免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector

大家都在讨论大模型,似乎什么都可以与大模型结合,可当初学者也想上手时,却面临令人头大的词汇,Prompt、Embedding、Fine-tuning,怎么办呢?别担心,本文就用一种有趣的方式让大家认识它们。
首先让我们先了解一下作为人类是如何去使用大模型的。我们可以把大模型当做一个对语言有着出色理解能力的人,我们要做的就是通过文本的输入,让大模型理解我们希望他做什么事情。那么学会向大模型提问,就变成了用好大模型最重要的事情,甚至可以说使用大模型的过程就是向大模型提问的过程。
那么有哪些概念需要我们了解呢?
Prompt
是输入给大模型的文本,用来提示或引导大模型给出符合预期的输出。我们向大模型提问的文本就是提示词,而大模型在理解了我们的提示词后在提示词的下面会给出对应的回答。
Prompt = 提示词 = 人与大模型交互的媒介
打个比方,假如我们是产品经理,大模型是一名研发工程师的话,那么提示词就是需求,产品经理在提需求的时候,需要在需求里面包含背景说明、需求说明、版本要求、方案建议等信息,只有把需求描述得足够清晰,工程师才能够按照需求输出符合要求的代码,提示词就相当于人向大模型提需求时的需求文档。

Token
我们可以经常在大模型的计费说明中看到Token这个词,Token是大模型处理的最小单元,比如英文单词或者汉字。

Token长度 = 与大模型交互时使用的单词、汉字数
不同的人表达同一件事情时,有的人言简意赅几句话就能把事情说得明明白白,而有的人较啰嗦,那么明显啰嗦的人在描述这件事情上消耗的Token就比前面那个人多了很多。
Emdedding
是将段落文本编码成固定维度的向量,便于进行语义相似度的比较。
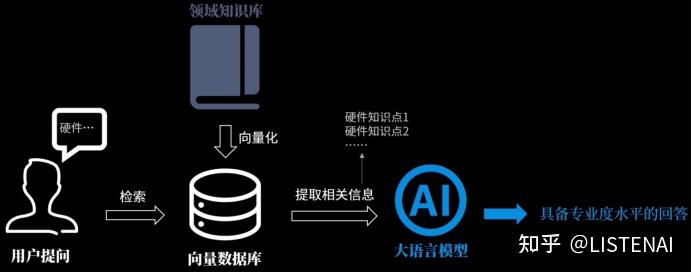
我们可以理解成把知识数据向量化成一个数据库,是为了方便检索,这让用户在提问的时候,我们就可以根据用户的提问内容,在数据库中提取相关度比较高的材料,一起给到大模型,这样大模型就能用这些专业的知识做出更加具备专业水平的回答了。

打个比方,Emdedding就像是当一个项目启动时,项目经理把待完成需求所依据的额外相关材料先整理好,提取重点后放在附件中给到研发工程师,便于研发工程师高效的输出符合预期的东西。
Fine-Tune
在已经训练好的模型基础上进一步调整模型的过程吗,是一种使用高质量数据对模型参数进行微调的知识迁移技术,目的是让模型更匹配对特定任务的理解。

我们可以把大模型类比为公司的研发人员,根据需求生产出对应的产品,而每个研发人员的开发经验都有所不同,输出的代码风格质量也不一样。这就像每个大模型背后使用的训练数据和方法不一样,当面对一样的问题时,做出的回答也会有所差异。那么如何让研发人员输出的代码符合公司的要求呢?答案就是进行培训,由入职导师对研发人员进行代码规范,以及其他需要遵循规则的培训,让他们直接把这些规则记住,这样子他们在做项目开发的时候,就可以直接输出符合规范的产物了。这里的培训类似于大模型的Fine-Tuning,经过Fine-Tuning这个二次训练,大模型更加清楚的知道我们对它输出内容的要求,也就可以输出更加让我们满意的回答了。
把Promp、Token、Emdedding、Fine-Tuning这些大模型词汇串起来,看看用到这些技术的大模型就可以实现下图所示的应用场景。 在下图这个例子中,我们要把一个设备使用手册做成支持大模型问答的应用,这样当我们在使用产品过程中有疑问时,就不需要自己去翻厚厚的说明书了,而是可以直接向大模型提问。
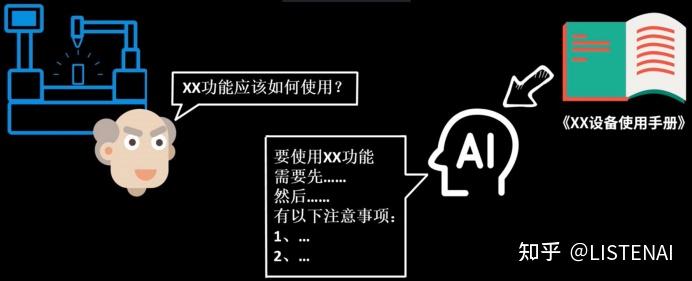
问题来了:
如何让大模型学会这本厚厚的说明书,然后来回答我们的问题呢?
首先我们可以通过Emdedding将这本说明书的文本内容向量化为一个数据库,当用户提问的时候,就可以通过提问的内容在这个数据库中检索出相关的内容,然后跟用户的提问一起组合成完整的Prompt给到我们的语言大模型去处理。根据前面文档的讲解,我们也知道提交给大模型的Prompt内容越多,消耗的token也就越多。而刚才把说明书的内容向量化,并支持相关性线索并提取出来作为problem的过程就是Emdedding。当我们把用户跟这个设备相关的问题提交给大模型时,大模型已经可以给出对应的答案了。
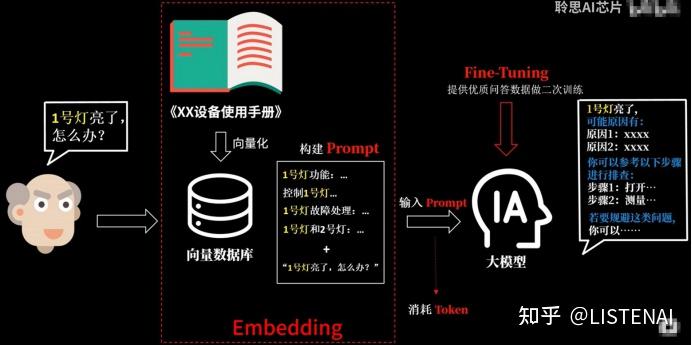
但假如在使用的过程中,我们希望大模型给出的回答可以更加贴合设备问题排查的格式,这时候我们就可以使用微调的技术,通过一些优质的问答数据对大模型进行训练微调,使他的回答更加符合我们的期望。
免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector
