,先要保证即便为了追求性能,使用多个 Consumer,也应该要注意,不能一个分区被多个消费者去消费【浪费资源】
数据的重复利用是建立在 Group 上的,但是在 Group 内要保证
第四点所描述的
一个分区内的数据不能被多个 consumer 消费,也就是决不能存在 1:N 关系
【问题】: 在 Consumer 消费时,会出现数据重复消费或丢失的问题,围绕的就是 offset 消费的进度【节奏?频率?先后】以下是在消费数据时所遇到的几种情况
异步:5 秒之内,先干活,再持久化 offset,若干活的时候突然宕机了,导致 offset 没被写入,会造成重复消费
同步:业务操作、offset 持久化,虽然安全但会造成性能的下降
没有控制好顺序,offset 持久了,但是业务写失败了
角色概述
Broker:一个 Kafka 节点就是一个 Broker,一个集群由多个 Broker 组成,一个 Broker 可以容纳多个 Topic
Broker 接受来自生产者产生的消息,为消息设置偏移量,提交消息到磁盘持久化
Broker 为消费者提供服务,对读取分区的请求作出响应,返回给消费者在磁盘持久化后的消息
Producer:消息的生产方,即消息的入口
Consumer:消息的消费方,即消息的出口
Topic:消息通过业务划分,生产者向 Broker 发送消息时指定 Topic,消费者读取消息时也要指定 Topic
Partition:Topic 分为多个 Partition,相关的数据放入到一个 Partition 中,无关的数据放入到不同的 Partition 中,消息以追加方式写入到 Partition,后以先进先出的顺序读取
Replication:一个分区存在多个副本,副本作用是备胎 -> 高可用,主分区(Leader)会将数据同步到从分区(Follower)当主分区故障时会选择一个备胎(Follower)上位,成为 Leader
在 Kafka 中,默认副本最大数量是 10 个,且副本的数量不能大于 Broker 数量,Follower、Leader 绝对是在不同的节点上,一台节点对同一个分区也只只可能存放一个副本
Consumer Group:按业务线(开发小组)不同来划分不同的消费组,以促使可以重复消费数据
Offset:偏移量,Kafka 存储文件是按照 offset.kafka,用 offset 作为名字的好处是方便查找!
Kafka 集群搭建
下载 Kafka 版本:2.1.0,准备三台虚拟机节点 -> node1~node3
由于 Kafka 依赖于 ZooKeeper 作分布式协调处理,前置环境要求:Jdk 8、ZooKeeper,博主整理了这两篇文章帮你完成前置环境的准备
分布式组件 ZooKeeper 介绍、术语概述以及集群搭建篇
Kafka 安装包下载地址:https://archive.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgz
安装
将下载好的包放入虚拟机节点目录下,比如:/opt/vnjohn
1、解压安装包:tar -xzf /opt/vnjohn/kafka_2.12-2.1.0.tgz
2、更改名字:mv kafka_2.12-2.1.0 kafka
3、更新 config 目录下 server.properties 文件
# 每台 Kafka 节点配置的都不一样 broker.id=0 # 每台 Kafka 节点要配上自己的 主机:端口号 listeners=PLAINTEXT://node1:9092 # hostname、port 都会广播给 producer、consumer # 如果你没有配置了这个属性【advertised.listeners】的话,则使用 listeners 的值 # 如果 listeners 值也没有配置的话,则使用 java.net.InetAddress.getCanonicalHostName() 返回值 # java.net.InetAddress.getCanonicalHostName() 返回值就是 localhost # advertised.listeners=PLAINTEXT://node-1:9092 # 日志文件存储到什么位置下 log.dirs=/var/vnjohn/kafka # 配置上 ZK 连接信息及目录节点 /kafka zookeeper.connect=node1:2181/kafka,node2:2181/kafka,node3:2181/kafka
4、调整 /etc/profile 配置文件内容【Shift+G 跳转至最后一行】,追加内容如下:
export KAFKA_HOME=/opt/vnjohn/kafka export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin
刷新配置文件:source /etc/profile
若配置文件修改出现问题,导致所有命令都不生效了,运行?:export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin 后,再重新调整配置
若配置没有问题的话,输入 kafka 后 Tab 键会出现如下图:

5、node1 配置好了,同步这段配置给 node2、node3,将 kafka 导出到本地,通过 SFTP 方式传给 node2、node3 虚拟机节点上,最后,修改 server.properties 配置文件即可,如下:
# node2 broker.id=1 listeners=PLAINTEXT://node2:9092
# node3 broker.id=2 listeners=PLAINTEXT://node3:9092
更改【node2、node3】/etc/profile 文件,再刷新配置即可
6、node1~node3 启动 Kafka 之前,先通过后台方式启动 ZK【zkServer.sh start】,然后执行命令:kafka-server-start.sh /opt/vnjohn/kafka/config/server.properties

启动出现错误,告知我们,使用 G1 垃圾回收器时必须开启 -XX:+UnlockExperimentalVMOptions
Kafka 默认采用 G1 垃圾回收器,通过脚本可查看:
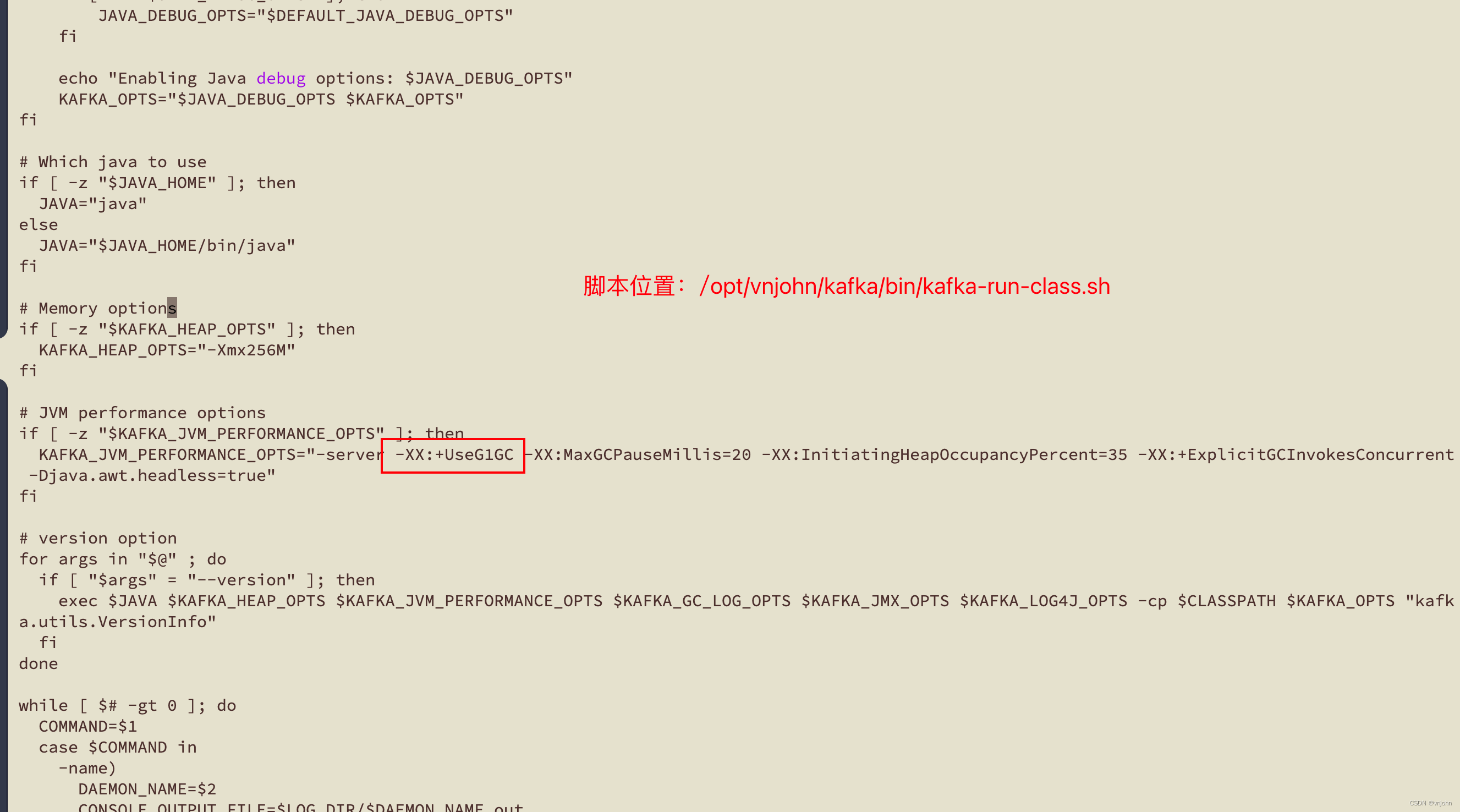
之前在 Windows 搭建的虚拟机节点不会出现这样的错误,在 Mac 搭建出现了这样的问题,猜测可能是内核的原因导致作了这样的限制吧,查阅网上资料,得知,这是与我们的 Jdk 版本相关,它使用了 Graal 作了 JIT 即时编译器
注意:Graal 是一项实验性功能,仅在 Linux-x64 上受支持
所以,我们要启用 Graal 作为 JIT 编译器,VM 参数要追加配置如下:
-XX:+UnlockExperimentalVMOptions
调整 /opt/vnjohn/kafka/bin/kafka-run-class.sh 脚本内容,如下:
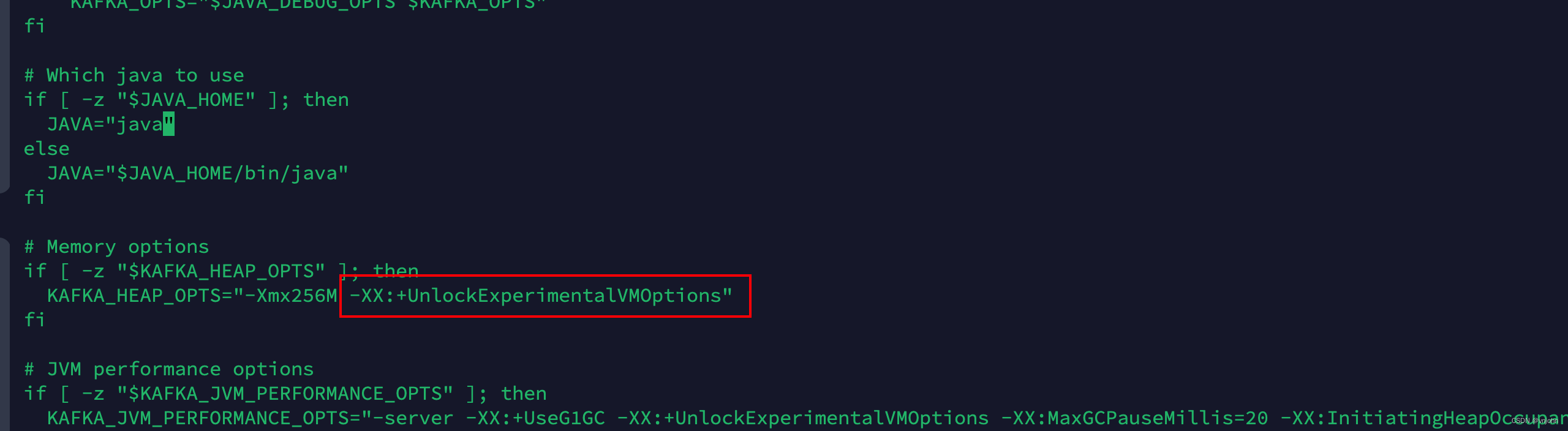
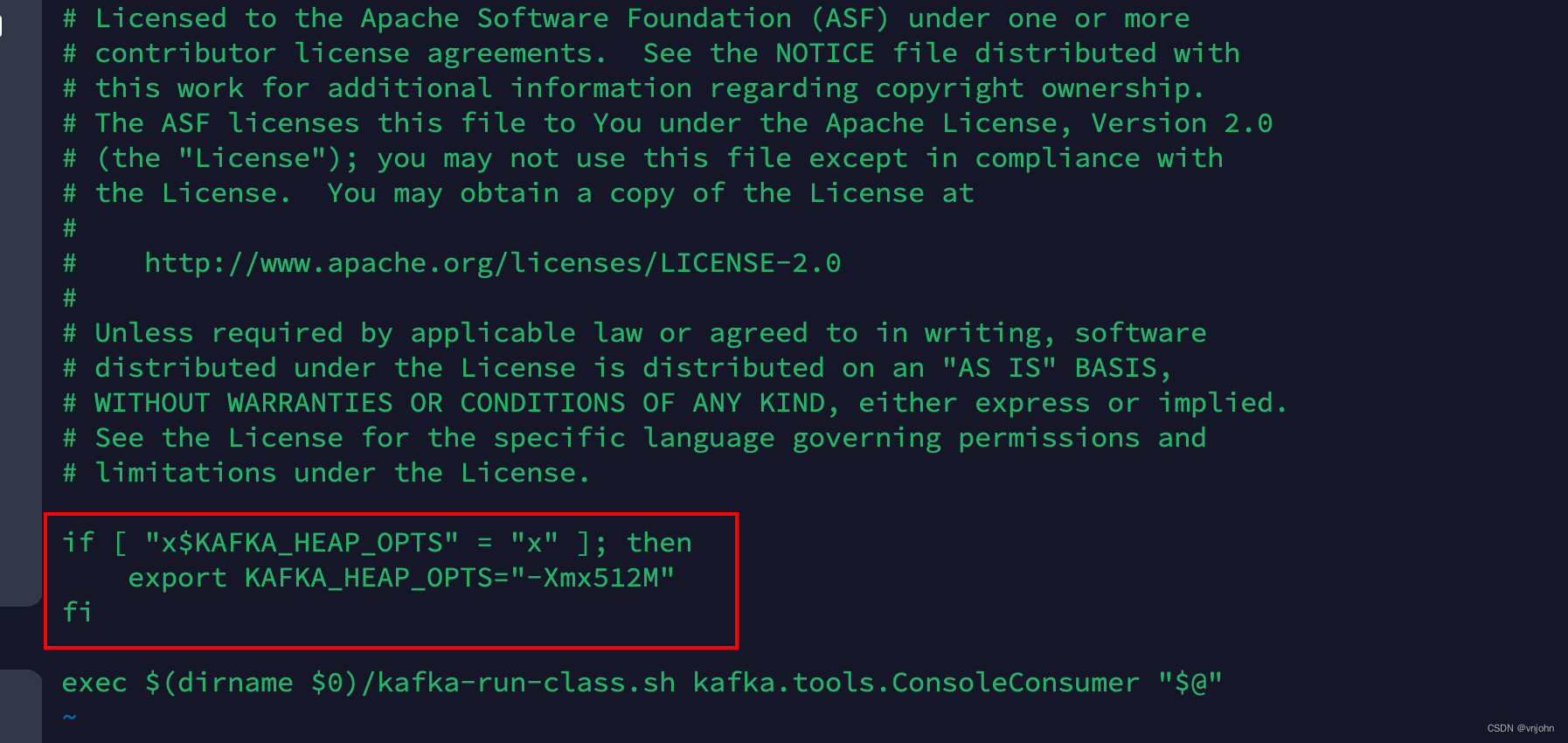
在执行创建生产者、消费者命令【kafka-console-producer.sh、kafka-console-consumer.sh】也会出现这个错误,只需要将一段脚本配置删除,让它默认引用 kafka-run-class.sh 脚本的 JVM 配置即可.
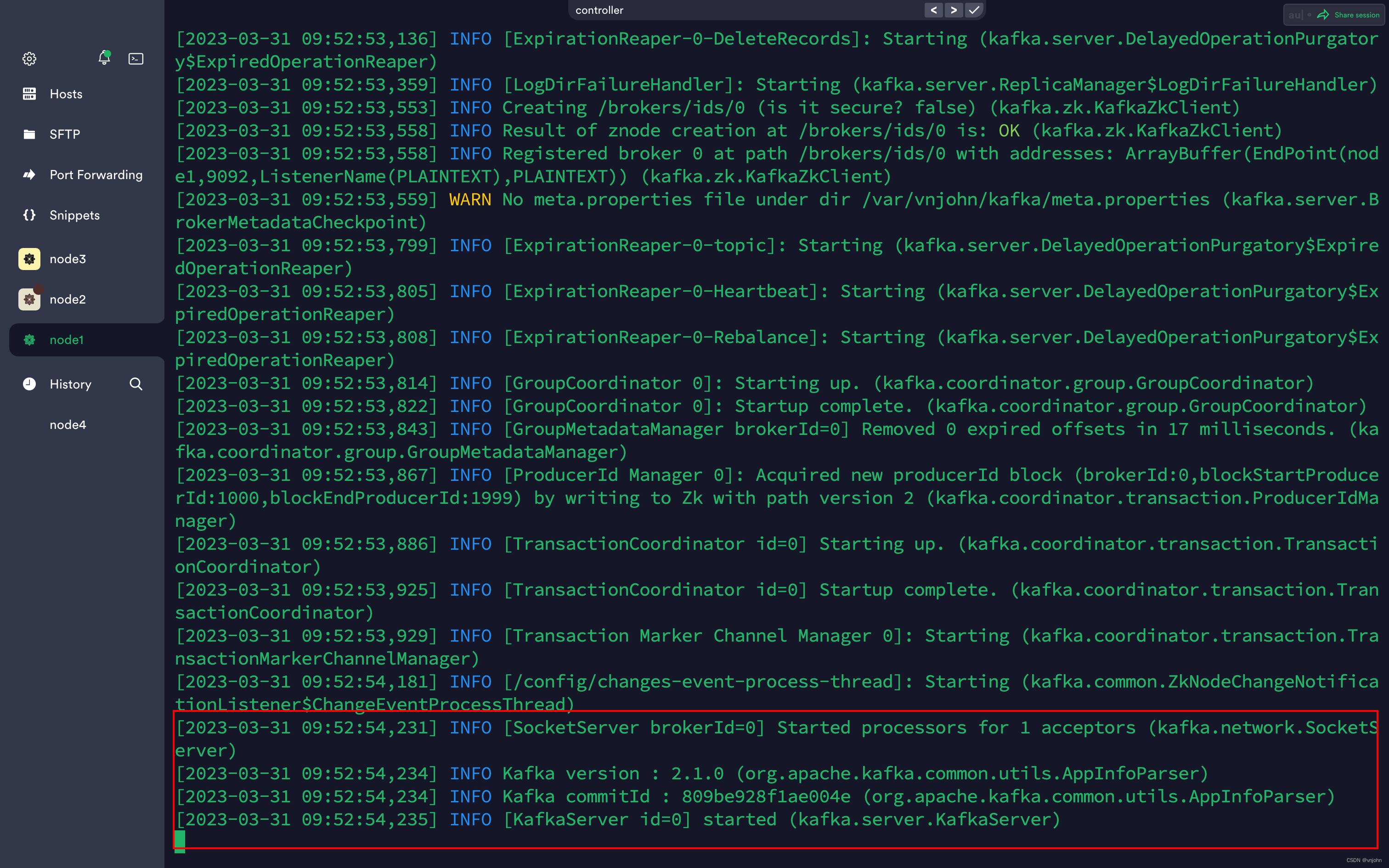
最后,在 node1~node3 执行 kafka-server-start.sh /opt/vnjohn/kafka/config/server.properties 命令启动 Kafka;默认的是在前台运行,会打印日志,后台运行 Kafka 命令:nohup /opt/vnjohn/kafka/bin/kafka-server-start.sh /opt/vnjohn/kafka/config/server.properties >/dev/null 2>&1 &
启动 Kafka 集群成功!!!