引言:
北京时间:2023/4/20/7:48,闹钟6点和6点30,全部错过,根本起不来,可能是因为感冒还没好,睡不够吧!并且今天是星期四,这个星期这是第二篇博客,作为一个日更选手,少些了两篇博客,充分摆烂,但是摆烂具体也是有原因的,星期一的时候莫名高烧,头昏脑涨的感觉,睡了一整天,这种发烧的感觉我已经很久没有体会过了,就算是疫情的时候我也没有体会到,这次发烧的主要原因可能就是星期六打羽毛球的时候把身体打的有点虚脱了,然后又没怎么注意保暖,最终星期天在舍友的一晚上16度空调袭击下导致,以前没感觉生病算什么,但是从这次生病之后,我发现生病真的非常的不友好,但是作为一个人,又怎能不生病呢?生老病死,人之常态,人活着最大的天敌真的就是病痛,在病痛面前一切看起来都是那么的微不足道,今天精神状态良好,就还是犯困,并且可能是因为吃了退烧药的原因,咳嗽严重,别的一切正常,So,让我们抓紧时间来学习一下有关进程信号的知识吧!

回顾共享内存
上篇博客,我们使用各种系统调用接口,构建出了进程间通过共享内存进行通信的场景,明白了共享内存的基本原理等知识,但是共享内存在细节方面还有很多需要我们注意的地方,如:共享内存的大小,注意: 系统默认一个单位共享内存的大小是4096字节(4kb),并且因为创建共享内存的系统调用接口,是允许我们自己设置创建大小的,所以当我们创建的共享内存的大小为4097,超过了4096,那么此时操作系统就会帮我们开辟8kb的空间,但这8kb中只有4097允许正常使用,如果超过了4097依然会报错;如:共享内存的使用,注意: 共享内存的使用,不需要调用任何而外接口,因为进程和共享内存之间已经通过shmat建立了关联,只要任何进程和该共享内存建立了关联,那么它都可以直接看到该共享内存,也就是直接使用该共享内存,不需要任何别的操作,此时该进程就可以对该共享内存进行数据的写入或者是读取,并且明白,因为进程是通过关联对应的共享内存,直接对共享内存进行读写操作,所以它比使用命名管道和匿名管道进行进程间通信的速度是更快的(因为它不需要进行缓冲区的拷贝);如:共享内存的缺陷,注意: 由于进程虚拟地址空间直接和共享内存关联,可以直接对共享内存进行读写操作,所以共享内存没有保护机制,也就是两个进程之间没有读写规则,进程可以随时读取,随时写入,不像是命名管道或者是匿名管道,具有读写规则,一个进程必须写入完成,另一个进程才可以读取(缓冲区起作用),也就是说共享内存是不支持任何的互斥同步机制
总:共享内存适用于大型、高效率的数据共享场景,并且在多进程同时操作同一个数据块,实现进程间的高速交互
浅谈消息队列
感兴趣的同学可以参看该链接:什么是消息队列或消息队列详解
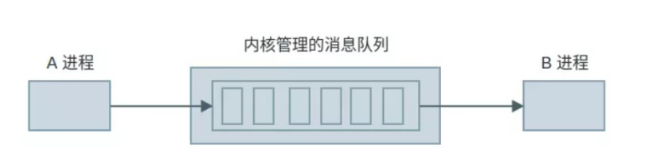
什么是消息队列,首先明白,消息队列是由操作系统维护,然后我们通过特定的接口,让两个进程看到同一消息队列,最后再通过消息队列提供的特定的接口,让进程将自己的数据块可以链接到消息队列中,最后进程再根据特定的编号,获取到对方进程对应的数据块,具体如下图所示:

明白了上述知识,消息队列的基本使用原理我们就知道了,接下来就让我们了解一下有关消息队列的系统调用接口,如下:
创建消息队列:

作用:用于创建或打开一个消息队列,头文件:#include<sys/types.h> #include<sys/ipc.h> #include<sys/msg.h>,调用方式:int msgget(key_t key, int msgflg);参数一眼看过去都不陌生,就是key值和标识符,key值通过ftok()接口获得,msgflg通过宏定义,代表各种权限,也就是创建队列或者打开队列的方式,
删除消息队列方法:
指令:ipcrm -q msqid
接口:msgctl()
具体使用方式如下图所示:

具体调用方式:int msgctl(int msqid, int cmd, struct msqid_ds* buf);一眼看过去和shmctl的调用原理是相同的,第一个参数表示该消息队列的标识符,第二个参数表示控制消息队列的方式 ,第三个参数表示该接口如何对消息队列进行控制(本质上就是使用第三个参数指针,去修改指向结构体中的属性数据)
使用消息队列传输数据:
接口:msgsnd()/msgrcv()

第一个接口,传送数据接口,具体调用方式:int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);第一个参数同理消息队列的标识符,第二个参数表示某个进程需要发送给消息队列的数据块的起始地址,第三个参数表示发送数据块的大小,第四个参数同理,表示的就是以什么方式发送对应的数据块(默认设置为0)
第二个接口,读取数据接口,具体调用方式ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);第一个参数同理为消息队列标识符,第二个参数同理表示读取消息队列中某个数据块的起始地址,第三个参数同理表示需要读取的数据块的大小,第四个参数表示的是消息队列中的数据块的编号,也就是说可以通过这个参数读取消息队列中特定编号的数据,第五个参数同理,表示读取的方式(默认设置为0)
浅谈信号量
在学习什么是信号量之前,我们先了解几个概念,如下:

简单了解了上述的概念之后,此时我们就正式谈谈什么是信号量,首先我们都知道,进程间想要完成通信就一定要构建环境,也就是看到同一份"共享资源",所以在操作系统中是同时存在各种各样的共享资源,此时我们可以将大量的共享资源进行分类,如,那些只能通过互斥访问,也就是只允许一个执行流进行访问的,我们就叫做临界资源,并且把那些访问临界资源的代码称为临界区,所以临界区就是指在系统中一段对共享资源进行访问或修改的代码区域
了解了上述有关临界区的相关知识,此时我们引入一个场景(电影院买票场景),回答一个问题,就是为什么看电影需要买票?
买票的本质是什么?明白了这两个问题,我们就可以很好的搞懂信号量的知识,所以结合日常生活常识,我们知道,买票的本质是为了对座位资源进行预定分配,并且在先到先得的前提下,保证不会多买票给顾客,也就是让座位资源合理分配,那么此时如何可以保证不多买票呢?也就是如何保证资源合理被分配呢?这就涉及到了我们的信号量,明白:信号量本质就是一个非负整数计数器,用于记录资源的可用数量,所以当我们电影院在卖票的时候,只要使用一个计数器(信号量),每卖出一张票,计数器减减1,最终减到0为止,这样不就可以很好的控制座位资源的合理分配了吗?所以明白,信号量本质就是一个用于记录共享资源剩余量的计数器(例:int count = 100;),本质就是为了实现系统内部共享资源分配更加合理和并且提高效率而已,所以间接明白,任何一个执行流,想要访问共享资源,都不能直接访问,必须要先申请信号量资源(也就是买票),让操作系统知道,对应共享资源对应的数据已经被使用或者是正在被使用,从而实现互斥原理,不会造成冲突现象,同理,当你对对应的共享资源访问完毕(电影看完了),此时应该让信号量加1,也就是告诉操作系统,对应的共享资源没有被使用,别的进程可以访问,从而提高进程访问效率
明白了上述知识之后,此时可以知道,想要访问共享资源,首先要申请信号量资源,并且明白,申请信号量资源肯定是以代码的形式,所以明白,当我们使用代码,也就是一定的接口去访问信号量资源,那么此时这个程序,也就是这个进程,也就是系统内部所有的进程如果想要访问信号量资源,那么这些进程肯定是需要先看到信号量资源,此时就会导致一个问题,信号量的本质是为了分配共享资源,那么信号量资源由谁来分配呢?有人可能会想,信号量不是计数器吗?那它不是可以通过加加或者减减来分配吗?这个想法是错误的,因为只要是共享资源,那么此时这个资源的访问是不受互斥等机制控制的,因为互斥等机制本就需要依赖于信号量对资源的控制,所以此时信号量资源是允许同时被进程访问,此时导致信号量资源没有保护机制,所以为了解决这个问题,在进行信号量的设计时,设计师就将信号量设计成具有原子性的资源,这样就可以在信号量保证别的资源被合理分配的同时,实现自己也被合理分配
总: 原子操作是指一个不可被中断或分割的操作,它要么全部完成,要么都不执行,不会因为并发、中断或多任务等条件而被打断或出现竞态条件,信号量的加减操作通常需要保证原子性,以避免多个进程或线程同时对同一信号量进行修改的情况,也就是说,当多个进程或线程同时访问共享资源时,如果对信号量的加减操作不是原子操作的话,就有可能会导致访问顺序混乱,从而引起程序运行错误、数据损坏以及死锁等严重问题,因此对信号量加减操作实现原子性是十分重要的
明白,当我们以后想要让某一个进程访问某一个资源,那么它必须先要访问信号量资源,所以得出结论:如果此时两个进程需要进行通信,以前我们都知道,它们肯定是需要先看到同一份资源,然后才可以进行通信,但是当我们知道了信号量的知识之后,此时就明白,如果想要让不同的进程同时访问同一个资源,那么此时这两个进程首先都需要看到同一份信号量资源,只要看到了同一份信号量资源,它们才有可能看到同一份共享资源
明白了上述知识之后,此时我们就来看一下有关信号量使用的接口,如下:
创建一个信号量:semget()
使用说明如下:

头文件:#include<sys/types.h>/#include<sys/ipc.h>/#include<sys/sem.h>,调用方式:int semget(key_t key,int nsems,int semflg);第一个参数同理是一个信号量标识符,第二个参数此时表示的是创建信号量的个数,第三个参数同理是一个位图结构,表示的就是创建该信号量的方式和权限
删除信号量:
指令:ipcs -s 查看当前所有的信号量
指令:ipcrm -s semid
接口:semctl()
具体使用方式如下:

第一个参数semid,同理表示的就是对应信号量的标识符,第二个参数表示的是对创建出来的多个信号量编号之后,我具体要控制的某一个已经编号的信号量,第三个参数同理表示semctl接口需要执行的操作类型,也就是功能的选择,想要使用该接口获取到信号量的什么部分,此时就可以通过该接口控制
信号量加减:
接口:semop()
使用说明如下:

semop是用于操作信号量的系统调用函数之一,它可以实现对信号量进行P、V操作,从而解决多进程或多线程之间的互斥和同步问题,调用方式:int semop(int semid, struct sembuf *sops, unsigned nsops); 第一个参数semid: 要操作的信号量标识符,由semget函数返回,第二个参数sops: 一个指向sembuf结构体数组的指针,表示要对哪些信号量进行操作,sembuf结构体包括三个成员变量,分别是:
sem_num:要操作的信号量在信号量集合中的下标(从0开始)
sem_op:对信号量执行的操作,可以是负值、零或正值。其中,负值代表P操作(也就是申请信号量资源)、正值代表V操(也就是归还信号量资源))、零代表无操作
sem_flg:控制操作行为的标志,默认为SEM_UNDO表示在进程异常终止时撤销未完成的操作,还可以使用IPC_NOWAIT表示非阻塞操作等
第三个参数nsops: 表示要执行操作的sembuf结构体的数量,也就是表示要操作的信号量的数量
总: 具体来说,当一个进程需要访问共享资源时,它会调用semop函数执行P操作,该操作会将信号量的值减1,如果值小于0,则当前进程会被阻塞,直到有其他进程执行V操作使信号量的值增加为止,而当一个进程释放了共享资源时,它会调用semop函数执行V操作,该操作会将信号量的值加1,同时唤醒等待P操作的进程,因此,semop函数可以实现多个进程之间对共享资源的互斥访问(简单理解就是对一个临界资源进行独立使用,吃独食),从而协调它们的行为,避免出现数据竞争或其他并发问题。
系统内部如何对IPC进行管理
通过对上篇博客共享内存有关的知识,进而我们可以推出,系统无论是对消息队列,还是信号量,本质都和共享内存一样,通过先描述,再组织的方式进行管理,也就是构建出一个一个的结构体,最后对结构体进行增删查改,如shmctl()、msgctl()、semctl()接口一样,具体如下图所示:

如上图所示,结构体中都包括了IPC对象的基本属性和信息,所以如果某一个进程想要使用上述的IPC对象进行进程间通信或者访问共享资源,那么此时就可以让该进程通过特定的接口(shmctl()、msgctl()、semctl())去访问这些结构体,进而来查询或修改IPC对象的属性,最后达到特定的目的,具体原理如下图所示: